 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Char2Subword: Extending the Subword Embedding Space from Pre-trained Models Using Robust Character Compositionality
Oct 24, 2020

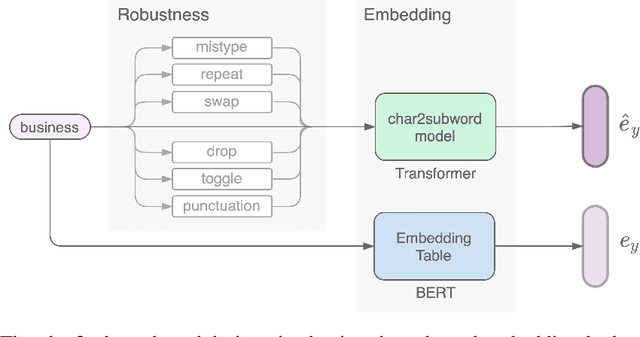
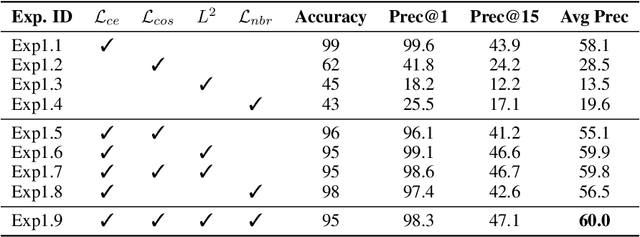
Byte-pair encoding (BPE) is a ubiquitous algorithm in the subword tokenization process of language models. BPE provides multiple benefits, such as handling the out-of-vocabulary problem and reducing vocabulary sparsity. However, this process is defined from the pre-training data statistics, making the tokenization on different domains susceptible to infrequent spelling sequences (e.g., misspellings as in social media or character-level adversarial attacks). On the other hand, pure character-level models, though robust to misspellings, often lead to unreasonably large sequence lengths and make it harder for the model to learn meaningful contiguous characters. To alleviate these challenges, we propose a character-based subword transformer module (char2subword) that learns the subword embedding table in pre-trained models like BERT. Our char2subword module builds representations from characters out of the subword vocabulary, and it can be used as a drop-in replacement of the subword embedding table. The module is robust to character-level alterations such as misspellings, word inflection, casing, and punctuation. We integrate it further with BERT through pre-training while keeping BERT transformer parameters fixed. We show our method's effectiveness by outperforming a vanilla multilingual BERT on the linguistic code-switching evaluation (LinCE) benchmark.
Improving out-of-distribution generalization via multi-task self-supervised pretraining
Mar 30, 2020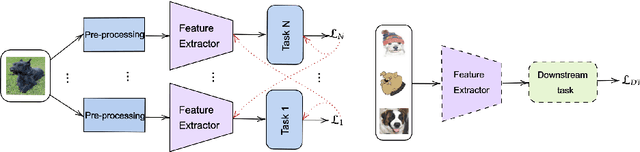


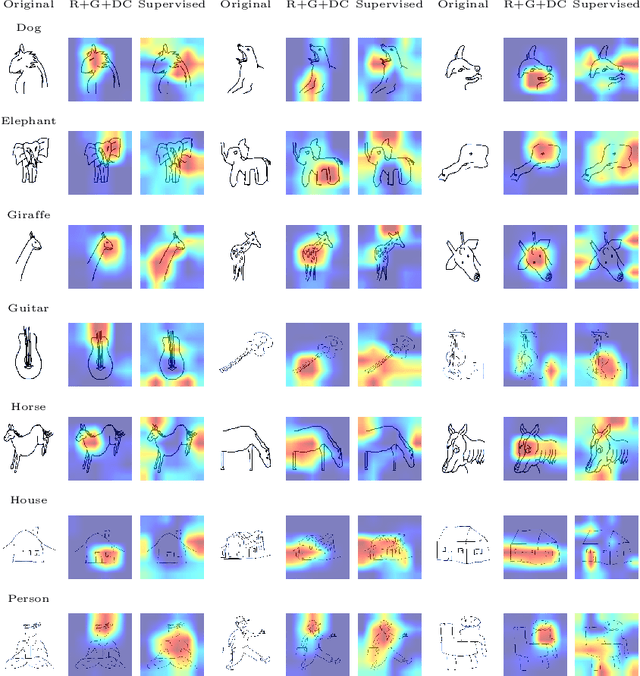
Self-supervised feature representations have been shown to be useful for supervised classification, few-shot learning, and adversarial robustness. We show that features obtained using self-supervised learning are comparable to, or better than, supervised learning for domain generalization in computer vision. We introduce a new self-supervised pretext task of predicting responses to Gabor filter banks and demonstrate that multi-task learning of compatible pretext tasks improves domain generalization performance as compared to training individual tasks alone. Features learnt through self-supervision obtain better generalization to unseen domains when compared to their supervised counterpart when there is a larger domain shift between training and test distributions and even show better localization ability for objects of interest. Self-supervised feature representations can also be combined with other domain generalization methods to further boost performance.