 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Model Selection for Time Series Forecasting
Feb 17, 2022



Research on time series forecasting has predominantly focused on developing methods that improve accuracy. However, other criteria such as training time or latency are critical in many real-world applications. We therefore address the question of how to choose an appropriate forecasting model for a given dataset among the plethora of available forecasting methods when accuracy is only one of many criteria. For this, our contributions are two-fold. First, we present a comprehensive benchmark, evaluating 7 classical and 6 deep learning forecasting methods on 44 heterogeneous, publicly available datasets. The benchmark code is open-sourced along with evaluations and forecasts for all methods. These evaluations enable us to answer open questions such as the amount of data required for deep learning models to outperform classical ones. Second, we leverage the benchmark evaluations to learn good defaults that consider multiple objectives such as accuracy and latency. By learning a mapping from forecasting models to performance metrics, we show that our method PARETOSELECT is able to accurately select models from the Pareto front -- alleviating the need to train or evaluate many forecasting models for model selection. To the best of our knowledge, PARETOSELECT constitutes the first method to learn default models in a multi-objective setting.
Online false discovery rate control for anomaly detection in time series
Dec 06, 2021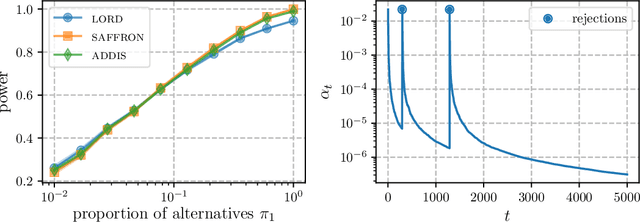
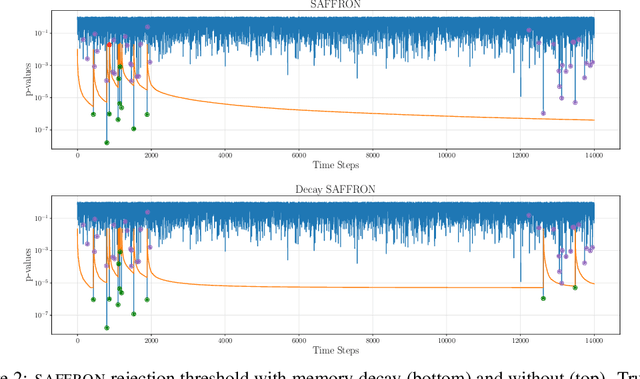
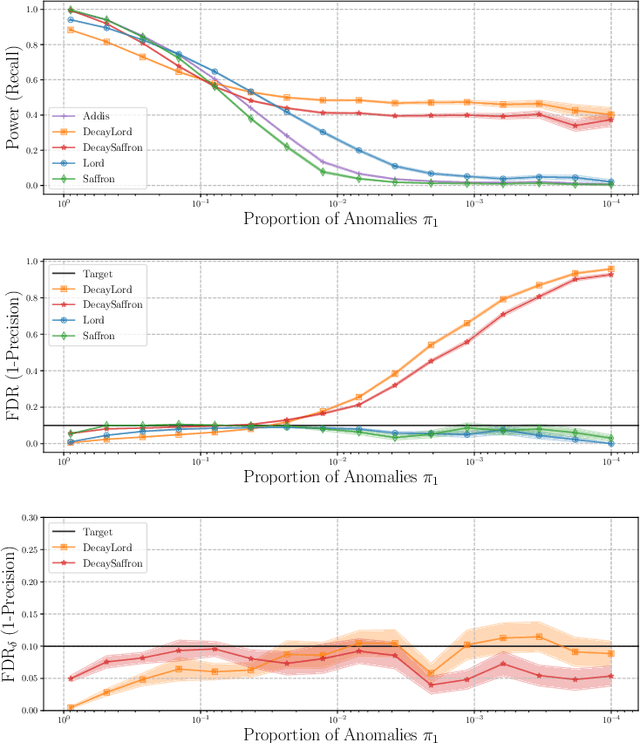
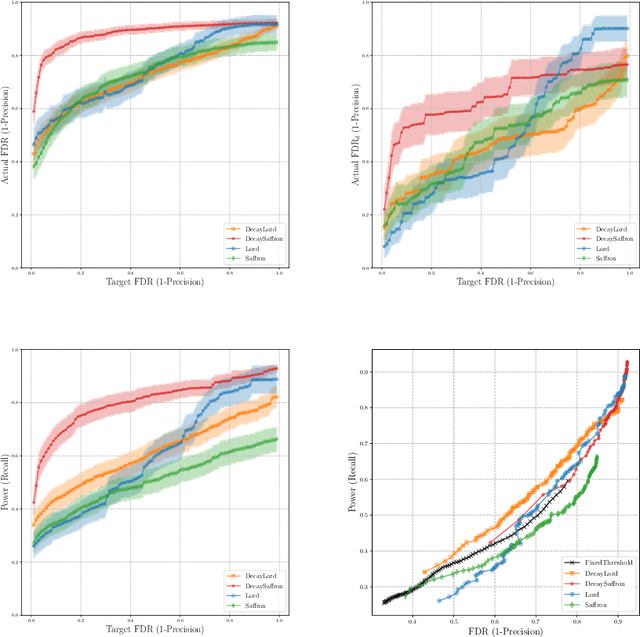
This article proposes novel rules for false discovery rate control (FDRC) geared towards online anomaly detection in time series. Online FDRC rules allow to control the properties of a sequence of statistical tests. In the context of anomaly detection, the null hypothesis is that an observation is normal and the alternative is that it is anomalous. FDRC rules allow users to target a lower bound on precision in unsupervised settings. The methods proposed in this article overcome short-comings of previous FDRC rules in the context of anomaly detection, in particular ensuring that power remains high even when the alternative is exceedingly rare (typical in anomaly detection) and the test statistics are serially dependent (typical in time series). We show the soundness of these rules in both theory and experiments.
Meta-Forecasting by combining Global Deep Representations with Local Adaptation
Nov 12, 2021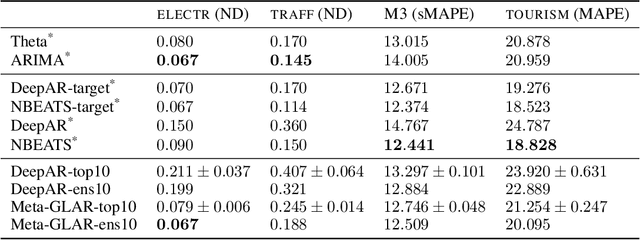
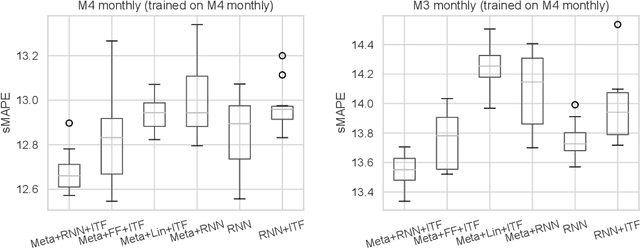
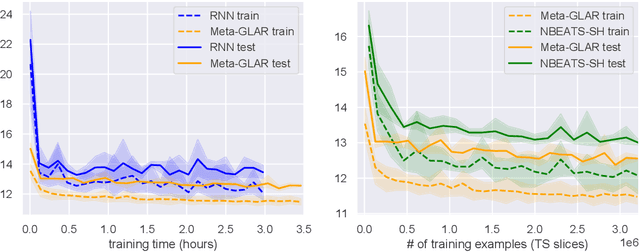

While classical time series forecasting considers individual time series in isolation, recent advances based on deep learning showed that jointly learning from a large pool of related time series can boost the forecasting accuracy. However, the accuracy of these methods suffers greatly when modeling out-of-sample time series, significantly limiting their applicability compared to classical forecasting methods. To bridge this gap, we adopt a meta-learning view of the time series forecasting problem. We introduce a novel forecasting method, called Meta Global-Local Auto-Regression (Meta-GLAR), that adapts to each time series by learning in closed-form the mapping from the representations produced by a recurrent neural network (RNN) to one-step-ahead forecasts. Crucially, the parameters ofthe RNN are learned across multiple time series by backpropagating through the closed-form adaptation mechanism. In our extensive empirical evaluation we show that our method is competitive with the state-of-the-art in out-of-sample forecasting accuracy reported in earlier work.
Deep Explicit Duration Switching Models for Time Series
Oct 26, 2021



Many complex time series can be effectively subdivided into distinct regimes that exhibit persistent dynamics. Discovering the switching behavior and the statistical patterns in these regimes is important for understanding the underlying dynamical system. We propose the Recurrent Explicit Duration Switching Dynamical System (RED-SDS), a flexible model that is capable of identifying both state- and time-dependent switching dynamics. State-dependent switching is enabled by a recurrent state-to-switch connection and an explicit duration count variable is used to improve the time-dependent switching behavior. We demonstrate how to perform efficient inference using a hybrid algorithm that approximates the posterior of the continuous states via an inference network and performs exact inference for the discrete switches and counts. The model is trained by maximizing a Monte Carlo lower bound of the marginal log-likelihood that can be computed efficiently as a byproduct of the inference routine. Empirical results on multiple datasets demonstrate that RED-SDS achieves considerable improvement in time series segmentation and competitive forecasting performance against the state of the art.
Neural Flows: Efficient Alternative to Neural ODEs
Oct 25, 2021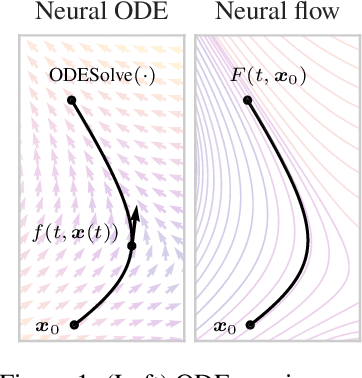
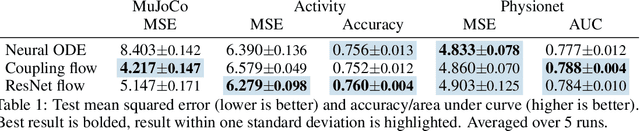
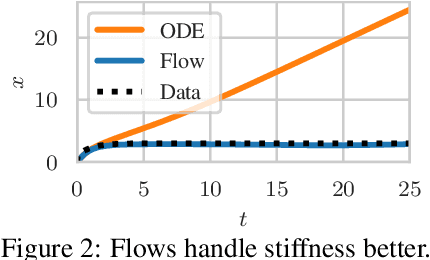
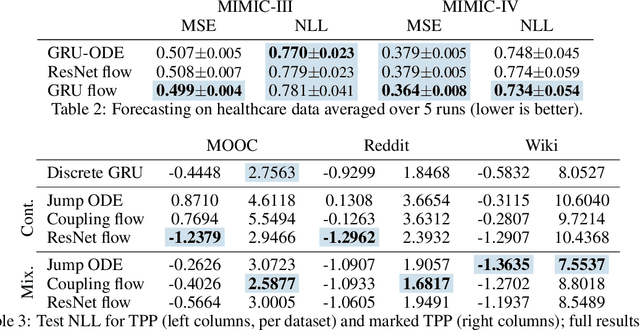
Neural ordinary differential equations describe how values change in time. This is the reason why they gained importance in modeling sequential data, especially when the observations are made at irregular intervals. In this paper we propose an alternative by directly modeling the solution curves - the flow of an ODE - with a neural network. This immediately eliminates the need for expensive numerical solvers while still maintaining the modeling capability of neural ODEs. We propose several flow architectures suitable for different applications by establishing precise conditions on when a function defines a valid flow. Apart from computational efficiency, we also provide empirical evidence of favorable generalization performance via applications in time series modeling, forecasting, and density estimation.
A Study of Joint Graph Inference and Forecasting
Sep 10, 2021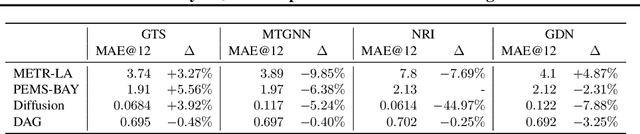
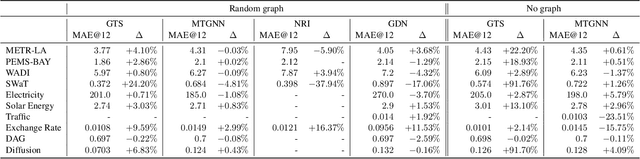
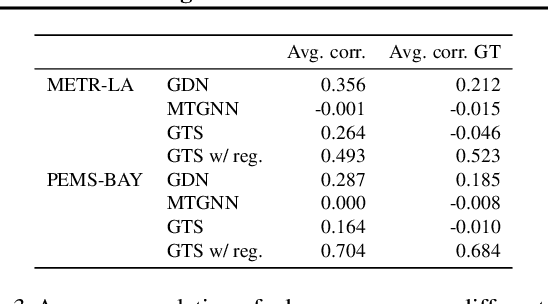
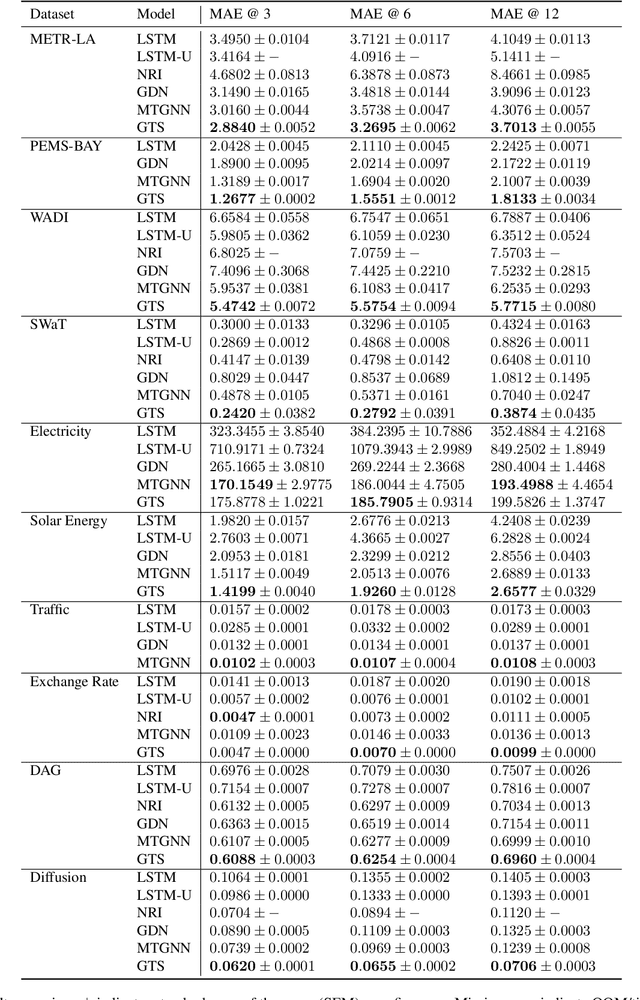
We study a recent class of models which uses graph neural networks (GNNs) to improve forecasting in multivariate time series. The core assumption behind these models is that there is a latent graph between the time series (nodes) that governs the evolution of the multivariate time series. By parameterizing a graph in a differentiable way, the models aim to improve forecasting quality. We compare four recent models of this class on the forecasting task. Further, we perform ablations to study their behavior under changing conditions, e.g., when disabling the graph-learning modules and providing the ground-truth relations instead. Based on our findings, we propose novel ways of combining the existing architectures.
Detecting Anomalous Event Sequences with Temporal Point Processes
Jun 08, 2021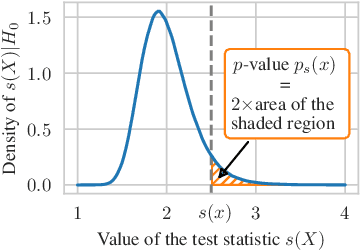
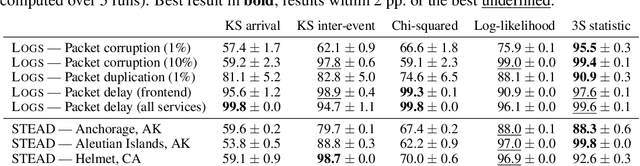
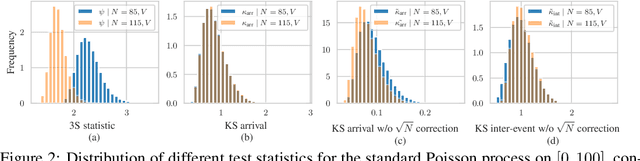
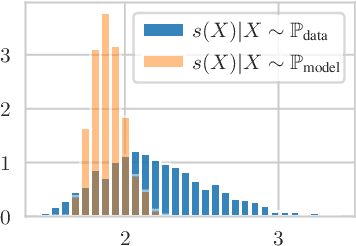
Automatically detecting anomalies in event data can provide substantial value in domains such as healthcare, DevOps, and information security. In this paper, we frame the problem of detecting anomalous continuous-time event sequences as out-of-distribution (OoD) detection for temporal point processes (TPPs). First, we show how this problem can be approached using goodness-of-fit (GoF) tests. We then demonstrate the limitations of popular GoF statistics for TPPs and propose a new test that addresses these shortcomings. The proposed method can be combined with various TPP models, such as neural TPPs, and is easy to implement. In our experiments, we show that the proposed statistic excels at both traditional GoF testing, as well as at detecting anomalies in simulated and real-world data.
Neural Temporal Point Processes: A Review
Apr 27, 2021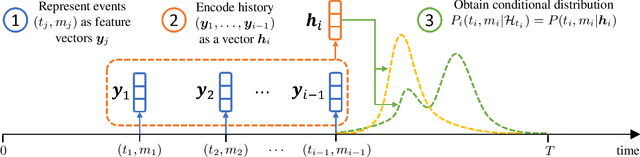
Temporal point processes (TPP) are probabilistic generative models for continuous-time event sequences. Neural TPPs combine the fundamental ideas from point process literature with deep learning approaches, thus enabling construction of flexible and efficient models. The topic of neural TPPs has attracted significant attention in the recent years, leading to the development of numerous new architectures and applications for this class of models. In this review paper we aim to consolidate the existing body of knowledge on neural TPPs. Specifically, we focus on important design choices and general principles for defining neural TPP models. Next, we provide an overview of application areas commonly considered in the literature. We conclude this survey with the list of open challenges and important directions for future work in the field of neural TPPs.
Intermittent Demand Forecasting with Renewal Processes
Oct 04, 2020
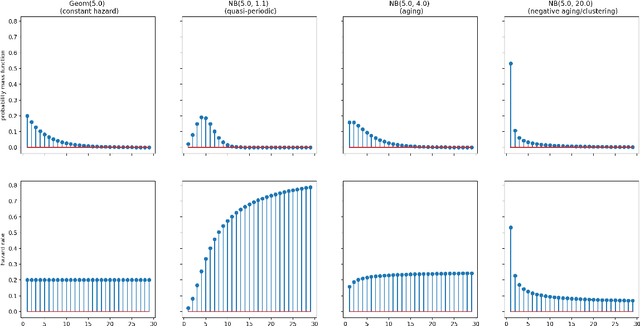

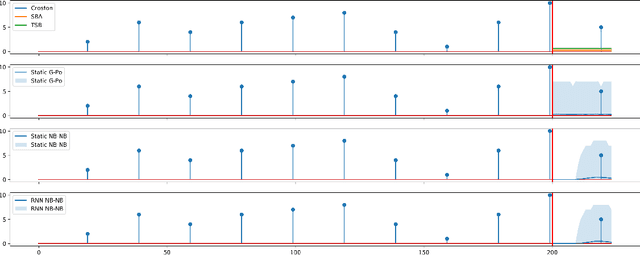
Intermittency is a common and challenging problem in demand forecasting. We introduce a new, unified framework for building intermittent demand forecasting models, which incorporates and allows to generalize existing methods in several directions. Our framework is based on extensions of well-established model-based methods to discrete-time renewal processes, which can parsimoniously account for patterns such as aging, clustering and quasi-periodicity in demand arrivals. The connection to discrete-time renewal processes allows not only for a principled extension of Croston-type models, but also for an natural inclusion of neural network based models---by replacing exponential smoothing with a recurrent neural network. We also demonstrate that modeling continuous-time demand arrivals, i.e., with a temporal point process, is possible via a trivial extension of our framework. This leads to more flexible modeling in scenarios where data of individual purchase orders are directly available with granular timestamps. Complementing this theoretical advancement, we demonstrate the efficacy of our framework for forecasting practice via an extensive empirical study on standard intermittent demand data sets, in which we report predictive accuracy in a variety of scenarios that compares favorably to the state of the art.
A simple and effective predictive resource scaling heuristic for large-scale cloud applications
Aug 03, 2020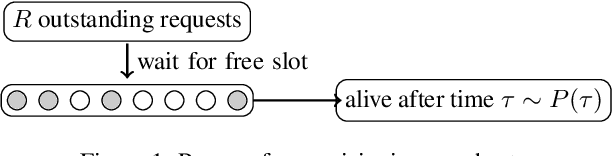
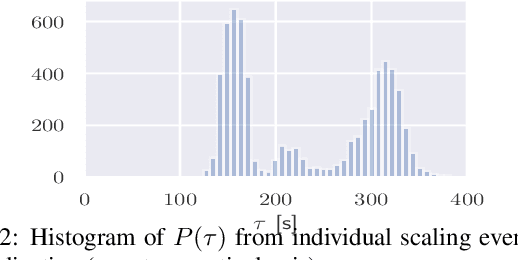
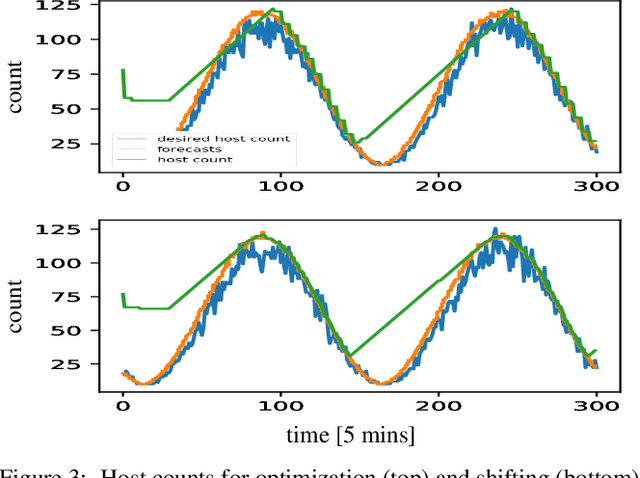
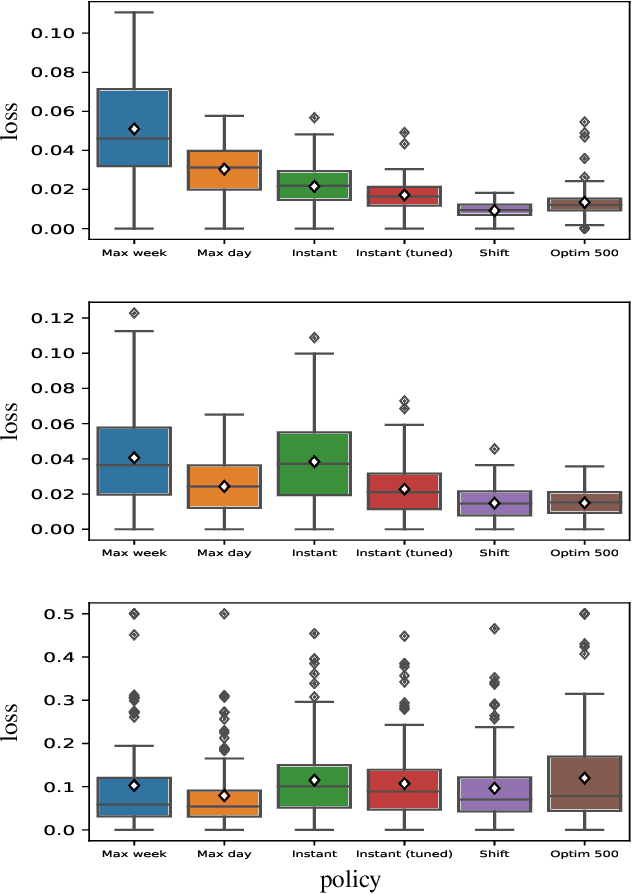
We propose a simple yet effective policy for the predictive auto-scaling of horizontally scalable applications running in cloud environments, where compute resources can only be added with a delay, and where the deployment throughput is limited. Our policy uses a probabilistic forecast of the workload to make scaling decisions dependent on the risk aversion of the application owner. We show in our experiments using real-world and synthetic data that this policy compares favorably to mathematically more sophisticated approaches as well as to simple benchmark policies.