 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Quantum Error Mitigation with Neighbor-Informed Learning
Dec 14, 2025Noise in quantum hardware is the primary obstacle to realizing the transformative potential of quantum computing. Quantum error mitigation (QEM) offers a promising pathway to enhance computational accuracy on near-term devices, yet existing methods face a difficult trade-off between performance, resource overhead, and theoretical guarantees. In this work, we introduce neighbor-informed learning (NIL), a versatile and scalable QEM framework that unifies and strengthens existing methods such as zero-noise extrapolation (ZNE) and probabilistic error cancellation (PEC), while offering improved flexibility, accuracy, efficiency, and robustness. NIL learns to predict the ideal output of a target quantum circuit from the noisy outputs of its structurally related ``neighbor'' circuits. A key innovation is our 2-design training method, which generates training data for our machine learning model. In contrast to conventional learning-based QEM protocols that create training circuits by replacing non-Clifford gates with uniformly random Clifford gates, our approach achieves higher accuracy and efficiency, as demonstrated by both theoretical analysis and numerical simulation. Furthermore, we prove that the required size of the training set scales only \emph{logarithmically} with the total number of neighbor circuits, enabling NIL to be applied to problems involving large-scale quantum circuits. Our work establishes a theoretically grounded and practically efficient framework for QEM, paving a viable path toward achieving quantum advantage on noisy hardware.
Quantum Maximum Entropy Inference and Hamiltonian Learning
Jul 16, 2024Maximum entropy inference and learning of graphical models are pivotal tasks in learning theory and optimization. This work extends algorithms for these problems, including generalized iterative scaling (GIS) and gradient descent (GD), to the quantum realm. While the generalization, known as quantum iterative scaling (QIS), is straightforward, the key challenge lies in the non-commutative nature of quantum problem instances, rendering the convergence rate analysis significantly more challenging than the classical case. Our principal technical contribution centers on a rigorous analysis of the convergence rates, involving the establishment of both lower and upper bounds on the spectral radius of the Jacobian matrix for each iteration of these algorithms. Furthermore, we explore quasi-Newton methods to enhance the performance of QIS and GD. Specifically, we propose using Anderson mixing and the L-BFGS method for QIS and GD, respectively. These quasi-Newton techniques exhibit remarkable efficiency gains, resulting in orders of magnitude improvements in performance. As an application, our algorithms provide a viable approach to designing Hamiltonian learning algorithms.
Logarithmic-Regret Quantum Learning Algorithms for Zero-Sum Games
Apr 27, 2023

We propose the first online quantum algorithm for zero-sum games with $\tilde O(1)$ regret under the game setting. Moreover, our quantum algorithm computes an $\varepsilon$-approximate Nash equilibrium of an $m \times n$ matrix zero-sum game in quantum time $\tilde O(\sqrt{m+n}/\varepsilon^{2.5})$, yielding a quadratic improvement over classical algorithms in terms of $m, n$. Our algorithm uses standard quantum inputs and generates classical outputs with succinct descriptions, facilitating end-to-end applications. As an application, we obtain a fast quantum linear programming solver. Technically, our online quantum algorithm "quantizes" classical algorithms based on the optimistic multiplicative weight update method. At the heart of our algorithm is a fast quantum multi-sampling procedure for the Gibbs sampling problem, which may be of independent interest.
A Provably Efficient Algorithm for Linear Markov Decision Process with Low Switching Cost
Jan 02, 2021
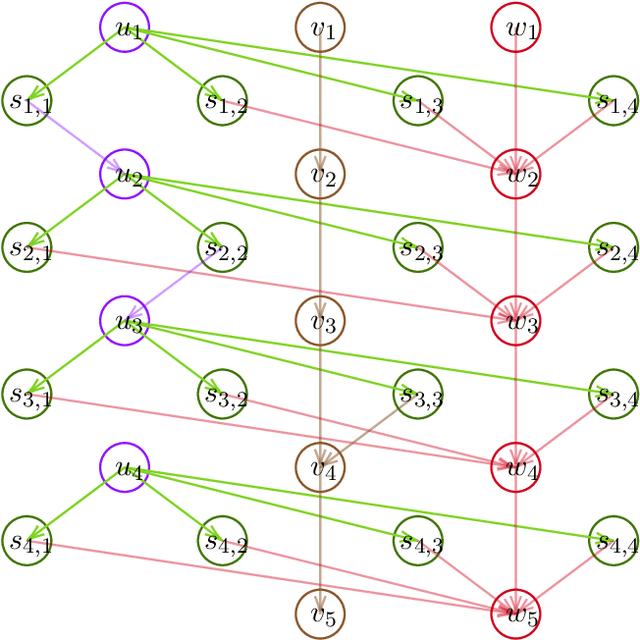
Many real-world applications, such as those in medical domains, recommendation systems, etc, can be formulated as large state space reinforcement learning problems with only a small budget of the number of policy changes, i.e., low switching cost. This paper focuses on the linear Markov Decision Process (MDP) recently studied in [Yang et al 2019, Jin et al 2020] where the linear function approximation is used for generalization on the large state space. We present the first algorithm for linear MDP with a low switching cost. Our algorithm achieves an $\widetilde{O}\left(\sqrt{d^3H^4K}\right)$ regret bound with a near-optimal $O\left(d H\log K\right)$ global switching cost where $d$ is the feature dimension, $H$ is the planning horizon and $K$ is the number of episodes the agent plays. Our regret bound matches the best existing polynomial algorithm by [Jin et al 2020] and our switching cost is exponentially smaller than theirs. When specialized to tabular MDP, our switching cost bound improves those in [Bai et al 2019, Zhang et al 20020]. We complement our positive result with an $\Omega\left(dH/\log d\right)$ global switching cost lower bound for any no-regret algorithm.