 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Agents
Aug 24, 2022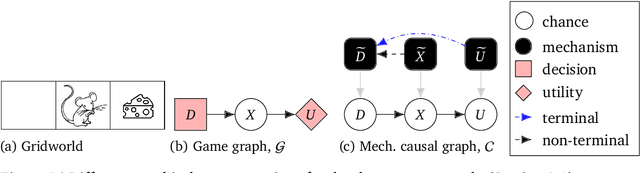
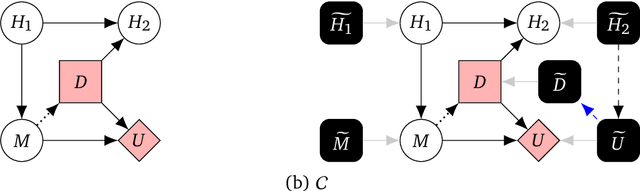
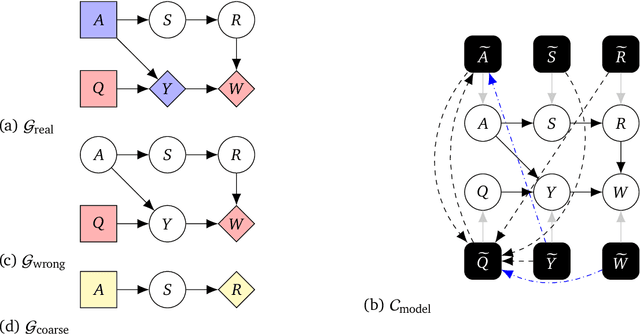
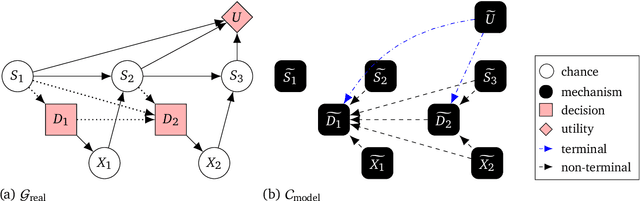
Causal models of agents have been used to analyse the safety aspects of machine learning systems. But identifying agents is non-trivial -- often the causal model is just assumed by the modeler without much justification -- and modelling failures can lead to mistakes in the safety analysis. This paper proposes the first formal causal definition of agents -- roughly that agents are systems that would adapt their policy if their actions influenced the world in a different way. From this we derive the first causal discovery algorithm for discovering agents from empirical data, and give algorithms for translating between causal models and game-theoretic influence diagrams. We demonstrate our approach by resolving some previous confusions caused by incorrect causal modelling of agents.
Path-Specific Objectives for Safer Agent Incentives
Apr 21, 2022

We present a general framework for training safe agents whose naive incentives are unsafe. As an example, manipulative or deceptive behaviour can improve rewards but should be avoided. Most approaches fail here: agents maximize expected return by any means necessary. We formally describe settings with 'delicate' parts of the state which should not be used as a means to an end. We then train agents to maximize the causal effect of actions on the expected return which is not mediated by the delicate parts of state, using Causal Influence Diagram analysis. The resulting agents have no incentive to control the delicate state. We further show how our framework unifies and generalizes existing proposals.
A Complete Criterion for Value of Information in Soluble Influence Diagrams
Feb 23, 2022
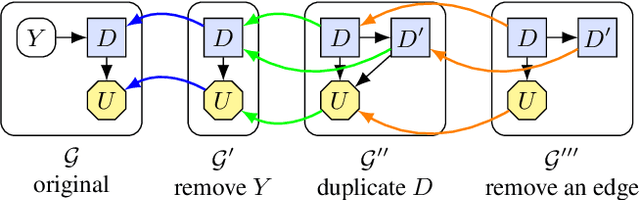
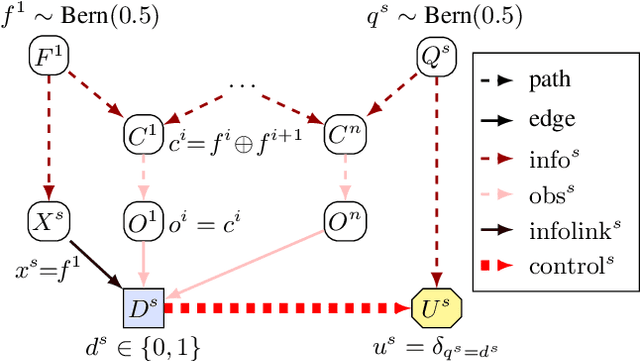
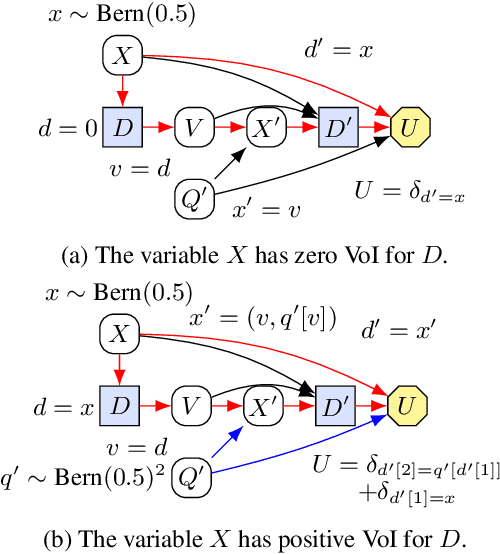
Influence diagrams have recently been used to analyse the safety and fairness properties of AI systems. A key building block for this analysis is a graphical criterion for value of information (VoI). This paper establishes the first complete graphical criterion for VoI in influence diagrams with multiple decisions. Along the way, we establish two important techniques for proving properties of multi-decision influence diagrams: ID homomorphisms are structure-preserving transformations of influence diagrams, while a Tree of Systems is collection of paths that captures how information and control can flow in an influence diagram.
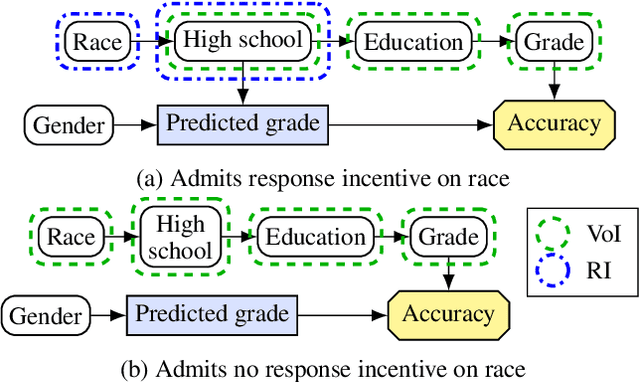
Why Fair Labels Can Yield Unfair Predictions: Graphical Conditions for Introduced Unfairness
Feb 23, 2022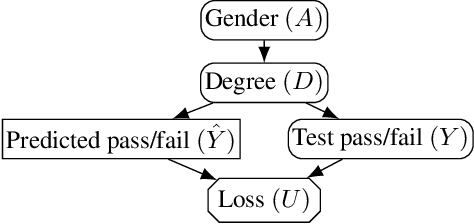
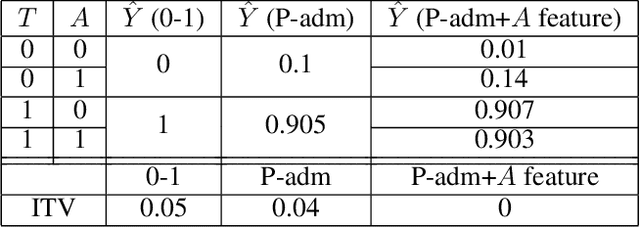
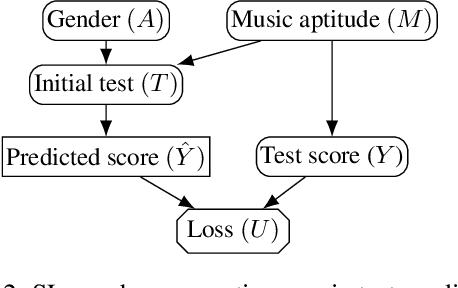
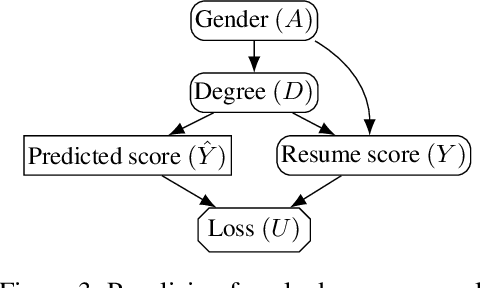
In addition to reproducing discriminatory relationships in the training data, machine learning systems can also introduce or amplify discriminatory effects. We refer to this as introduced unfairness, and investigate the conditions under which it may arise. To this end, we propose introduced total variation as a measure of introduced unfairness, and establish graphical conditions under which it may be incentivised to occur. These criteria imply that adding the sensitive attribute as a feature removes the incentive for introduced variation under well-behaved loss functions. Additionally, taking a causal perspective, introduced path-specific effects shed light on the issue of when specific paths should be considered fair.
Shaking the foundations: delusions in sequence models for interaction and control
Oct 20, 2021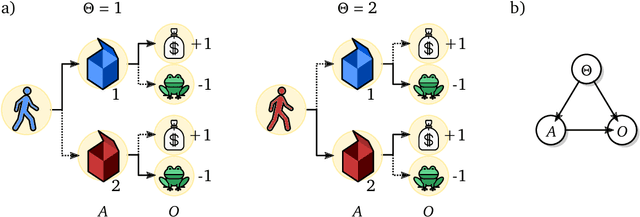
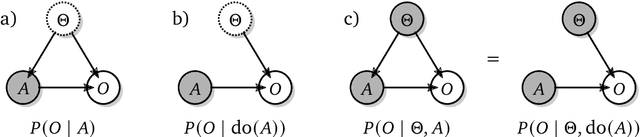
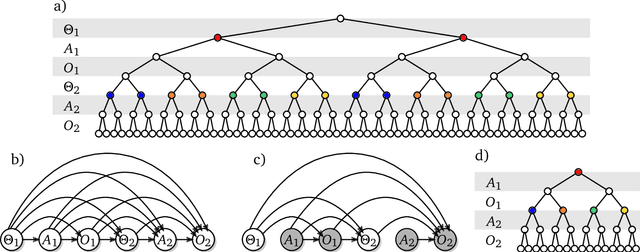
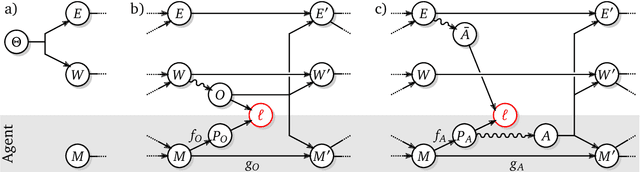
The recent phenomenal success of language models has reinvigorated machine learning research, and large sequence models such as transformers are being applied to a variety of domains. One important problem class that has remained relatively elusive however is purposeful adaptive behavior. Currently there is a common perception that sequence models "lack the understanding of the cause and effect of their actions" leading them to draw incorrect inferences due to auto-suggestive delusions. In this report we explain where this mismatch originates, and show that it can be resolved by treating actions as causal interventions. Finally, we show that in supervised learning, one can teach a system to condition or intervene on data by training with factual and counterfactual error signals respectively.
Alignment of Language Agents
Mar 26, 2021For artificial intelligence to be beneficial to humans the behaviour of AI agents needs to be aligned with what humans want. In this paper we discuss some behavioural issues for language agents, arising from accidental misspecification by the system designer. We highlight some ways that misspecification can occur and discuss some behavioural issues that could arise from misspecification, including deceptive or manipulative language, and review some approaches for avoiding these issues.
How RL Agents Behave When Their Actions Are Modified
Feb 15, 2021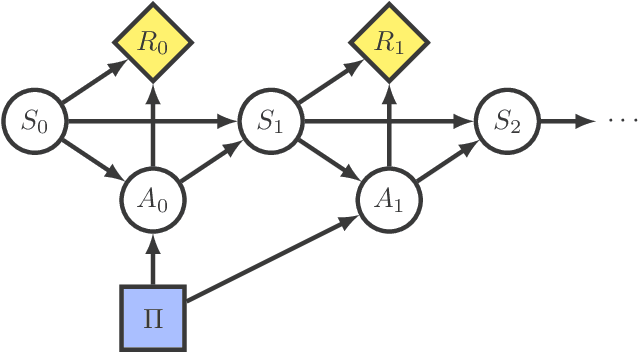
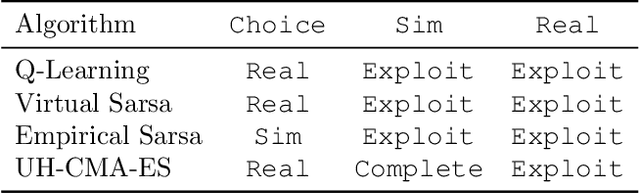
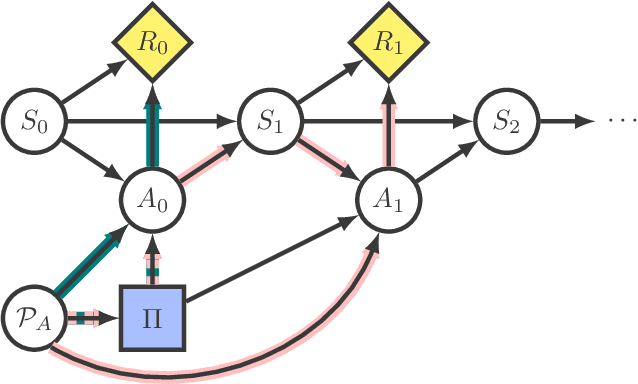

Reinforcement learning in complex environments may require supervision to prevent the agent from attempting dangerous actions. As a result of supervisor intervention, the executed action may differ from the action specified by the policy. How does this affect learning? We present the Modified-Action Markov Decision Process, an extension of the MDP model that allows actions to differ from the policy. We analyze the asymptotic behaviours of common reinforcement learning algorithms in this setting and show that they adapt in different ways: some completely ignore modifications while others go to various lengths in trying to avoid action modifications that decrease reward. By choosing the right algorithm, developers can prevent their agents from learning to circumvent interruptions or constraints, and better control agent responses to other kinds of action modification, like self-damage.
Equilibrium Refinements for Multi-Agent Influence Diagrams: Theory and Practice
Feb 09, 2021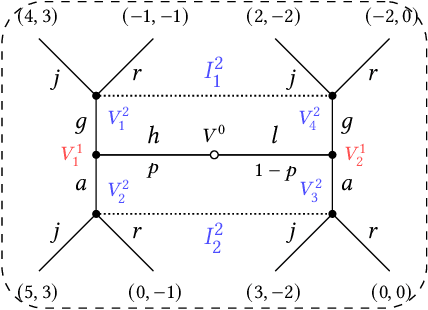
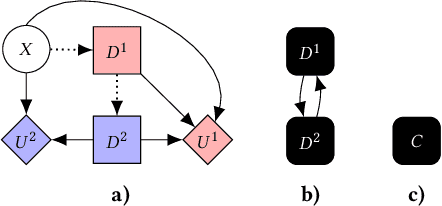
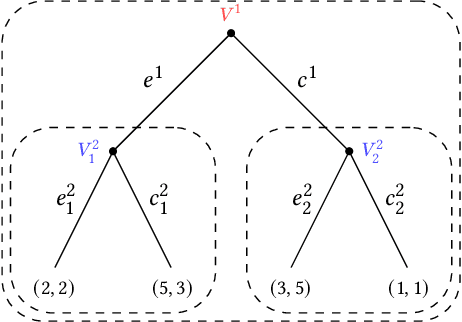
Multi-agent influence diagrams (MAIDs) are a popular form of graphical model that, for certain classes of games, have been shown to offer key complexity and explainability advantages over traditional extensive form game (EFG) representations. In this paper, we extend previous work on MAIDs by introducing the concept of a MAID subgame, as well as subgame perfect and trembling hand perfect equilibrium refinements. We then prove several equivalence results between MAIDs and EFGs. Finally, we describe an open source implementation for reasoning about MAIDs and computing their equilibria.
Agent Incentives: A Causal Perspective
Feb 02, 2021

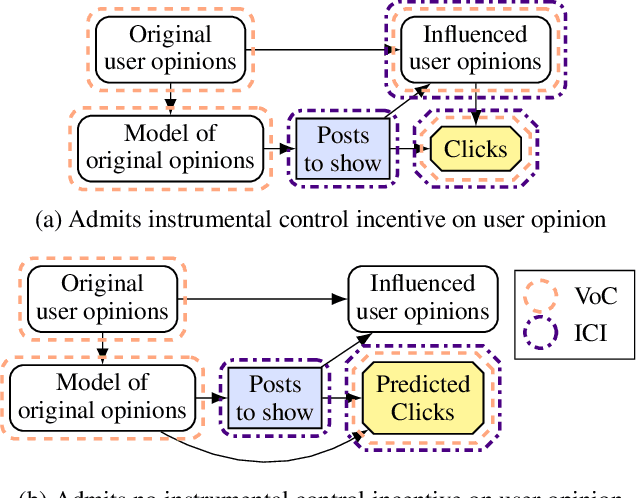
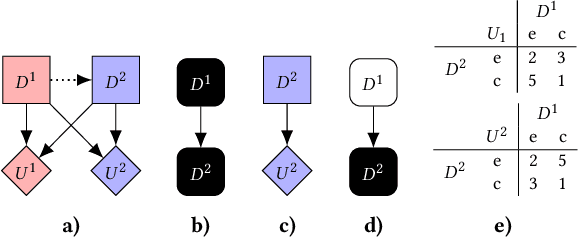
We present a framework for analysing agent incentives using causal influence diagrams. We establish that a well-known criterion for value of information is complete. We propose a new graphical criterion for value of control, establishing its soundness and completeness. We also introduce two new concepts for incentive analysis: response incentives indicate which changes in the environment affect an optimal decision, while instrumental control incentives establish whether an agent can influence its utility via a variable X. For both new concepts, we provide sound and complete graphical criteria. We show by example how these results can help with evaluating the safety and fairness of an AI system.
Avoiding Tampering Incentives in Deep RL via Decoupled Approval
Nov 17, 2020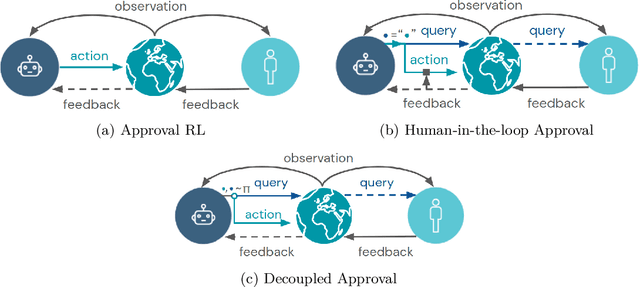
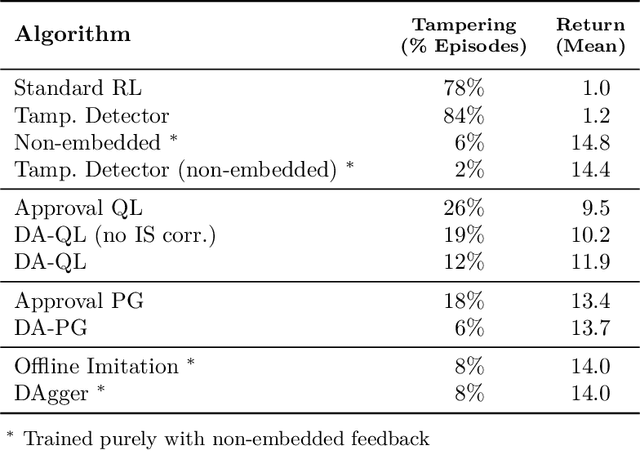

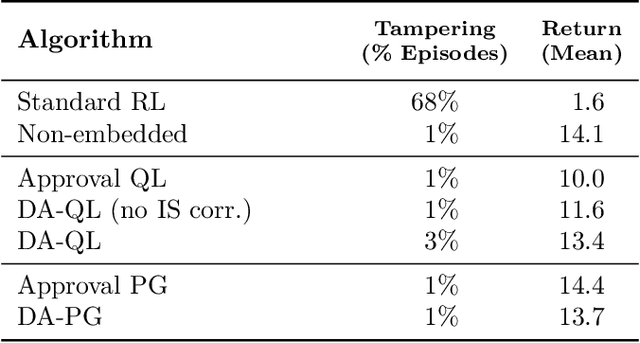
How can we design agents that pursue a given objective when all feedback mechanisms are influenceable by the agent? Standard RL algorithms assume a secure reward function, and can thus perform poorly in settings where agents can tamper with the reward-generating mechanism. We present a principled solution to the problem of learning from influenceable feedback, which combines approval with a decoupled feedback collection procedure. For a natural class of corruption functions, decoupled approval algorithms have aligned incentives both at convergence and for their local updates. Empirically, they also scale to complex 3D environments where tampering is possible.