 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneAligner: Zero-shot Cross-lingual Transfer with One Rich-Resource Language Pair for Low-Resource Sentence Retrieval
May 17, 2022
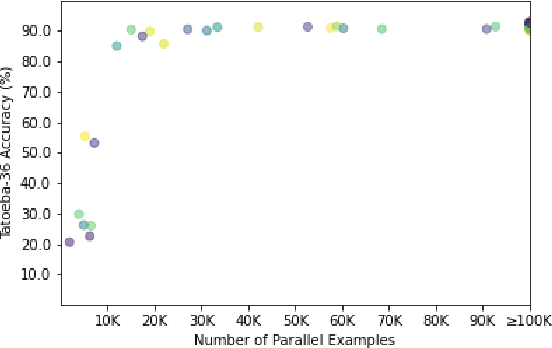
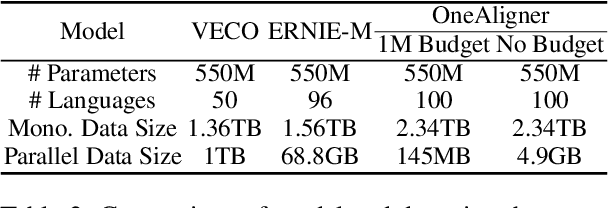
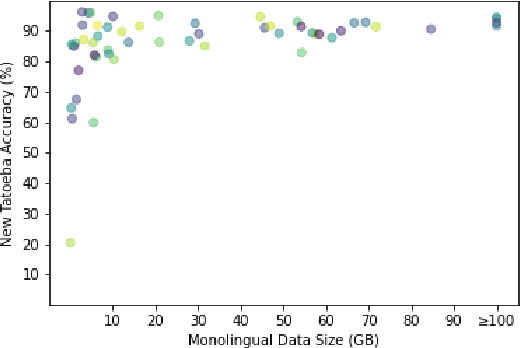
Aligning parallel sentences in multilingual corpora is essential to curating data for downstream applications such as Machine Translation. In this work, we present OneAligner, an alignment model specially designed for sentence retrieval tasks. This model is able to train on only one language pair and transfers, in a cross-lingual fashion, to low-resource language pairs with negligible degradation in performance. When trained with all language pairs of a large-scale parallel multilingual corpus (OPUS-100), this model achieves the state-of-the-art result on the Tateoba dataset, outperforming an equally-sized previous model by 8.0 points in accuracy while using less than 0.6% of their parallel data. When finetuned on a single rich-resource language pair, be it English-centered or not, our model is able to match the performance of the ones finetuned on all language pairs under the same data budget with less than 2.0 points decrease in accuracy. Furthermore, with the same setup, scaling up the number of rich-resource language pairs monotonically improves the performance, reaching a minimum of 0.4 points discrepancy in accuracy, making it less mandatory to collect any low-resource parallel data. Finally, we conclude through empirical results and analyses that the performance of the sentence alignment task depends mostly on the monolingual and parallel data size, up to a certain size threshold, rather than on what language pairs are used for training or evaluation.
MixQG: Neural Question Generation with Mixed Answer Types
Oct 15, 2021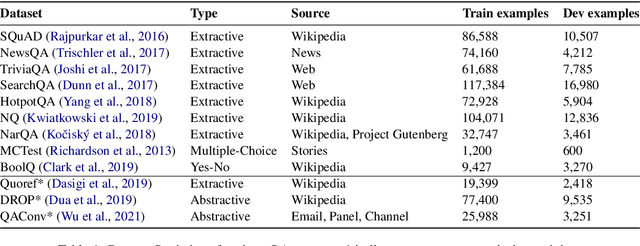
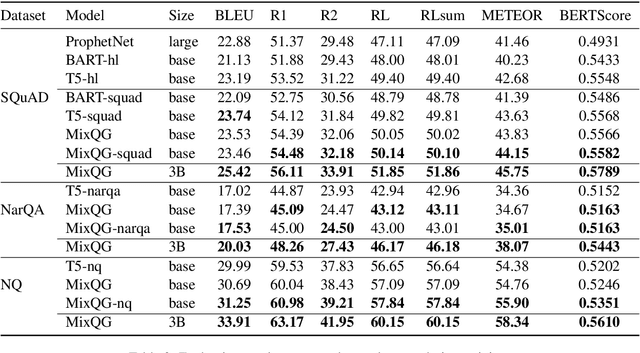


Asking good questions is an essential ability for both human and machine intelligence. However, existing neural question generation approaches mainly focus on the short factoid type of answers. In this paper, we propose a neural question generator, MixQG, to bridge this gap. We combine 9 question answering datasets with diverse answer types, including yes/no, multiple-choice, extractive, and abstractive answers, to train a single generative model. We show with empirical results that our model outperforms existing work in both seen and unseen domains and can generate questions with different cognitive levels when conditioned on different answer types. Our code is released and well-integrated with the Huggingface library to facilitate various downstream applications.
Unsupervised Paraphrase Generation via Dynamic Blocking
Oct 24, 2020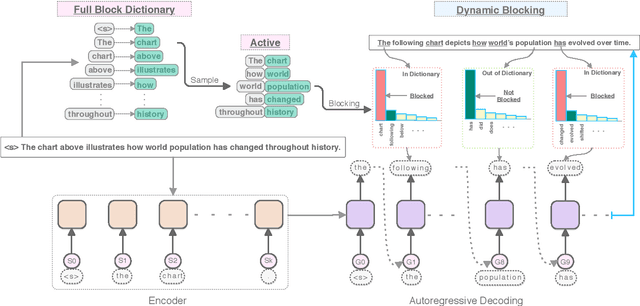
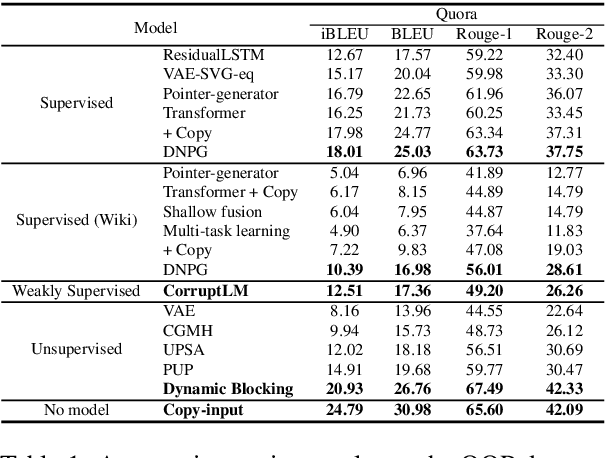
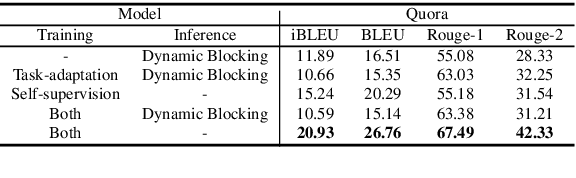
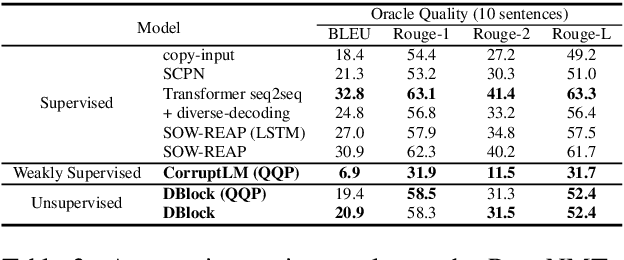
We propose Dynamic Blocking, a decoding algorithm which enables large-scale pretrained autoregressive models (such as BART, T5, GPT-2 and XLNet) to generate high-quality paraphrases in an unsupervised setting. In order to obtain an alternative surface form, whenever the language model emits a token that is present in the source sequence, we prevent the model from generating the subsequent source token for the next time step. We show that our approach achieves state-of-the-art results on benchmark datasets when compared to previous unsupervised approaches, and is even comparable with strong supervised, in-domain models. We also propose a new automatic metric based on self-BLEU and BERTscore which not only discourages the model from copying the input through, but also evaluates text similarity based on distributed representations, hence avoiding reliance on exact keyword matching. In addition, we demonstrate that our model generalizes across languages without any additional training.
CoCo: Controllable Counterfactuals for Evaluating Dialogue State Trackers
Oct 24, 2020

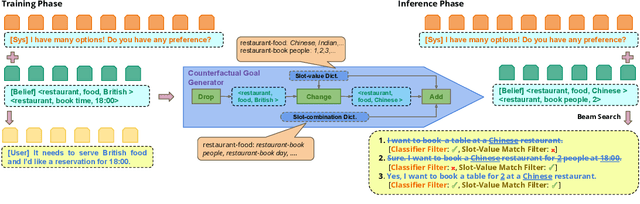
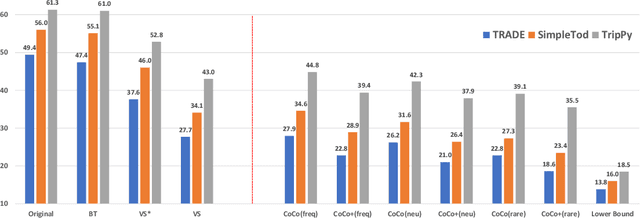
Dialogue state trackers have made significant progress on benchmark datasets, but their generalization capability to novel and realistic scenarios beyond the held-out conversations is less understood. We propose controllable counterfactuals (CoCo) to bridge this gap and evaluate dialogue state tracking (DST) models on novel scenarios, i.e., would the system successfully tackle the request if the user responded differently but still consistently with the dialogue flow? CoCo leverages turn-level belief states as counterfactual conditionals to produce novel conversation scenarios in two steps: (i) counterfactual goal generation at turn-level by dropping and adding slots followed by replacing slot values, (ii) counterfactual conversation generation that is conditioned on (i) and consistent with the dialogue flow. Evaluating state-of-the-art DST models on MultiWOZ dataset with CoCo-generated counterfactuals results in a significant performance drop of up to 30.8% (from 49.4% to 18.6%) in absolute joint goal accuracy. In comparison, widely used techniques like paraphrasing only affect the accuracy by at most 2%. Human evaluations show that CoCo-generated conversations perfectly reflect the underlying user goal with more than 95% accuracy and are as human-like as the original conversations, further strengthening its reliability and promise to be adopted as part of the robustness evaluation of DST models.
Char2Subword: Extending the Subword Embedding Space from Pre-trained Models Using Robust Character Compositionality
Oct 24, 2020

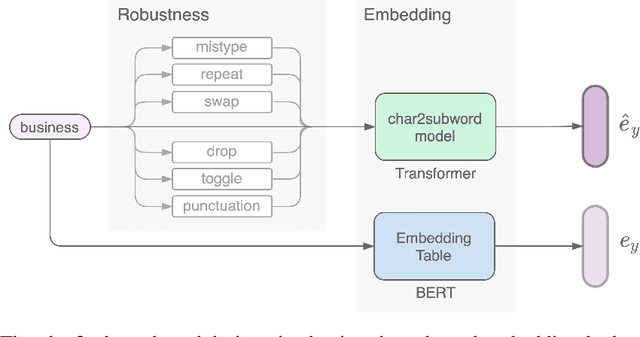
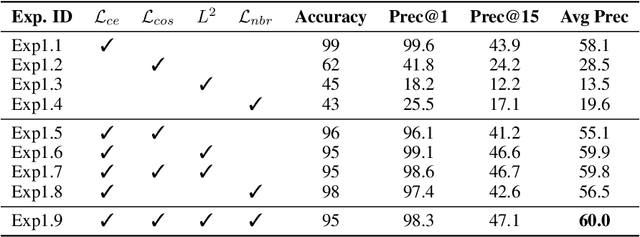
Byte-pair encoding (BPE) is a ubiquitous algorithm in the subword tokenization process of language models. BPE provides multiple benefits, such as handling the out-of-vocabulary problem and reducing vocabulary sparsity. However, this process is defined from the pre-training data statistics, making the tokenization on different domains susceptible to infrequent spelling sequences (e.g., misspellings as in social media or character-level adversarial attacks). On the other hand, pure character-level models, though robust to misspellings, often lead to unreasonably large sequence lengths and make it harder for the model to learn meaningful contiguous characters. To alleviate these challenges, we propose a character-based subword transformer module (char2subword) that learns the subword embedding table in pre-trained models like BERT. Our char2subword module builds representations from characters out of the subword vocabulary, and it can be used as a drop-in replacement of the subword embedding table. The module is robust to character-level alterations such as misspellings, word inflection, casing, and punctuation. We integrate it further with BERT through pre-training while keeping BERT transformer parameters fixed. We show our method's effectiveness by outperforming a vanilla multilingual BERT on the linguistic code-switching evaluation (LinCE) benchmark.
Explaining and Improving Model Behavior with k Nearest Neighbor Representations
Oct 18, 2020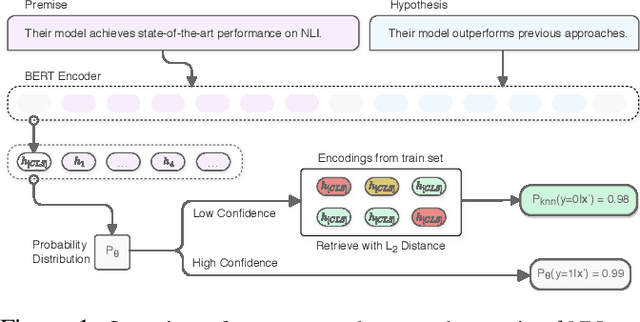



Interpretability techniques in NLP have mainly focused on understanding individual predictions using attention visualization or gradient-based saliency maps over tokens. We propose using k nearest neighbor (kNN) representations to identify training examples responsible for a model's predictions and obtain a corpus-level understanding of the model's behavior. Apart from interpretability, we show that kNN representations are effective at uncovering learned spurious associations, identifying mislabeled examples, and improving the fine-tuned model's performance. We focus on Natural Language Inference (NLI) as a case study and experiment with multiple datasets. Our method deploys backoff to kNN for BERT and RoBERTa on examples with low model confidence without any update to the model parameters. Our results indicate that the kNN approach makes the finetuned model more robust to adversarial inputs.
AvgOut: A Simple Output-Probability Measure to Eliminate Dull Responses
Jan 15, 2020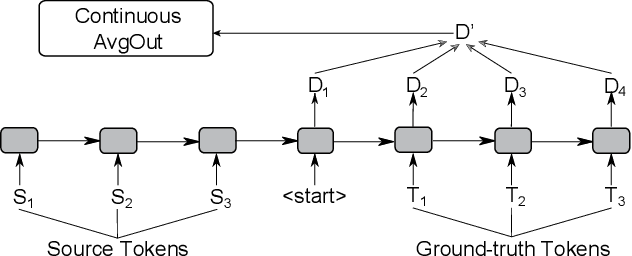
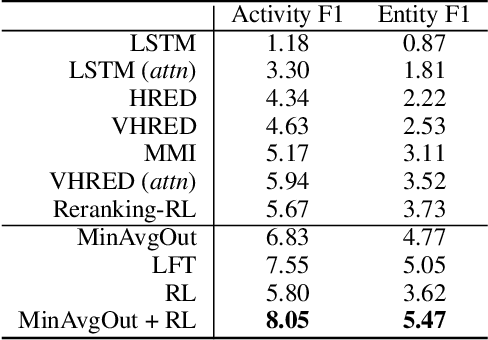
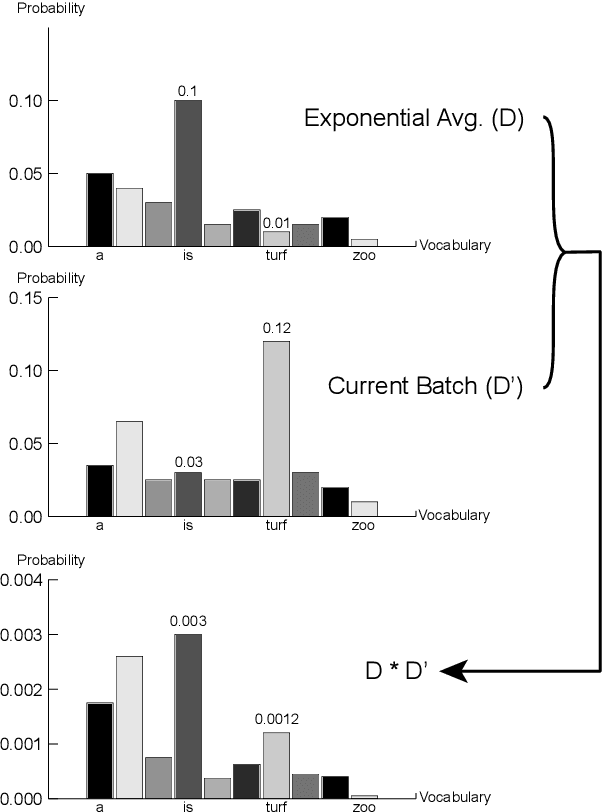
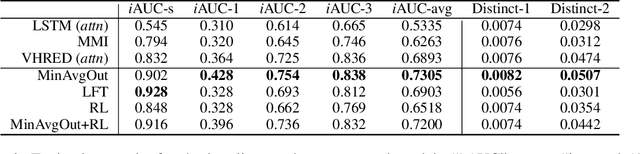
Many sequence-to-sequence dialogue models tend to generate safe, uninformative responses. There have been various useful efforts on trying to eliminate them. However, these approaches either improve decoding algorithms during inference, rely on hand-crafted features, or employ complex models. In our work, we build dialogue models that are dynamically aware of what utterances or tokens are dull without any feature-engineering. Specifically, we start with a simple yet effective automatic metric, AvgOut, which calculates the average output probability distribution of all time steps on the decoder side during training. This metric directly estimates which tokens are more likely to be generated, thus making it a faithful evaluation of the model diversity (i.e., for diverse models, the token probabilities should be more evenly distributed rather than peaked at a few dull tokens). We then leverage this novel metric to propose three models that promote diversity without losing relevance. The first model, MinAvgOut, directly maximizes the diversity score through the output distributions of each batch; the second model, Label Fine-Tuning (LFT), prepends to the source sequence a label continuously scaled by the diversity score to control the diversity level; the third model, RL, adopts Reinforcement Learning and treats the diversity score as a reward signal. Moreover, we experiment with a hybrid model by combining the loss terms of MinAvgOut and RL. All four models outperform their base LSTM-RNN model on both diversity and relevance by a large margin, and are comparable to or better than competitive baselines (also verified via human evaluation). Moreover, our approaches are orthogonal to the base model, making them applicable as an add-on to other emerging better dialogue models in the future.
Automatically Learning Data Augmentation Policies for Dialogue Tasks
Sep 27, 2019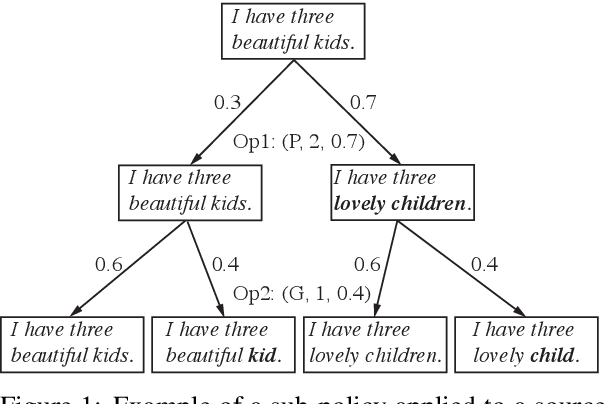
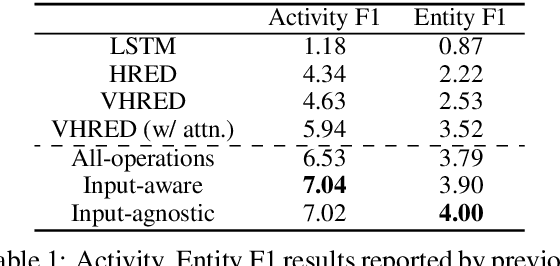
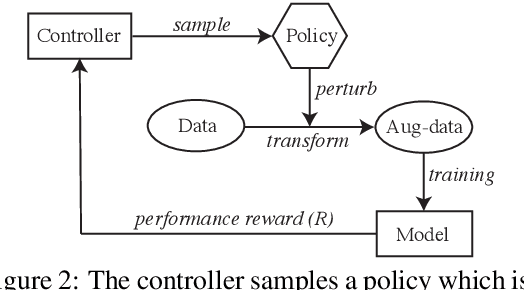
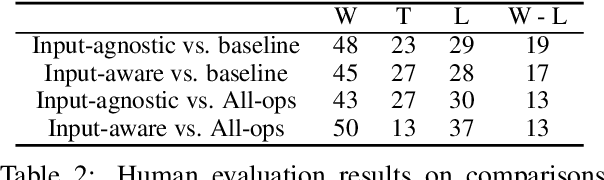
Automatic data augmentation (AutoAugment) (Cubuk et al., 2019) searches for optimal perturbation policies via a controller trained using performance rewards of a sampled policy on the target task, hence reducing data-level model bias. While being a powerful algorithm, their work has focused on computer vision tasks, where it is comparatively easy to apply imperceptible perturbations without changing an image's semantic meaning. In our work, we adapt AutoAugment to automatically discover effective perturbation policies for natural language processing (NLP) tasks such as dialogue generation. We start with a pool of atomic operations that apply subtle semantic-preserving perturbations to the source inputs of a dialogue task (e.g., different POS-tag types of stopword dropout, grammatical errors, and paraphrasing). Next, we allow the controller to learn more complex augmentation policies by searching over the space of the various combinations of these atomic operations. Moreover, we also explore conditioning the controller on the source inputs of the target task, since certain strategies may not apply to inputs that do not contain that strategy's required linguistic features. Empirically, we demonstrate that both our input-agnostic and input-aware controllers discover useful data augmentation policies, and achieve significant improvements over the previous state-of-the-art, including trained on manually-designed policies.
Deleter: Leveraging BERT to Perform Unsupervised Successive Text Compression
Sep 07, 2019
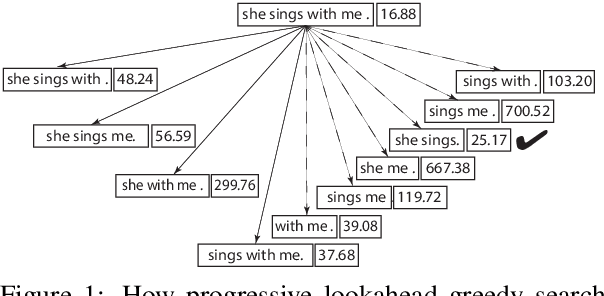
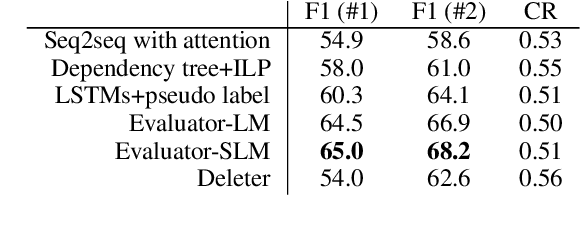
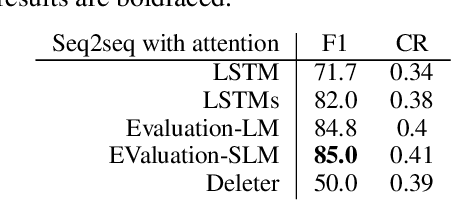
Text compression has diverse applications such as Summarization, Reading Comprehension and Text Editing. However, almost all existing approaches require either hand-crafted features, syntactic labels or parallel data. Even for one that achieves this task in an unsupervised setting, its architecture necessitates a task-specific autoencoder. Moreover, these models only generate one compressed sentence for each source input, so that adapting to different style requirements (e.g. length) for the final output usually implies retraining the model from scratch. In this work, we propose a fully unsupervised model, Deleter, that is able to discover an "optimal deletion path" for an arbitrary sentence, where each intermediate sequence along the path is a coherent subsequence of the previous one. This approach relies exclusively on a pretrained bidirectional language model (BERT) to score each candidate deletion based on the average Perplexity of the resulting sentence and performs progressive greedy lookahead search to select the best deletion for each step. We apply Deleter to the task of extractive Sentence Compression, and found that our model is competitive with state-of-the-art supervised models trained on 1.02 million in-domain examples with similar compression ratio. Qualitative analysis, as well as automatic and human evaluations both verify that our model produces high-quality compression.
A novel hybrid model based on multi-objective Harris hawks optimization algorithm for daily PM2.5 and PM10 forecasting
May 30, 2019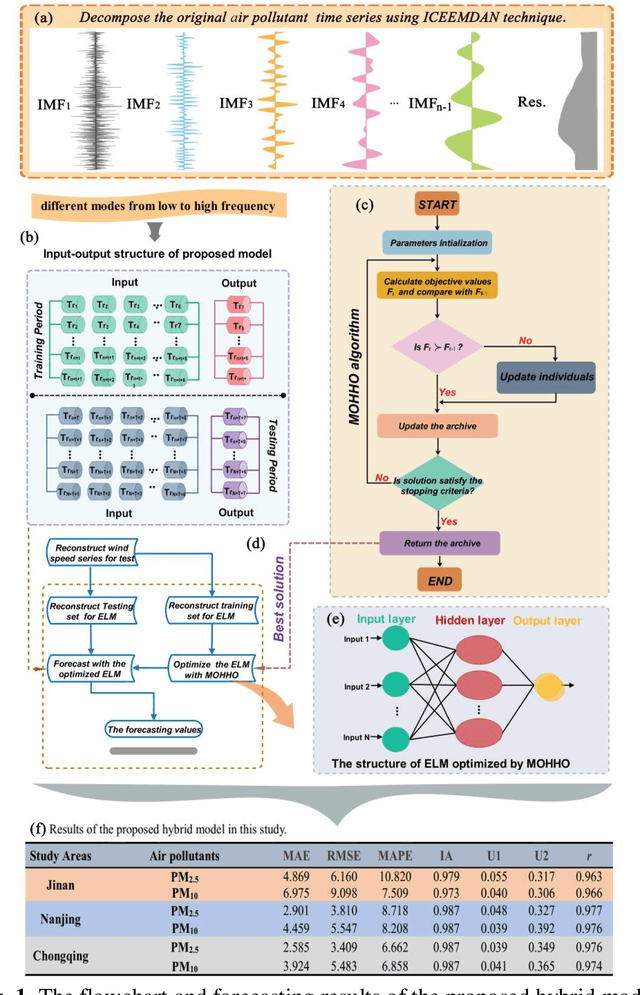
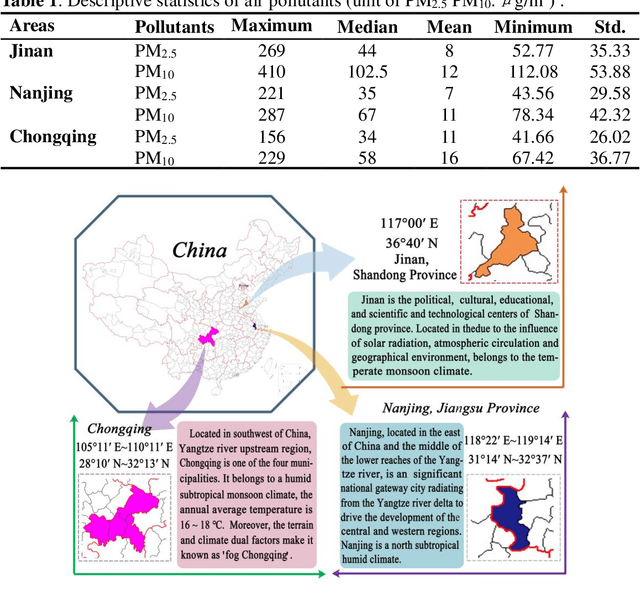
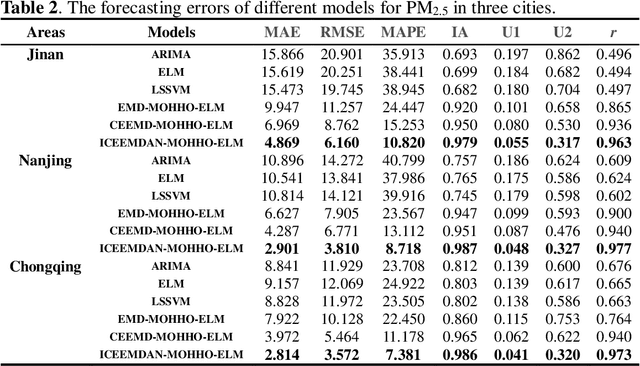
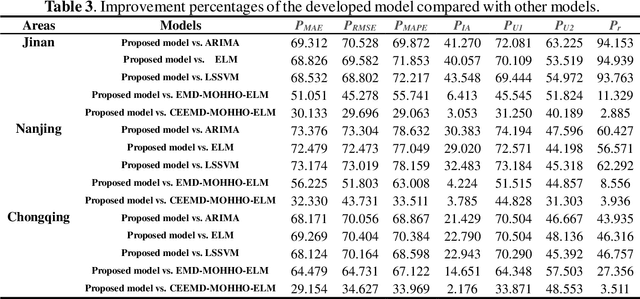
High levels of air pollution may seriously affect people's living environment and even endanger their lives. In order to reduce air pollution concentrations, and warn the public before the occurrence of hazardous air pollutants, it is urgent to design an accurate and reliable air pollutant forecasting model. However, most previous research have many deficiencies, such as ignoring the importance of predictive stability, and poor initial parameters and so on, which have significantly effect on the performance of air pollution prediction. Therefore, to address these issues, a novel hybrid model is proposed in this study. Specifically, a powerful data preprocessing techniques is applied to decompose the original time series into different modes from low- frequency to high- frequency. Next, a new multi-objective algorithm called MOHHO is first developed in this study, which are introduced to tune the parameters of ELM model with high forecasting accuracy and stability for air pollution series prediction, simultaneously. And the optimized ELM model is used to perform the time series prediction. Finally, a scientific and robust evaluation system including several error criteria, benchmark models, and several experiments using six air pollutant concentrations time series from three cities in China is designed to perform a compressive assessment for the presented hybrid forecasting model. Experimental results indicate that the proposed hybrid model can guarantee a more stable and higher predictive performance compared to others, whose superior prediction ability may help to develop effective plans for air pollutant emissions and prevent health problems caused by air pollution.