 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapped Meta-Learning
Sep 09, 2021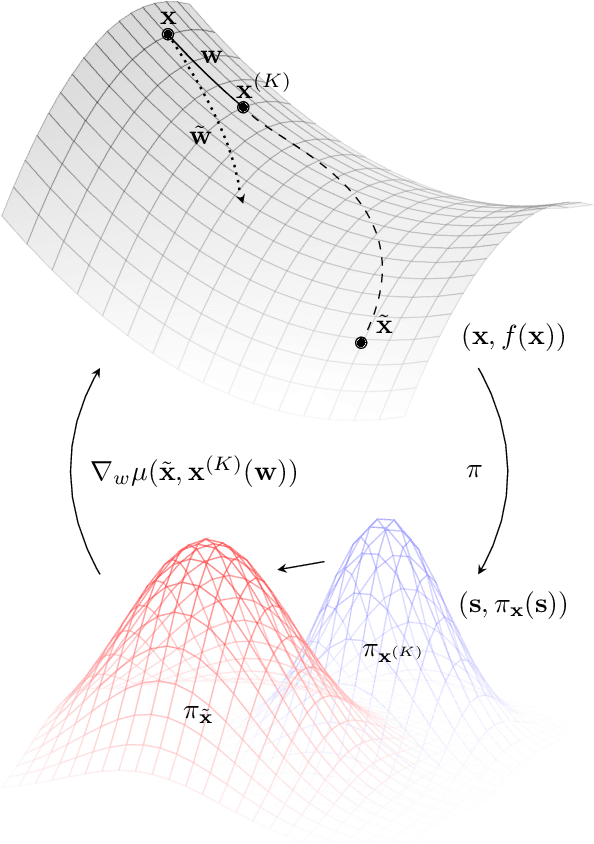

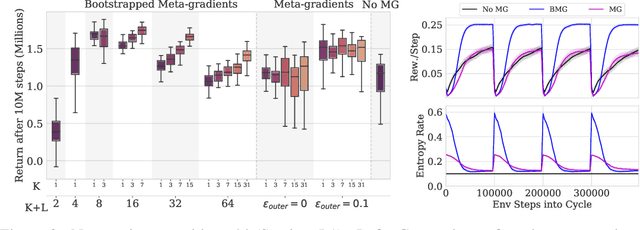
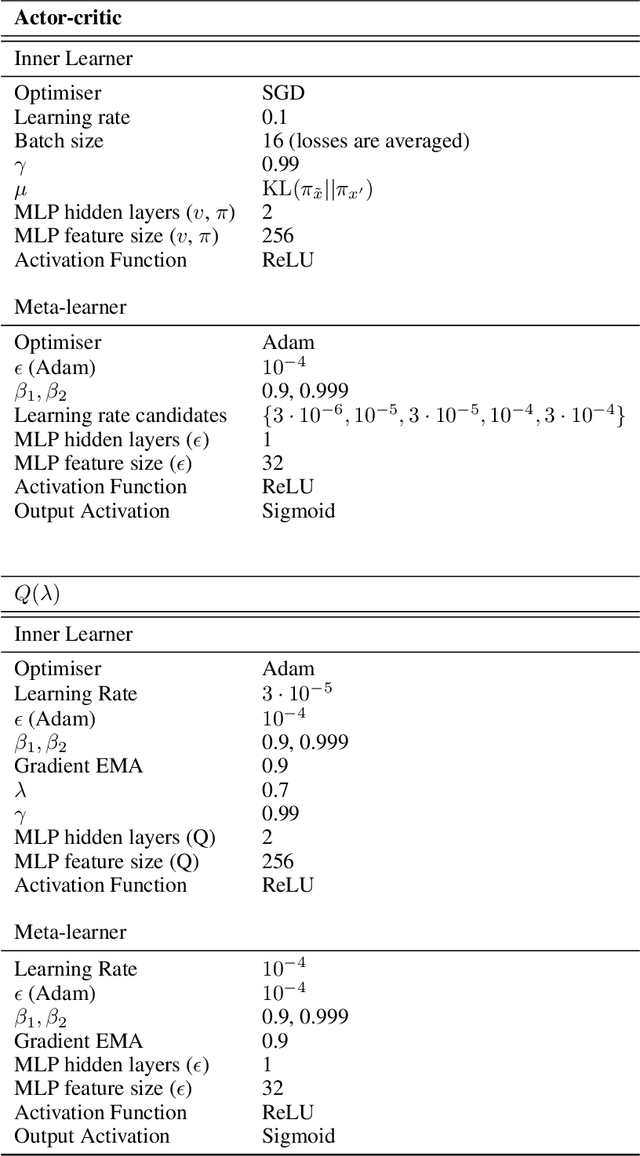
Meta-learning empowers artificial intelligence to increase its efficiency by learning how to learn. Unlocking this potential involves overcoming a challenging meta-optimisation problem that often exhibits ill-conditioning, and myopic meta-objectives. We propose an algorithm that tackles these issues by letting the meta-learner teach itself. The algorithm first bootstraps a target from the meta-learner, then optimises the meta-learner by minimising the distance to that target under a chosen (pseudo-)metric. Focusing on meta-learning with gradients, we establish conditions that guarantee performance improvements and show that the improvement is related to the target distance. Thus, by controlling curvature, the distance measure can be used to ease meta-optimization, for instance by reducing ill-conditioning. Further, the bootstrapping mechanism can extend the effective meta-learning horizon without requiring backpropagation through all updates. The algorithm is versatile and easy to implement. We achieve a new state-of-the art for model-free agents on the Atari ALE benchmark, improve upon MAML in few-shot learning, and demonstrate how our approach opens up new possibilities by meta-learning efficient exploration in a Q-learning agent.
Emphatic Algorithms for Deep Reinforcement Learning
Jun 21, 2021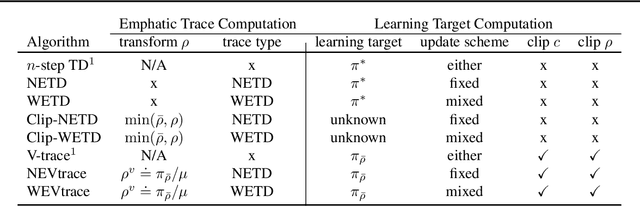
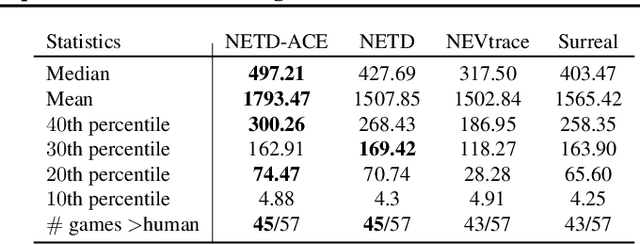
Off-policy learning allows us to learn about possible policies of behavior from experience generated by a different behavior policy. Temporal difference (TD) learning algorithms can become unstable when combined with function approximation and off-policy sampling - this is known as the ''deadly triad''. Emphatic temporal difference (ETD($\lambda$)) algorithm ensures convergence in the linear case by appropriately weighting the TD($\lambda$) updates. In this paper, we extend the use of emphatic methods to deep reinforcement learning agents. We show that naively adapting ETD($\lambda$) to popular deep reinforcement learning algorithms, which use forward view multi-step returns, results in poor performance. We then derive new emphatic algorithms for use in the context of such algorithms, and we demonstrate that they provide noticeable benefits in small problems designed to highlight the instability of TD methods. Finally, we observed improved performance when applying these algorithms at scale on classic Atari games from the Arcade Learning Environment.
Discovering Diverse Nearly Optimal Policies withSuccessor Features
Jun 01, 2021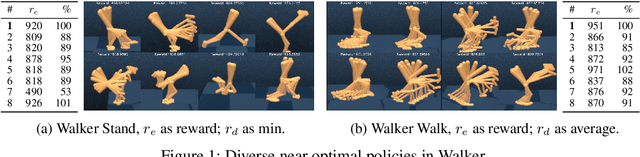


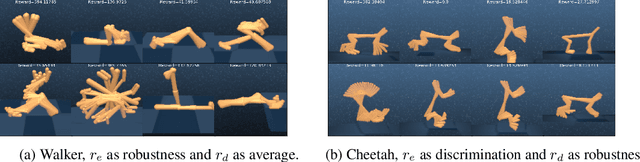
Finding different solutions to the same problem is a key aspect of intelligence associated with creativity and adaptation to novel situations. In reinforcement learning, a set of diverse policies can be useful for exploration, transfer, hierarchy, and robustness. We propose Diverse Successive Policies, a method for discovering policies that are diverse in the space of Successor Features, while assuring that they are near optimal. We formalize the problem as a Constrained Markov Decision Process (CMDP) where the goal is to find policies that maximize diversity, characterized by an intrinsic diversity reward, while remaining near-optimal with respect to the extrinsic reward of the MDP. We also analyze how recently proposed robustness and discrimination rewards perform and find that they are sensitive to the initialization of the procedure and may converge to sub-optimal solutions. To alleviate this, we propose new explicit diversity rewards that aim to minimize the correlation between the Successor Features of the policies in the set. We compare the different diversity mechanisms in the DeepMind Control Suite and find that the type of explicit diversity we are proposing is important to discover distinct behavior, like for example different locomotion patterns.
Reward is enough for convex MDPs
Jun 01, 2021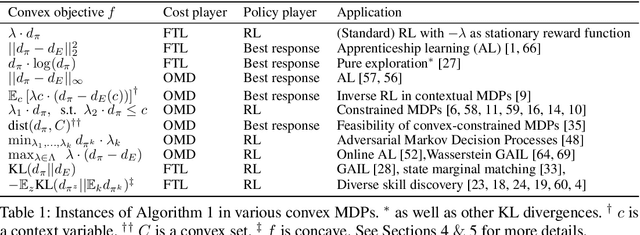
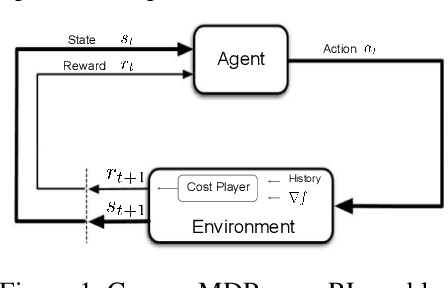
Maximising a cumulative reward function that is Markov and stationary, i.e., defined over state-action pairs and independent of time, is sufficient to capture many kinds of goals in a Markov Decision Process (MDP) based on the Reinforcement Learning (RL) problem formulation. However, not all goals can be captured in this manner. Specifically, it is easy to see that Convex MDPs in which goals are expressed as convex functions of stationary distributions cannot, in general, be formulated in this manner. In this paper, we reformulate the convex MDP problem as a min-max game between the policy and cost (negative reward) players using Fenchel duality and propose a meta-algorithm for solving it. We show that the average of the policies produced by an RL agent that maximizes the non-stationary reward produced by the cost player converges to an optimal solution to the convex MDP. Finally, we show that the meta-algorithm unifies several disparate branches of reinforcement learning algorithms in the literature, such as apprenticeship learning, variational intrinsic control, constrained MDPs, and pure exploration into a single framework.
Online Apprenticeship Learning
Feb 13, 2021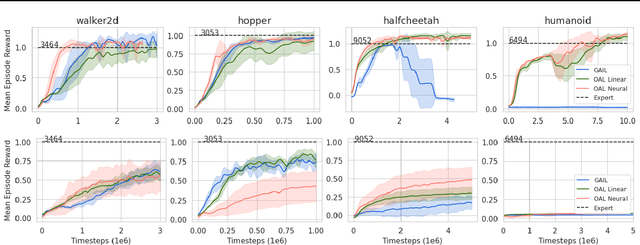
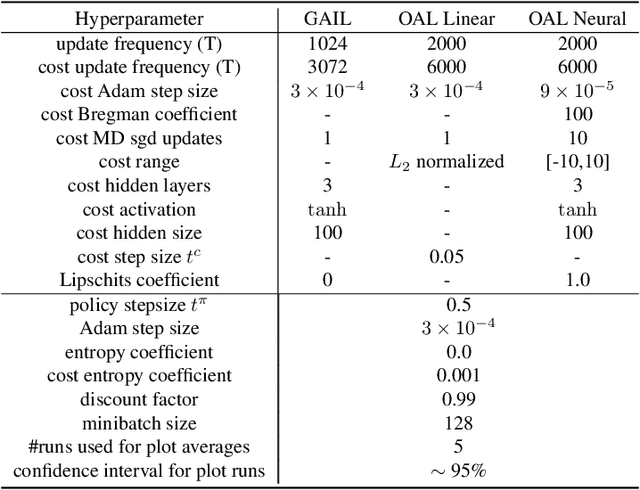
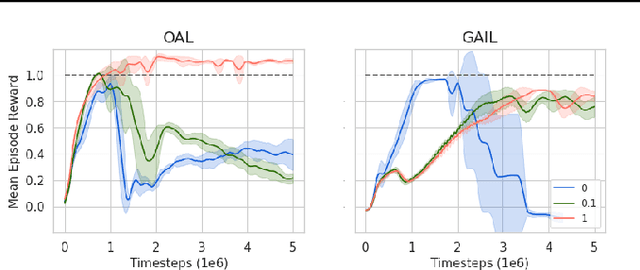
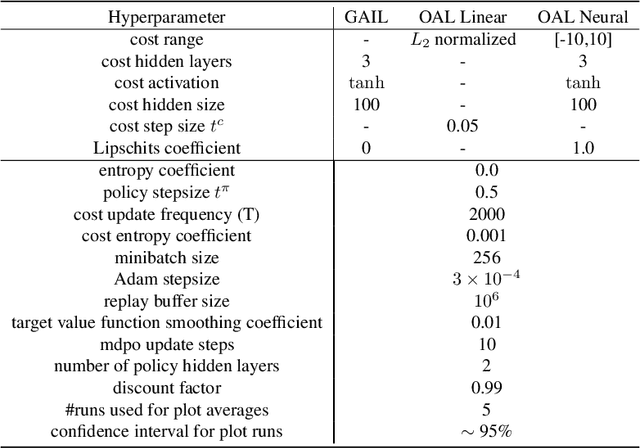
In Apprenticeship Learning (AL), we are given a Markov Decision Process (MDP) without access to the cost function. Instead, we observe trajectories sampled by an expert that acts according to some policy. The goal is to find a policy that matches the expert's performance on some predefined set of cost functions. We introduce an online variant of AL (Online Apprenticeship Learning; OAL), where the agent is expected to perform comparably to the expert while interacting with the environment. We show that the OAL problem can be effectively solved by combining two mirror descent based no-regret algorithms: one for policy optimization and another for learning the worst case cost. To this end, we derive a convergent algorithm with $O(\sqrt{K})$ regret, where $K$ is the number of interactions with the MDP, and an additional linear error term that depends on the amount of expert trajectories available. Importantly, our algorithm avoids the need to solve an MDP at each iteration, making it more practical compared to prior AL methods. Finally, we implement a deep variant of our algorithm which shares some similarities to GAIL \cite{ho2016generative}, but where the discriminator is replaced with the costs learned by the OAL problem. Our simulations demonstrate our theoretically grounded approach outperforms the baselines.
Discovery of Options via Meta-Learned Subgoals
Feb 12, 2021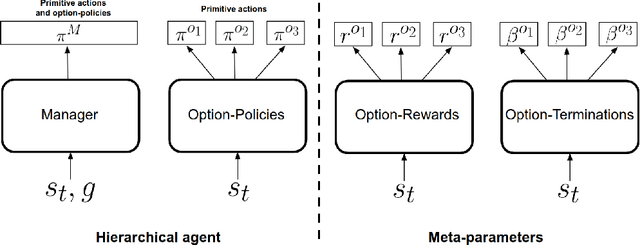
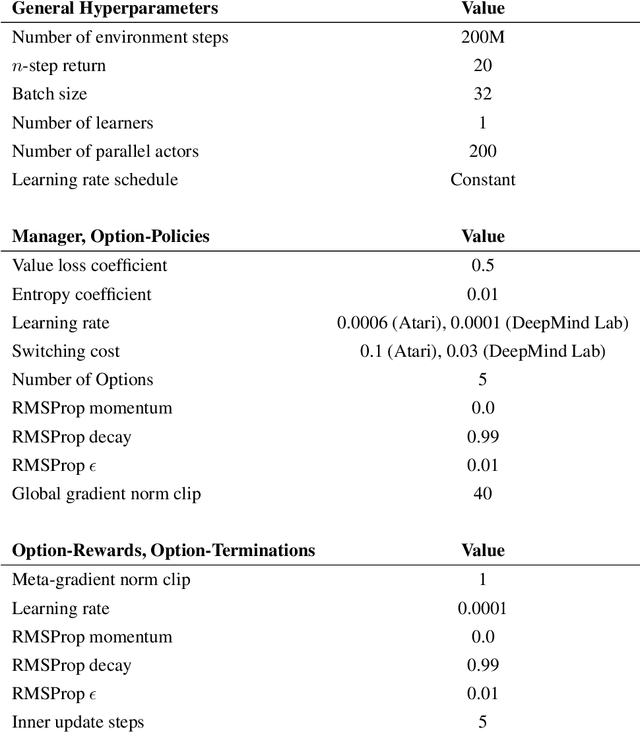
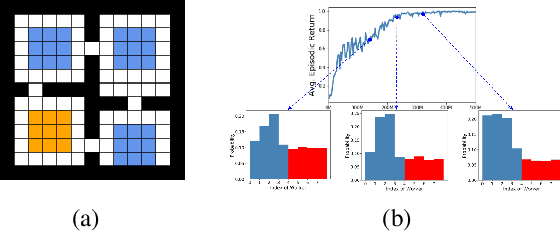
Temporal abstractions in the form of options have been shown to help reinforcement learning (RL) agents learn faster. However, despite prior work on this topic, the problem of discovering options through interaction with an environment remains a challenge. In this paper, we introduce a novel meta-gradient approach for discovering useful options in multi-task RL environments. Our approach is based on a manager-worker decomposition of the RL agent, in which a manager maximises rewards from the environment by learning a task-dependent policy over both a set of task-independent discovered-options and primitive actions. The option-reward and termination functions that define a subgoal for each option are parameterised as neural networks and trained via meta-gradients to maximise their usefulness. Empirical analysis on gridworld and DeepMind Lab tasks show that: (1) our approach can discover meaningful and diverse temporally-extended options in multi-task RL domains, (2) the discovered options are frequently used by the agent while learning to solve the training tasks, and (3) that the discovered options help a randomly initialised manager learn faster in completely new tasks.
Discovering a set of policies for the worst case reward
Feb 08, 2021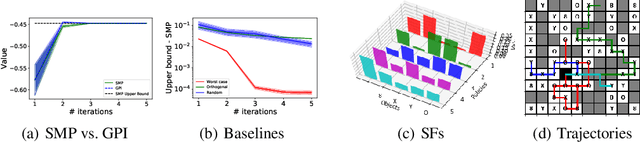
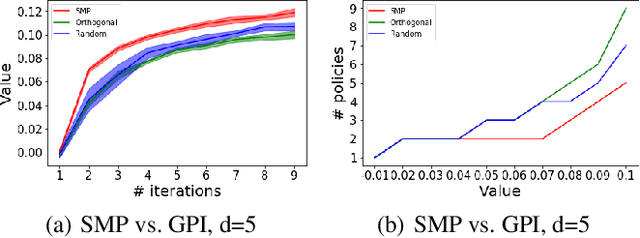
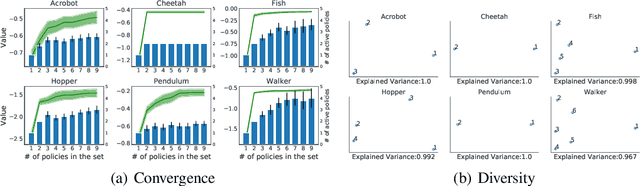

We study the problem of how to construct a set of policies that can be composed together to solve a collection of reinforcement learning tasks. Each task is a different reward function defined as a linear combination of known features. We consider a specific class of policy compositions which we call set improving policies (SIPs): given a set of policies and a set of tasks, a SIP is any composition of the former whose performance is at least as good as that of its constituents across all the tasks. We focus on the most conservative instantiation of SIPs, set-max policies (SMPs), so our analysis extends to any SIP. This includes known policy-composition operators like generalized policy improvement. Our main contribution is a policy iteration algorithm that builds a set of policies in order to maximize the worst-case performance of the resulting SMP on the set of tasks. The algorithm works by successively adding new policies to the set. We show that the worst-case performance of the resulting SMP strictly improves at each iteration, and the algorithm only stops when there does not exist a policy that leads to improved performance. We empirically evaluate our algorithm on a grid world and also on a set of domains from the DeepMind control suite. We confirm our theoretical results regarding the monotonically improving performance of our algorithm. Interestingly, we also show empirically that the sets of policies computed by the algorithm are diverse, leading to different trajectories in the grid world and very distinct locomotion skills in the control suite.
Online Limited Memory Neural-Linear Bandits with Likelihood Matching
Feb 07, 2021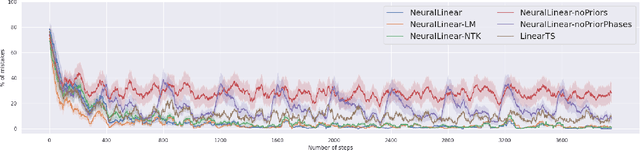
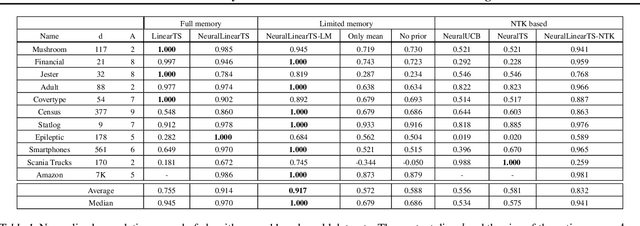
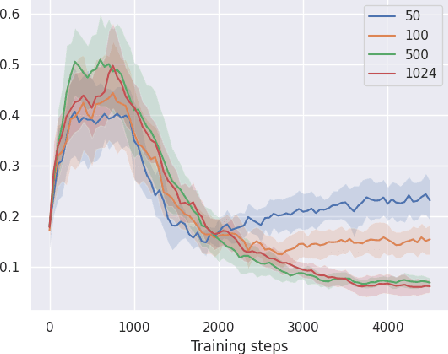
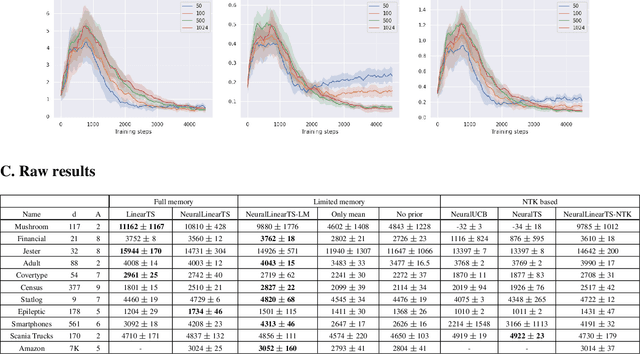
We study neural-linear bandits for solving problems where both exploration and representation learning play an important role. Neural-linear bandits leverage the representation power of Deep Neural Networks (DNNs) and combine it with efficient exploration mechanisms designed for linear contextual bandits on top of the last hidden layer. A recent analysis of DNNs in the "infinite-width" regime suggests that when these models are trained with gradient descent the optimal solution is close to the initialization point and the DNN can be viewed as a kernel machine. As a result, it is possible to exploit linear exploration algorithms on top of a DNN via the kernel construction. The problem is that in practice the kernel changes during the learning process and the agent's performance degrades. This can be resolved by recomputing new uncertainty estimations with stored data. Nevertheless, when the buffer's size is limited, a phenomenon called catastrophic forgetting emerges. Instead, we propose a likelihood matching algorithm that is resilient to catastrophic forgetting and is completely online. We perform simulations on a variety of datasets and observe that our algorithm achieves comparable performance to the unlimited memory approach while exhibits resilience to catastrophic forgetting.
Balancing Constraints and Rewards with Meta-Gradient D4PG
Oct 13, 2020



Deploying Reinforcement Learning (RL) agents to solve real-world applications often requires satisfying complex system constraints. Often the constraint thresholds are incorrectly set due to the complex nature of a system or the inability to verify the thresholds offline (e.g, no simulator or reasonable offline evaluation procedure exists). This results in solutions where a task cannot be solved without violating the constraints. However, in many real-world cases, constraint violations are undesirable yet they are not catastrophic, motivating the need for soft-constrained RL approaches. We present two soft-constrained RL approaches that utilize meta-gradients to find a good trade-off between expected return and minimizing constraint violations. We demonstrate the effectiveness of these approaches by showing that they consistently outperform the baselines across four different Mujoco domains.
Learning to Ask Medical Questions using Reinforcement Learning
Mar 31, 2020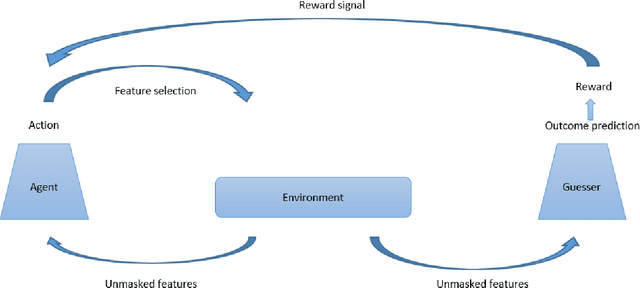
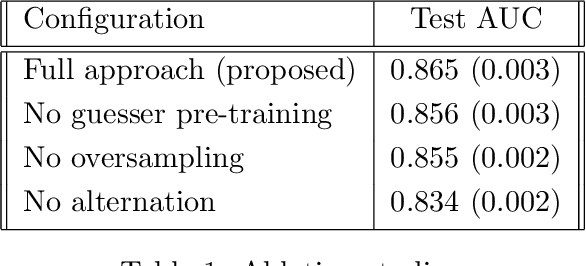


We propose a novel reinforcement learning-based approach for adaptive and iterative feature selection. Given a masked vector of input features, a reinforcement learning agent iteratively selects certain features to be unmasked, and uses them to predict an outcome when it is sufficiently confident. The algorithm makes use of a novel environment setting, corresponding to a non-stationary Markov Decision Process. A key component of our approach is a guesser network, trained to predict the outcome from the selected features and parametrizing the reward function. Applying our method to a national survey dataset, we show that it not only outperforms strong baselines when requiring the prediction to be made based on a small number of input features, but is also highly more interpretable. Our code is publicly available at \url{https://github.com/ushaham/adaptiveFS}.