 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Reinforcement Learning: Approximating Optimal Discounted TSP Using Local Policies
Mar 13, 2018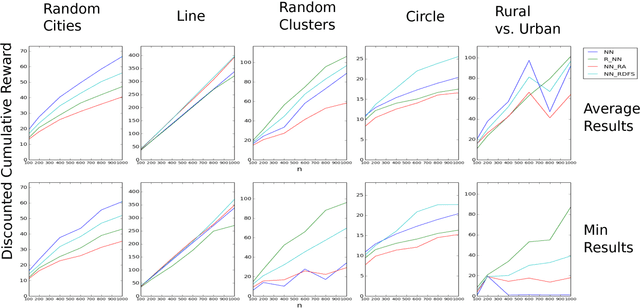
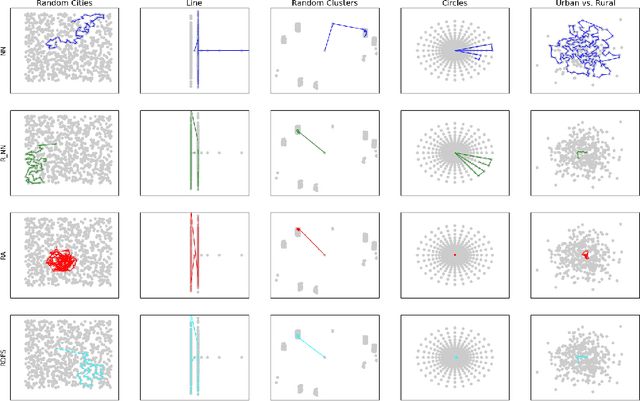
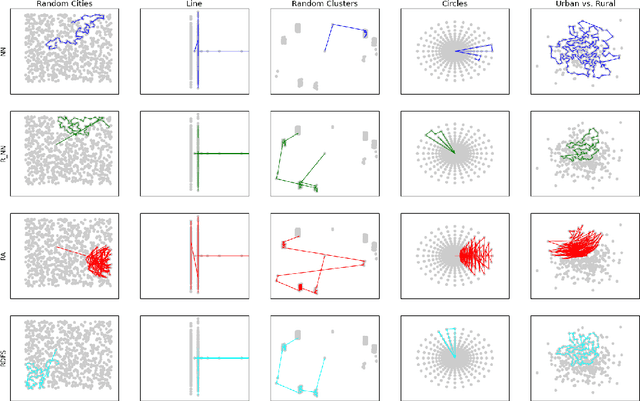
In this work, we provide theoretical guarantees for reward decomposition in deterministic MDPs. Reward decomposition is a special case of Hierarchical Reinforcement Learning, that allows one to learn many policies in parallel and combine them into a composite solution. Our approach builds on mapping this problem into a Reward Discounted Traveling Salesman Problem, and then deriving approximate solutions for it. In particular, we focus on approximate solutions that are local, i.e., solutions that only observe information about the current state. Local policies are easy to implement and do not require substantial computational resources as they do not perform planning. While local deterministic policies, like Nearest Neighbor, are being used in practice for hierarchical reinforcement learning, we propose three stochastic policies that guarantee better performance than any deterministic policy.
Train on Validation: Squeezing the Data Lemon
Feb 16, 2018

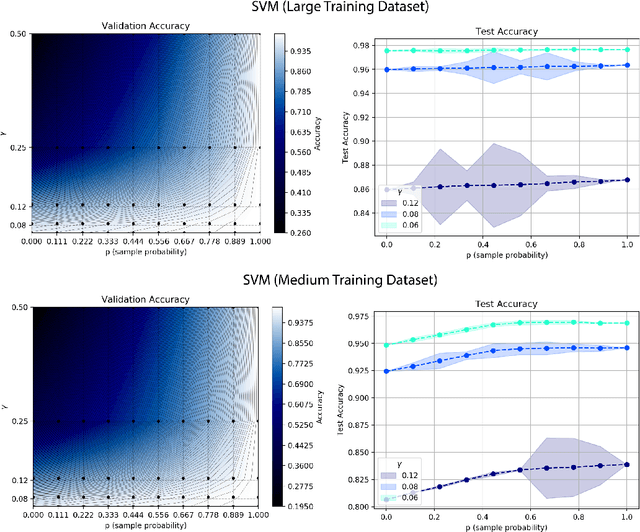
Model selection on validation data is an essential step in machine learning. While the mixing of data between training and validation is considered taboo, practitioners often violate it to increase performance. Here, we offer a simple, practical method for using the validation set for training, which allows for a continuous, controlled trade-off between performance and overfitting of model selection. We define the notion of on-average-validation-stable algorithms as one in which using small portions of validation data for training does not overfit the model selection process. We then prove that stable algorithms are also validation stable. Finally, we demonstrate our method on the MNIST and CIFAR-10 datasets using stable algorithms as well as state-of-the-art neural networks. Our results show significant increase in test performance with a minor trade-off in bias admitted to the model selection process.
Ensemble Robustness and Generalization of Stochastic Deep Learning Algorithms
Nov 05, 2017

The question why deep learning algorithms generalize so well has attracted increasing research interest. However, most of the well-established approaches, such as hypothesis capacity, stability or sparseness, have not provided complete explanations (Zhang et al., 2016; Kawaguchi et al., 2017). In this work, we focus on the robustness approach (Xu & Mannor, 2012), i.e., if the error of a hypothesis will not change much due to perturbations of its training examples, then it will also generalize well. As most deep learning algorithms are stochastic (e.g., Stochastic Gradient Descent, Dropout, and Bayes-by-backprop), we revisit the robustness arguments of Xu & Mannor, and introduce a new approach, ensemble robustness, that concerns the robustness of a population of hypotheses. Through the lens of ensemble robustness, we reveal that a stochastic learning algorithm can generalize well as long as its sensitiveness to adversarial perturbations is bounded in average over training examples. Moreover, an algorithm may be sensitive to some adversarial examples (Goodfellow et al., 2015) but still generalize well. To support our claims, we provide extensive simulations for different deep learning algorithms and different network architectures exhibiting a strong correlation between ensemble robustness and the ability to generalize.
Shallow Updates for Deep Reinforcement Learning
Nov 02, 2017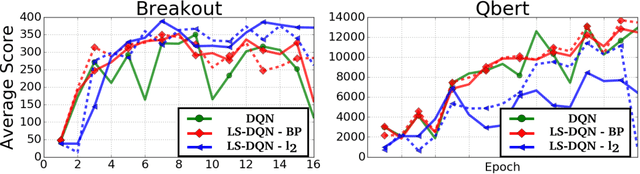


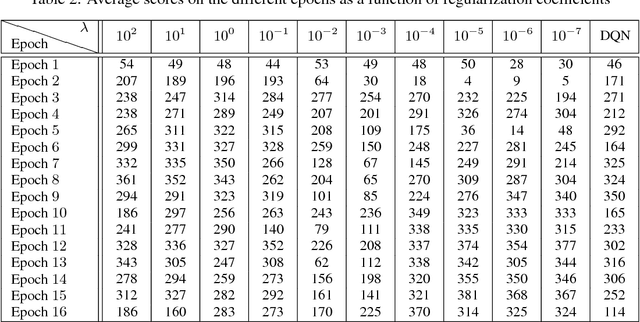
Deep reinforcement learning (DRL) methods such as the Deep Q-Network (DQN) have achieved state-of-the-art results in a variety of challenging, high-dimensional domains. This success is mainly attributed to the power of deep neural networks to learn rich domain representations for approximating the value function or policy. Batch reinforcement learning methods with linear representations, on the other hand, are more stable and require less hyper parameter tuning. Yet, substantial feature engineering is necessary to achieve good results. In this work we propose a hybrid approach -- the Least Squares Deep Q-Network (LS-DQN), which combines rich feature representations learned by a DRL algorithm with the stability of a linear least squares method. We do this by periodically re-training the last hidden layer of a DRL network with a batch least squares update. Key to our approach is a Bayesian regularization term for the least squares update, which prevents over-fitting to the more recent data. We tested LS-DQN on five Atari games and demonstrate significant improvement over vanilla DQN and Double-DQN. We also investigated the reasons for the superior performance of our method. Interestingly, we found that the performance improvement can be attributed to the large batch size used by the LS method when optimizing the last layer.
Graying the black box: Understanding DQNs
Apr 24, 2017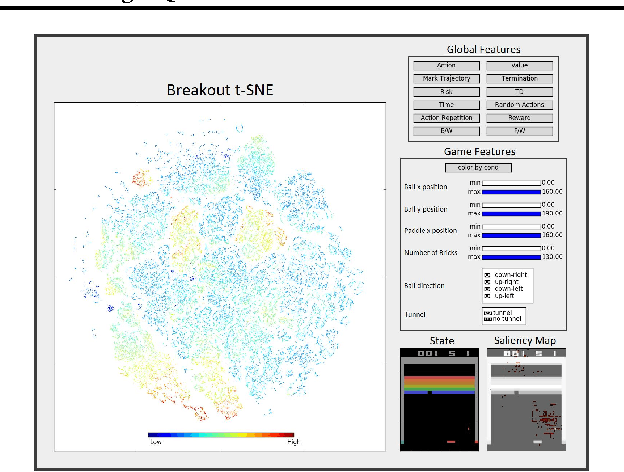
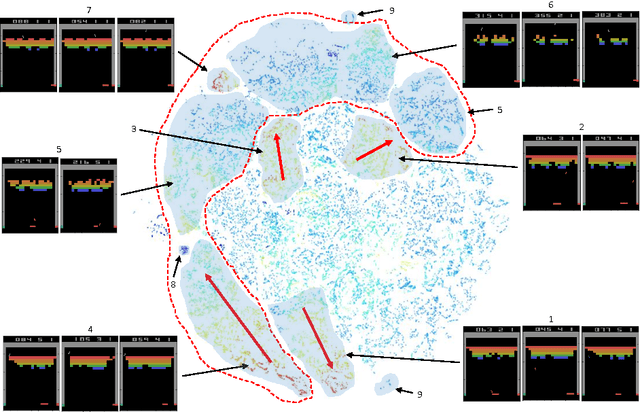

In recent years there is a growing interest in using deep representations for reinforcement learning. In this paper, we present a methodology and tools to analyze Deep Q-networks (DQNs) in a non-blind matter. Moreover, we propose a new model, the Semi Aggregated Markov Decision Process (SAMDP), and an algorithm that learns it automatically. The SAMDP model allows us to identify spatio-temporal abstractions directly from features and may be used as a sub-goal detector in future work. Using our tools we reveal that the features learned by DQNs aggregate the state space in a hierarchical fashion, explaining its success. Moreover, we are able to understand and describe the policies learned by DQNs for three different Atari2600 games and suggest ways to interpret, debug and optimize deep neural networks in reinforcement learning.
A Deep Hierarchical Approach to Lifelong Learning in Minecraft
Nov 30, 2016
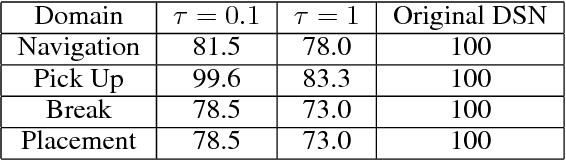
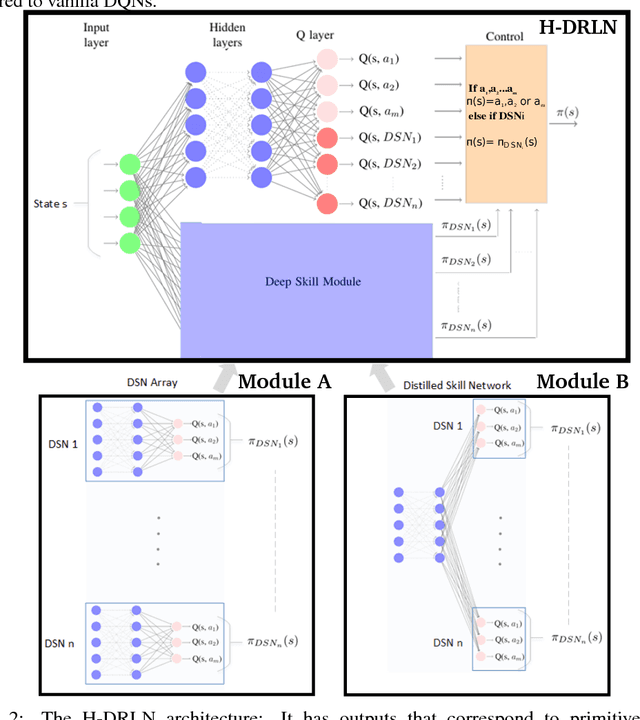
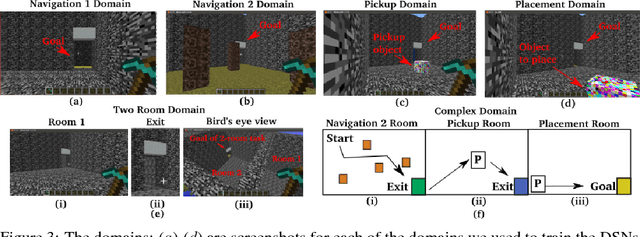
We propose a lifelong learning system that has the ability to reuse and transfer knowledge from one task to another while efficiently retaining the previously learned knowledge-base. Knowledge is transferred by learning reusable skills to solve tasks in Minecraft, a popular video game which is an unsolved and high-dimensional lifelong learning problem. These reusable skills, which we refer to as Deep Skill Networks, are then incorporated into our novel Hierarchical Deep Reinforcement Learning Network (H-DRLN) architecture using two techniques: (1) a deep skill array and (2) skill distillation, our novel variation of policy distillation (Rusu et. al. 2015) for learning skills. Skill distillation enables the HDRLN to efficiently retain knowledge and therefore scale in lifelong learning, by accumulating knowledge and encapsulating multiple reusable skills into a single distilled network. The H-DRLN exhibits superior performance and lower learning sample complexity compared to the regular Deep Q Network (Mnih et. al. 2015) in sub-domains of Minecraft.
Is a picture worth a thousand words? A Deep Multi-Modal Fusion Architecture for Product Classification in e-commerce
Nov 29, 2016
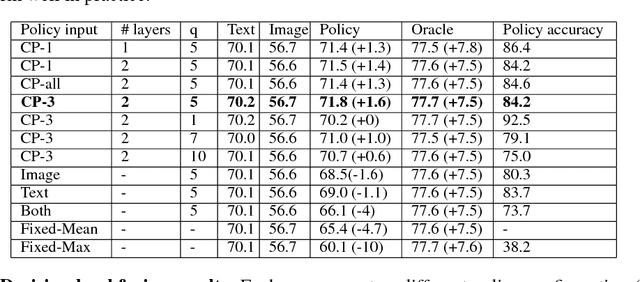
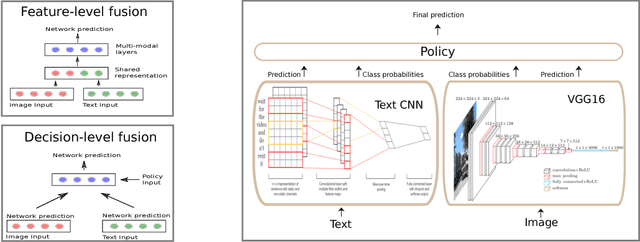
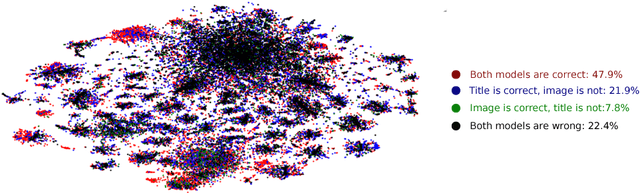
Classifying products into categories precisely and efficiently is a major challenge in modern e-commerce. The high traffic of new products uploaded daily and the dynamic nature of the categories raise the need for machine learning models that can reduce the cost and time of human editors. In this paper, we propose a decision level fusion approach for multi-modal product classification using text and image inputs. We train input specific state-of-the-art deep neural networks for each input source, show the potential of forging them together into a multi-modal architecture and train a novel policy network that learns to choose between them. Finally, we demonstrate that our multi-modal network improves the top-1 accuracy % over both networks on a real-world large-scale product classification dataset that we collected fromWalmart.com. While we focus on image-text fusion that characterizes e-commerce domains, our algorithms can be easily applied to other modalities such as audio, video, physical sensors, etc.
Visualizing Dynamics: from t-SNE to SEMI-MDPs
Jun 22, 2016
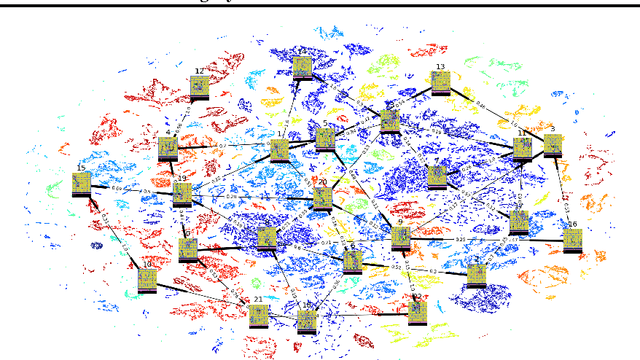
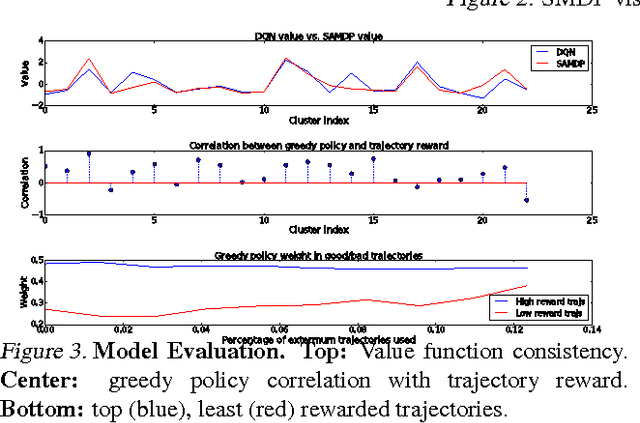
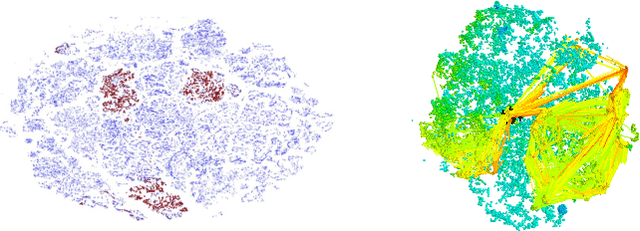
Deep Reinforcement Learning (DRL) is a trending field of research, showing great promise in many challenging problems such as playing Atari, solving Go and controlling robots. While DRL agents perform well in practice we are still missing the tools to analayze their performance and visualize the temporal abstractions that they learn. In this paper, we present a novel method that automatically discovers an internal Semi Markov Decision Process (SMDP) model in the Deep Q Network's (DQN) learned representation. We suggest a novel visualization method that represents the SMDP model by a directed graph and visualize it above a t-SNE map. We show how can we interpret the agent's policy and give evidence for the hierarchical state aggregation that DQNs are learning automatically. Our algorithm is fully automatic, does not require any domain specific knowledge and is evaluated by a novel likelihood based evaluation criteria.
Deep Reinforcement Learning Discovers Internal Models
Jun 16, 2016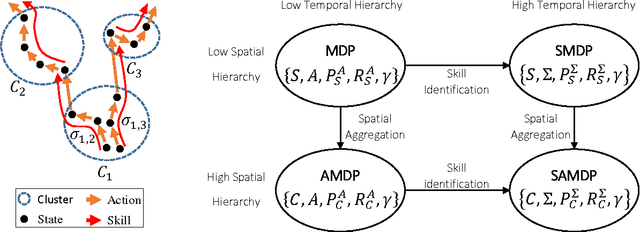

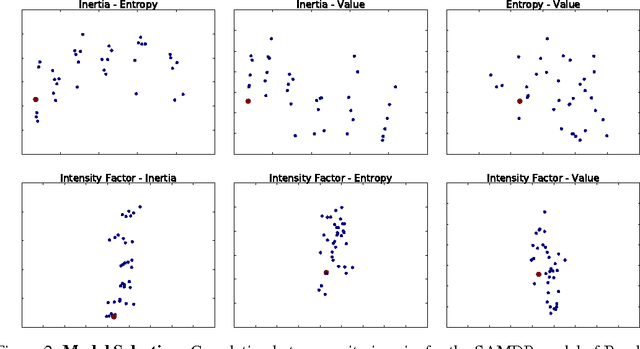
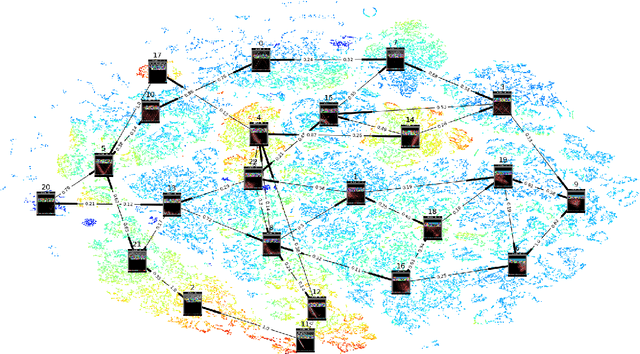
Deep Reinforcement Learning (DRL) is a trending field of research, showing great promise in challenging problems such as playing Atari, solving Go and controlling robots. While DRL agents perform well in practice we are still lacking the tools to analayze their performance. In this work we present the Semi-Aggregated MDP (SAMDP) model. A model best suited to describe policies exhibiting both spatial and temporal hierarchies. We describe its advantages for analyzing trained policies over other modeling approaches, and show that under the right state representation, like that of DQN agents, SAMDP can help to identify skills. We detail the automatic process of creating it from recorded trajectories, up to presenting it on t-SNE maps. We explain how to evaluate its fitness and show surprising results indicating high compatibility with the policy at hand. We conclude by showing how using the SAMDP model, an extra performance gain can be squeezed from the agent.