 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotional Speech-Driven Animation with Content-Emotion Disentanglement
Jun 15, 2023



To be widely adopted, 3D facial avatars need to be animated easily, realistically, and directly, from speech signals. While the best recent methods generate 3D animations that are synchronized with the input audio, they largely ignore the impact of emotions on facial expressions. Instead, their focus is on modeling the correlations between speech and facial motion, resulting in animations that are unemotional or do not match the input emotion. We observe that there are two contributing factors resulting in facial animation - the speech and the emotion. We exploit these insights in EMOTE (Expressive Model Optimized for Talking with Emotion), which generates 3D talking head avatars that maintain lip sync while enabling explicit control over the expression of emotion. Due to the absence of high-quality aligned emotional 3D face datasets with speech, EMOTE is trained from an emotional video dataset (i.e., MEAD). To achieve this, we match speech-content between generated sequences and target videos differently from emotion content. Specifically, we train EMOTE with additional supervision in the form of a lip-reading objective to preserve the speech-dependent content (spatially local and high temporal frequency), while utilizing emotion supervision on a sequence-level (spatially global and low frequency). Furthermore, we employ a content-emotion exchange mechanism in order to supervise different emotion on the same audio, while maintaining the lip motion synchronized with the speech. To employ deep perceptual losses without getting undesirable artifacts, we devise a motion prior in form of a temporal VAE. Extensive qualitative, quantitative, and perceptual evaluations demonstrate that EMOTE produces state-of-the-art speech-driven facial animations, with lip sync on par with the best methods while offering additional, high-quality emotional control.
Instant Multi-View Head Capture through Learnable Registration
Jun 12, 2023



Existing methods for capturing datasets of 3D heads in dense semantic correspondence are slow, and commonly address the problem in two separate steps; multi-view stereo (MVS) reconstruction followed by non-rigid registration. To simplify this process, we introduce TEMPEH (Towards Estimation of 3D Meshes from Performances of Expressive Heads) to directly infer 3D heads in dense correspondence from calibrated multi-view images. Registering datasets of 3D scans typically requires manual parameter tuning to find the right balance between accurately fitting the scans surfaces and being robust to scanning noise and outliers. Instead, we propose to jointly register a 3D head dataset while training TEMPEH. Specifically, during training we minimize a geometric loss commonly used for surface registration, effectively leveraging TEMPEH as a regularizer. Our multi-view head inference builds on a volumetric feature representation that samples and fuses features from each view using camera calibration information. To account for partial occlusions and a large capture volume that enables head movements, we use view- and surface-aware feature fusion, and a spatial transformer-based head localization module, respectively. We use raw MVS scans as supervision during training, but, once trained, TEMPEH directly predicts 3D heads in dense correspondence without requiring scans. Predicting one head takes about 0.3 seconds with a median reconstruction error of 0.26 mm, 64% lower than the current state-of-the-art. This enables the efficient capture of large datasets containing multiple people and diverse facial motions. Code, model, and data are publicly available at https://tempeh.is.tue.mpg.de.
Generating Holistic 3D Human Motion from Speech
Dec 08, 2022



This work addresses the problem of generating 3D holistic body motions from human speech. Given a speech recording, we synthesize sequences of 3D body poses, hand gestures, and facial expressions that are realistic and diverse. To achieve this, we first build a high-quality dataset of 3D holistic body meshes with synchronous speech. We then define a novel speech-to-motion generation framework in which the face, body, and hands are modeled separately. The separated modeling stems from the fact that face articulation strongly correlates with human speech, while body poses and hand gestures are less correlated. Specifically, we employ an autoencoder for face motions, and a compositional vector-quantized variational autoencoder (VQ-VAE) for the body and hand motions. The compositional VQ-VAE is key to generating diverse results. Additionally, we propose a cross-conditional autoregressive model that generates body poses and hand gestures, leading to coherent and realistic motions. Extensive experiments and user studies demonstrate that our proposed approach achieves state-of-the-art performance both qualitatively and quantitatively. Our novel dataset and code will be released for research purposes at https://talkshow.is.tue.mpg.de.
Instant Volumetric Head Avatars
Nov 22, 2022We present Instant Volumetric Head Avatars (INSTA), a novel approach for reconstructing photo-realistic digital avatars instantaneously. INSTA models a dynamic neural radiance field based on neural graphics primitives embedded around a parametric face model. Our pipeline is trained on a single monocular RGB portrait video that observes the subject under different expressions and views. While state-of-the-art methods take up to several days to train an avatar, our method can reconstruct a digital avatar in less than 10 minutes on modern GPU hardware, which is orders of magnitude faster than previous solutions. In addition, it allows for the interactive rendering of novel poses and expressions. By leveraging the geometry prior of the underlying parametric face model, we demonstrate that INSTA extrapolates to unseen poses. In quantitative and qualitative studies on various subjects, INSTA outperforms state-of-the-art methods regarding rendering quality and training time.
SUPR: A Sparse Unified Part-Based Human Representation
Oct 25, 2022Statistical 3D shape models of the head, hands, and fullbody are widely used in computer vision and graphics. Despite their wide use, we show that existing models of the head and hands fail to capture the full range of motion for these parts. Moreover, existing work largely ignores the feet, which are crucial for modeling human movement and have applications in biomechanics, animation, and the footwear industry. The problem is that previous body part models are trained using 3D scans that are isolated to the individual parts. Such data does not capture the full range of motion for such parts, e.g. the motion of head relative to the neck. Our observation is that full-body scans provide important information about the motion of the body parts. Consequently, we propose a new learning scheme that jointly trains a full-body model and specific part models using a federated dataset of full-body and body-part scans. Specifically, we train an expressive human body model called SUPR (Sparse Unified Part-Based Human Representation), where each joint strictly influences a sparse set of model vertices. The factorized representation enables separating SUPR into an entire suite of body part models. Note that the feet have received little attention and existing 3D body models have highly under-actuated feet. Using novel 4D scans of feet, we train a model with an extended kinematic tree that captures the range of motion of the toes. Additionally, feet deform due to ground contact. To model this, we include a novel non-linear deformation function that predicts foot deformation conditioned on the foot pose, shape, and ground contact. We train SUPR on an unprecedented number of scans: 1.2 million body, head, hand and foot scans. We quantitatively compare SUPR and the separated body parts and find that our suite of models generalizes better than existing models. SUPR is available at http://supr.is.tue.mpg.de
Human Body Measurement Estimation with Adversarial Augmentation
Oct 11, 2022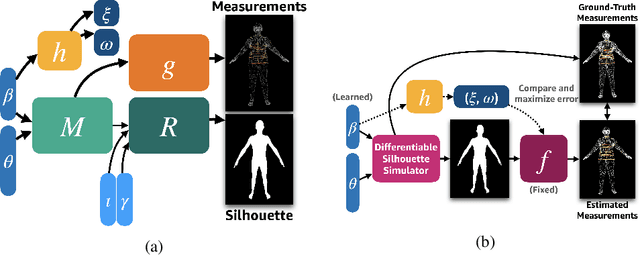
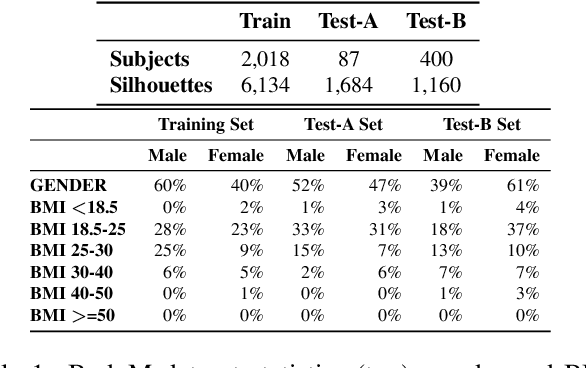
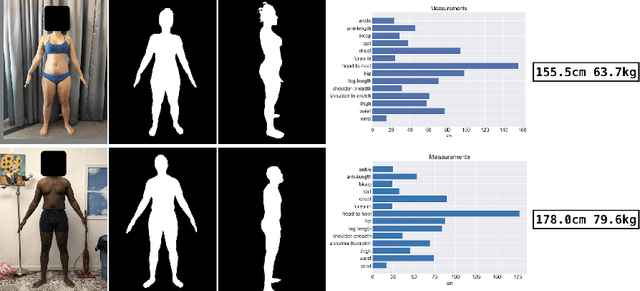
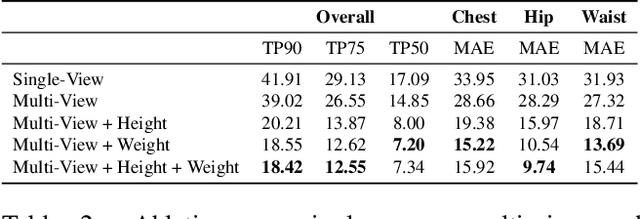
We present a Body Measurement network (BMnet) for estimating 3D anthropomorphic measurements of the human body shape from silhouette images. Training of BMnet is performed on data from real human subjects, and augmented with a novel adversarial body simulator (ABS) that finds and synthesizes challenging body shapes. ABS is based on the skinned multiperson linear (SMPL) body model, and aims to maximize BMnet measurement prediction error with respect to latent SMPL shape parameters. ABS is fully differentiable with respect to these parameters, and trained end-to-end via backpropagation with BMnet in the loop. Experiments show that ABS effectively discovers adversarial examples, such as bodies with extreme body mass indices (BMI), consistent with the rarity of extreme-BMI bodies in BMnet's training set. Thus ABS is able to reveal gaps in training data and potential failures in predicting under-represented body shapes. Results show that training BMnet with ABS improves measurement prediction accuracy on real bodies by up to 10%, when compared to no augmentation or random body shape sampling. Furthermore, our method significantly outperforms SOTA measurement estimation methods by as much as 3x. Finally, we release BodyM, the first challenging, large-scale dataset of photo silhouettes and body measurements of real human subjects, to further promote research in this area. Project website: https://adversarialbodysim.github.io
Capturing and Animation of Body and Clothing from Monocular Video
Oct 04, 2022
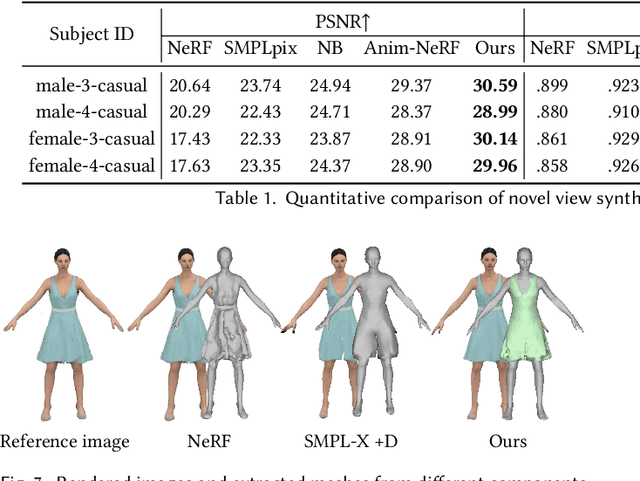
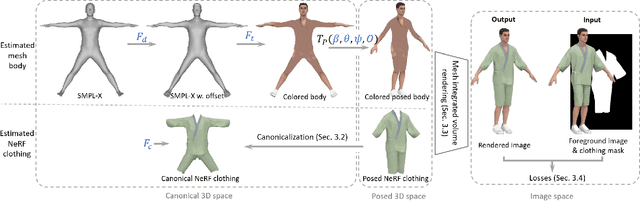
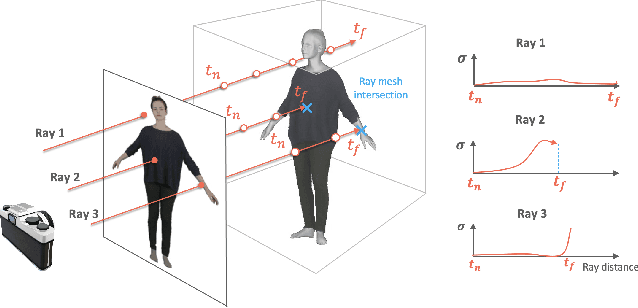
While recent work has shown progress on extracting clothed 3D human avatars from a single image, video, or a set of 3D scans, several limitations remain. Most methods use a holistic representation to jointly model the body and clothing, which means that the clothing and body cannot be separated for applications like virtual try-on. Other methods separately model the body and clothing, but they require training from a large set of 3D clothed human meshes obtained from 3D/4D scanners or physics simulations. Our insight is that the body and clothing have different modeling requirements. While the body is well represented by a mesh-based parametric 3D model, implicit representations and neural radiance fields are better suited to capturing the large variety in shape and appearance present in clothing. Building on this insight, we propose SCARF (Segmented Clothed Avatar Radiance Field), a hybrid model combining a mesh-based body with a neural radiance field. Integrating the mesh into the volumetric rendering in combination with a differentiable rasterizer enables us to optimize SCARF directly from monocular videos, without any 3D supervision. The hybrid modeling enables SCARF to (i) animate the clothed body avatar by changing body poses (including hand articulation and facial expressions), (ii) synthesize novel views of the avatar, and (iii) transfer clothing between avatars in virtual try-on applications. We demonstrate that SCARF reconstructs clothing with higher visual quality than existing methods, that the clothing deforms with changing body pose and body shape, and that clothing can be successfully transferred between avatars of different subjects. The code and models are available at https://github.com/YadiraF/SCARF.
Towards Racially Unbiased Skin Tone Estimation via Scene Disambiguation
May 08, 2022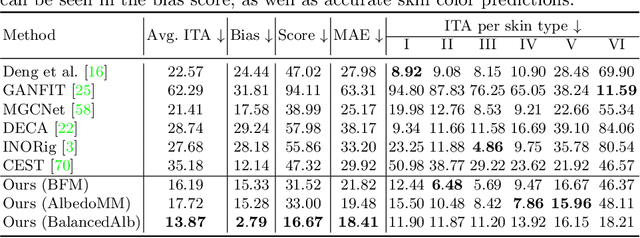
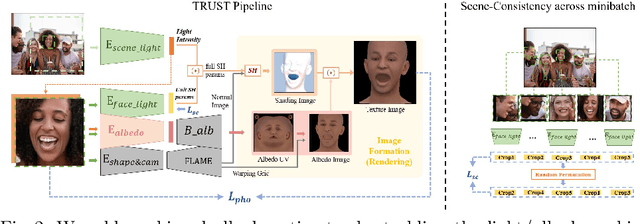
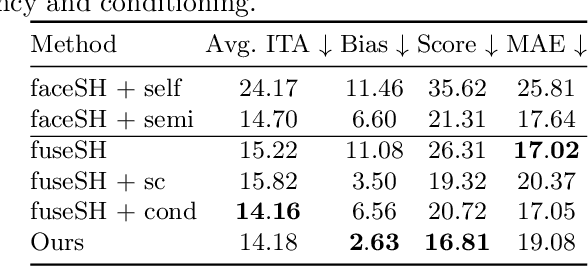

Virtual facial avatars will play an increasingly important role in immersive communication, games and the metaverse, and it is therefore critical that they be inclusive. This requires accurate recovery of the appearance, represented by albedo, regardless of age, sex, or ethnicity. While significant progress has been made on estimating 3D facial geometry, albedo estimation has received less attention. The task is fundamentally ambiguous because the observed color is a function of albedo and lighting, both of which are unknown. We find that current methods are biased towards light skin tones due to (1) strongly biased priors that prefer lighter pigmentation and (2) algorithmic solutions that disregard the light/albedo ambiguity. To address this, we propose a new evaluation dataset (FAIR) and an algorithm (TRUST) to improve albedo estimation and, hence, fairness. Specifically, we create the first facial albedo evaluation benchmark where subjects are balanced in terms of skin color, and measure accuracy using the Individual Typology Angle (ITA) metric. We then address the light/albedo ambiguity by building on a key observation: the image of the full scene -- as opposed to a cropped image of the face -- contains important information about lighting that can be used for disambiguation. TRUST regresses facial albedo by conditioning both on the face region and a global illumination signal obtained from the scene image. Our experimental results show significant improvement compared to state-of-the-art methods on albedo estimation, both in terms of accuracy and fairness. The evaluation benchmark and code will be made available for research purposes at https://trust.is.tue.mpg.de.
EMOCA: Emotion Driven Monocular Face Capture and Animation
Apr 24, 2022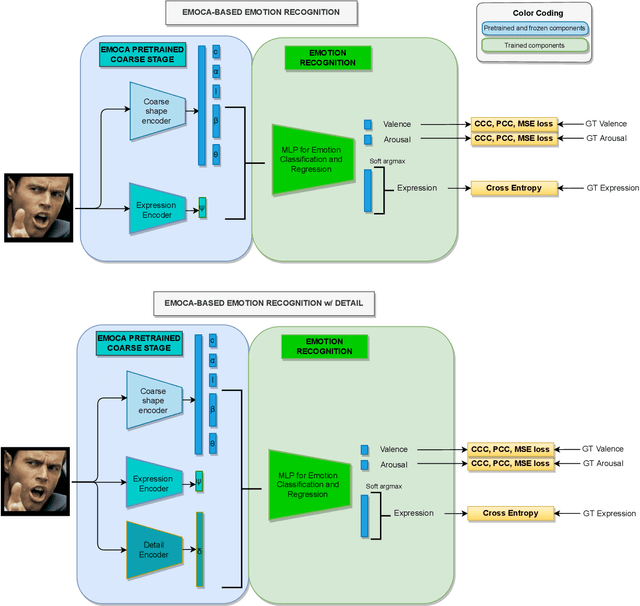
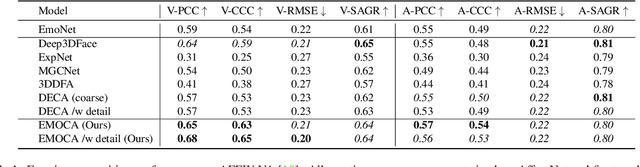
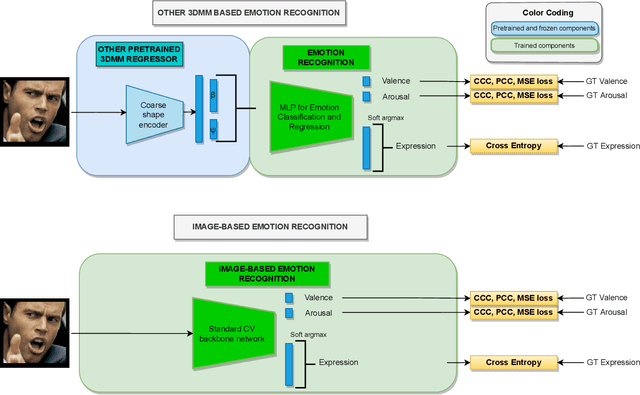
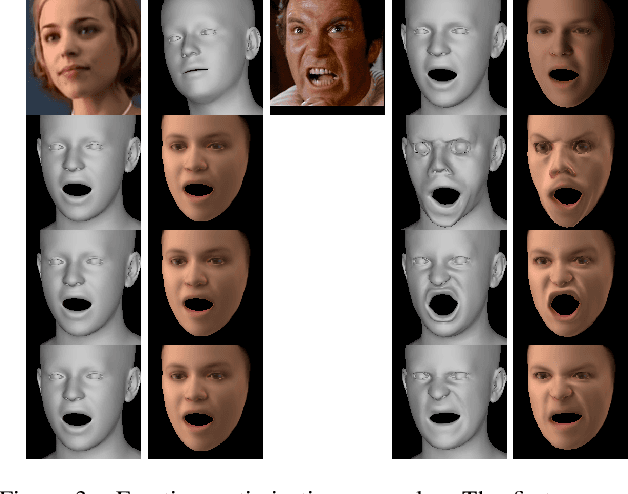
As 3D facial avatars become more widely used for communication, it is critical that they faithfully convey emotion. Unfortunately, the best recent methods that regress parametric 3D face models from monocular images are unable to capture the full spectrum of facial expression, such as subtle or extreme emotions. We find the standard reconstruction metrics used for training (landmark reprojection error, photometric error, and face recognition loss) are insufficient to capture high-fidelity expressions. The result is facial geometries that do not match the emotional content of the input image. We address this with EMOCA (EMOtion Capture and Animation), by introducing a novel deep perceptual emotion consistency loss during training, which helps ensure that the reconstructed 3D expression matches the expression depicted in the input image. While EMOCA achieves 3D reconstruction errors that are on par with the current best methods, it significantly outperforms them in terms of the quality of the reconstructed expression and the perceived emotional content. We also directly regress levels of valence and arousal and classify basic expressions from the estimated 3D face parameters. On the task of in-the-wild emotion recognition, our purely geometric approach is on par with the best image-based methods, highlighting the value of 3D geometry in analyzing human behavior. The model and code are publicly available at https://emoca.is.tue.mpg.de.
Towards Metrical Reconstruction of Human Faces
Apr 13, 2022
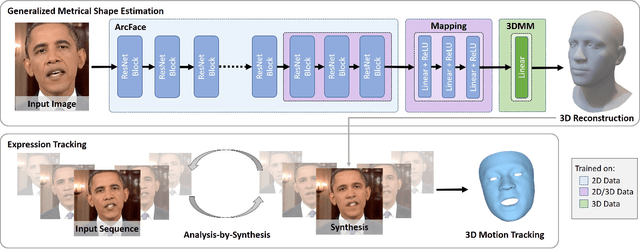
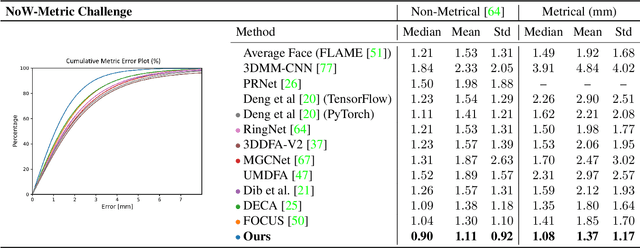
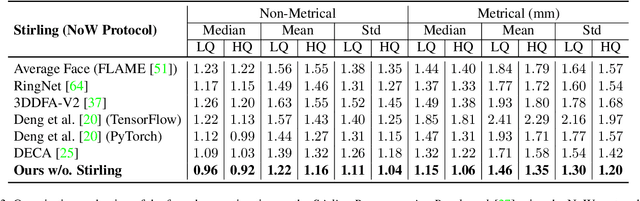
Face reconstruction and tracking is a building block of numerous applications in AR/VR, human-machine interaction, as well as medical applications. Most of these applications rely on a metrically correct prediction of the shape, especially, when the reconstructed subject is put into a metrical context (i.e., when there is a reference object of known size). A metrical reconstruction is also needed for any application that measures distances and dimensions of the subject (e.g., to virtually fit a glasses frame). State-of-the-art methods for face reconstruction from a single image are trained on large 2D image datasets in a self-supervised fashion. However, due to the nature of a perspective projection they are not able to reconstruct the actual face dimensions, and even predicting the average human face outperforms some of these methods in a metrical sense. To learn the actual shape of a face, we argue for a supervised training scheme. Since there exists no large-scale 3D dataset for this task, we annotated and unified small- and medium-scale databases. The resulting unified dataset is still a medium-scale dataset with more than 2k identities and training purely on it would lead to overfitting. To this end, we take advantage of a face recognition network pretrained on a large-scale 2D image dataset, which provides distinct features for different faces and is robust to expression, illumination, and camera changes. Using these features, we train our face shape estimator in a supervised fashion, inheriting the robustness and generalization of the face recognition network. Our method, which we call MICA (MetrIC fAce), outperforms the state-of-the-art reconstruction methods by a large margin, both on current non-metric benchmarks as well as on our metric benchmarks (15% and 24% lower average error on NoW, respectively).