 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription of Corner Cases in Automated Driving: Goals and Challenges
Sep 28, 2021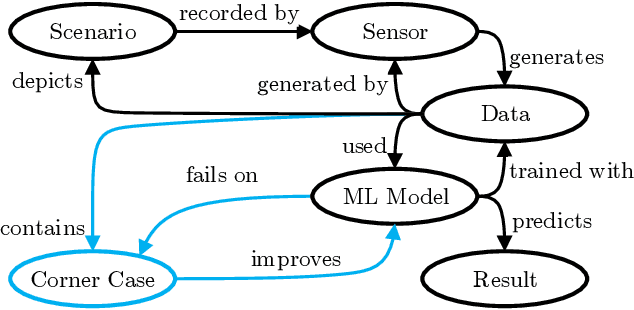


Scaling the distribution of automated vehicles requires handling various unexpected and possibly dangerous situations, termed corner cases (CC). Since many modules of automated driving systems are based on machine learning (ML), CC are an essential part of the data for their development. However, there is only a limited amount of CC data in large-scale data collections, which makes them challenging in the context of ML. With a better understanding of CC, offline applications, e.g., dataset analysis, and online methods, e.g., improved performance of automated driving systems, can be improved. While there are knowledge-based descriptions and taxonomies for CC, there is little research on machine-interpretable descriptions. In this extended abstract, we will give a brief overview of the challenges and goals of such a description.
Deep Residual Echo Suppression and Noise Reduction: A Multi-Input FCRN Approach in a Hybrid Speech Enhancement System
Aug 06, 2021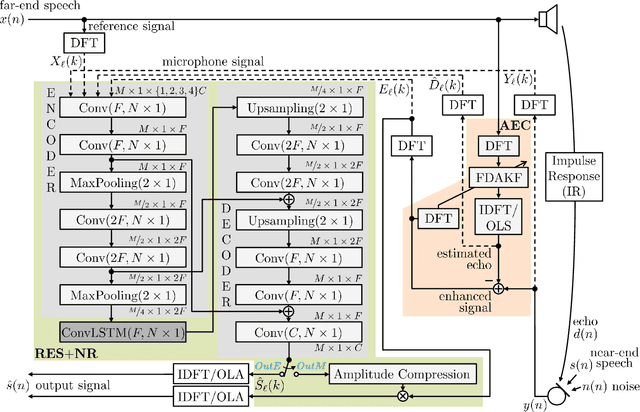
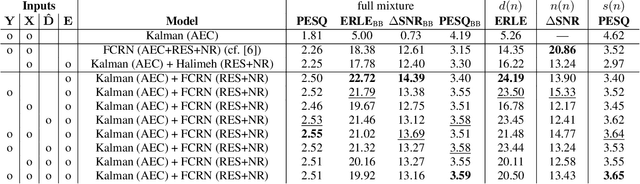
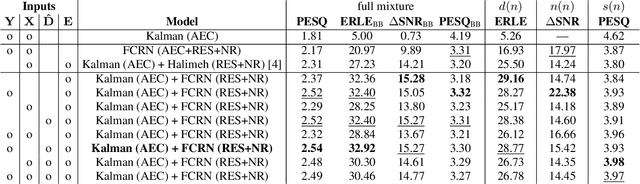
Deep neural network (DNN)-based approaches to acoustic echo cancellation (AEC) and hybrid speech enhancement systems have gained increasing attention recently, introducing significant performance improvements to this research field. Using the fully convolutional recurrent network (FCRN) architecture that is among state of the art topologies for noise reduction, we present a novel deep residual echo suppression and noise reduction with up to four input signals as part of a hybrid speech enhancement system with a linear frequency domain adaptive Kalman filter AEC. In an extensive ablation study, we reveal trade-offs with regard to echo suppression, noise reduction, and near-end speech quality, and provide surprising insights to the choice of the FCRN inputs: In contrast to often seen input combinations for this task, we propose not to use the loudspeaker reference signal, but the enhanced signal after AEC, the microphone signal, and the echo estimate, yielding improvements over previous approaches by more than 0.2 PESQ points.
Relaxed Attention: A Simple Method to Boost Performance of End-to-End Automatic Speech Recognition
Jul 02, 2021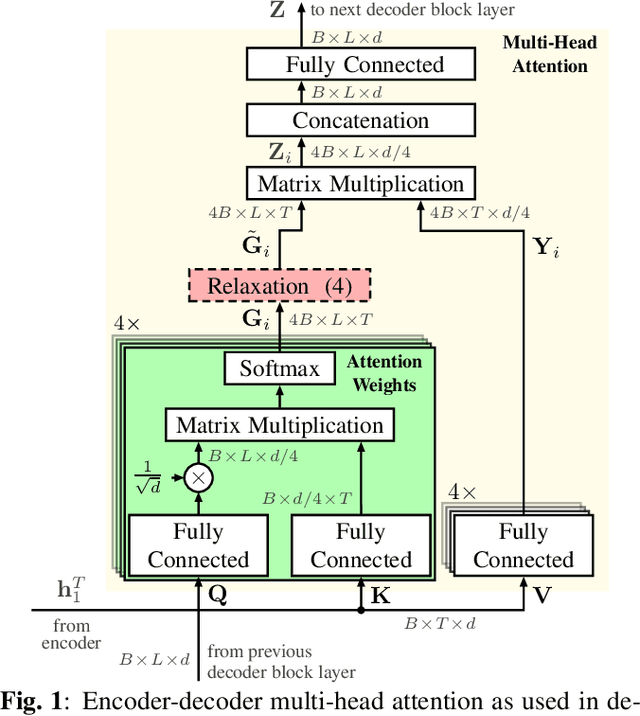
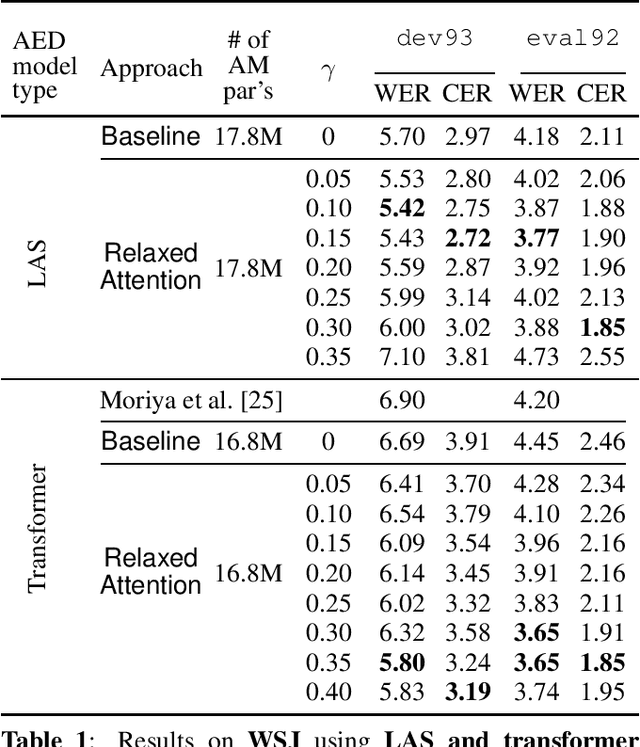
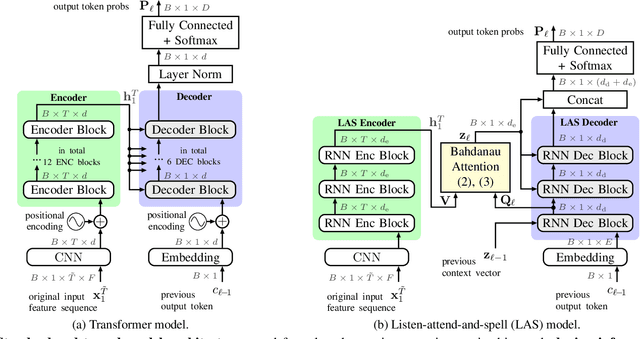
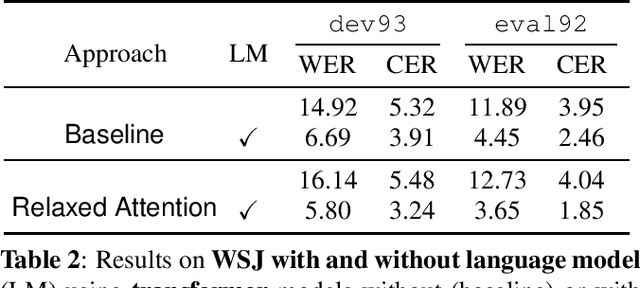
Recently, attention-based encoder-decoder (AED) models have shown high performance for end-to-end automatic speech recognition (ASR) across several tasks. Addressing overconfidence in such models, in this paper we introduce the concept of relaxed attention, which is a simple gradual injection of a uniform distribution to the encoder-decoder attention weights during training that is easily implemented with two lines of code. We investigate the effect of relaxed attention across different AED model architectures and two prominent ASR tasks, Wall Street Journal (WSJ) and Librispeech. We found that transformers trained with relaxed attention outperform the standard baseline models consistently during decoding with external language models. On WSJ, we set a new benchmark for transformer-based end-to-end speech recognition with a word error rate of 3.65%, outperforming state of the art (4.20%) by 13.1% relative, while introducing only a single hyperparameter. Upon acceptance, models will be published on github.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.
Improving Online Performance Prediction for Semantic Segmentation
Apr 12, 2021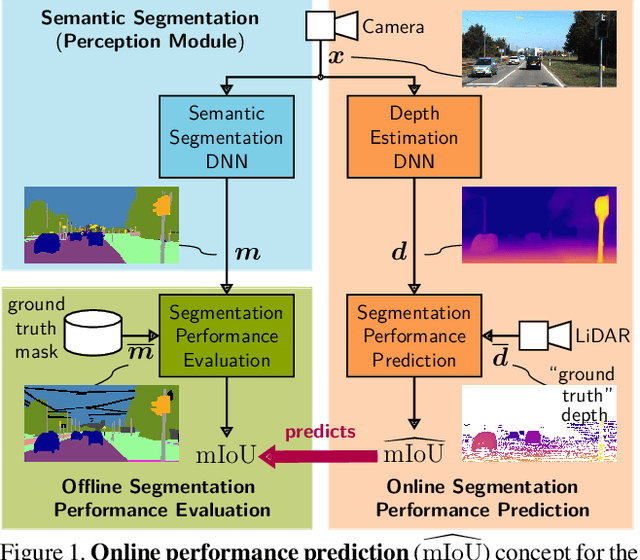
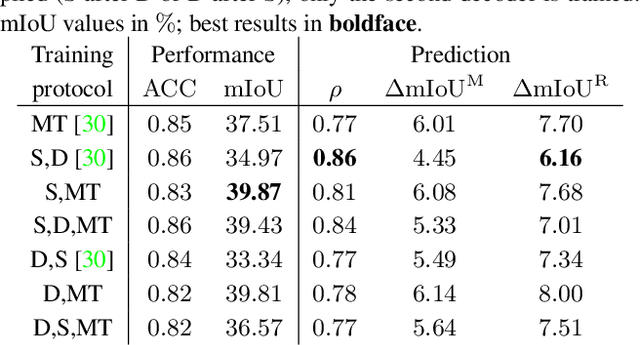
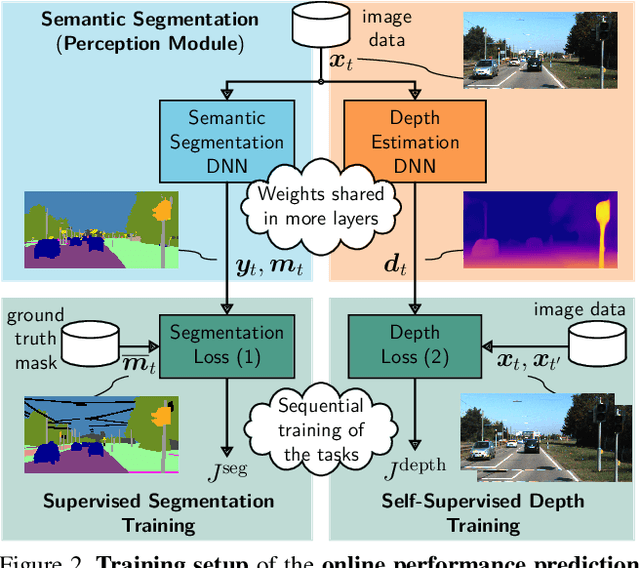
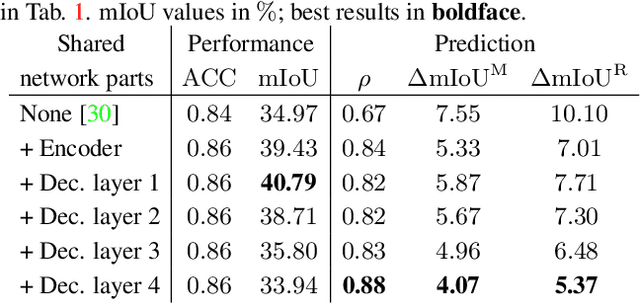
In this work we address the task of observing the performance of a semantic segmentation deep neural network (DNN) during online operation, i.e., during inference, which is of high importance in safety-critical applications such as autonomous driving. Here, many high-level decisions rely on such DNNs, which are usually evaluated offline, while their performance in online operation remains unknown. To solve this problem, we propose an improved online performance prediction scheme, building on a recently proposed concept of predicting the primary semantic segmentation task's performance. This can be achieved by evaluating the auxiliary task of monocular depth estimation with a measurement supplied by a LiDAR sensor and a subsequent regression to the semantic segmentation performance. In particular, we propose (i) sequential training methods for both tasks in a multi-task training setup, (ii) to share the encoder as well as parts of the decoder between both task's networks for improved efficiency, and (iii) a temporal statistics aggregation method, which significantly reduces the performance prediction error at the cost of a small algorithmic latency. Evaluation on the KITTI dataset shows that all three aspects improve the performance prediction compared to previous approaches.
SVDistNet: Self-Supervised Near-Field Distance Estimation on Surround View Fisheye Cameras
Apr 09, 2021
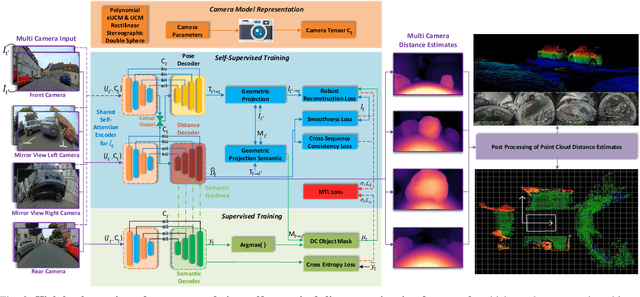
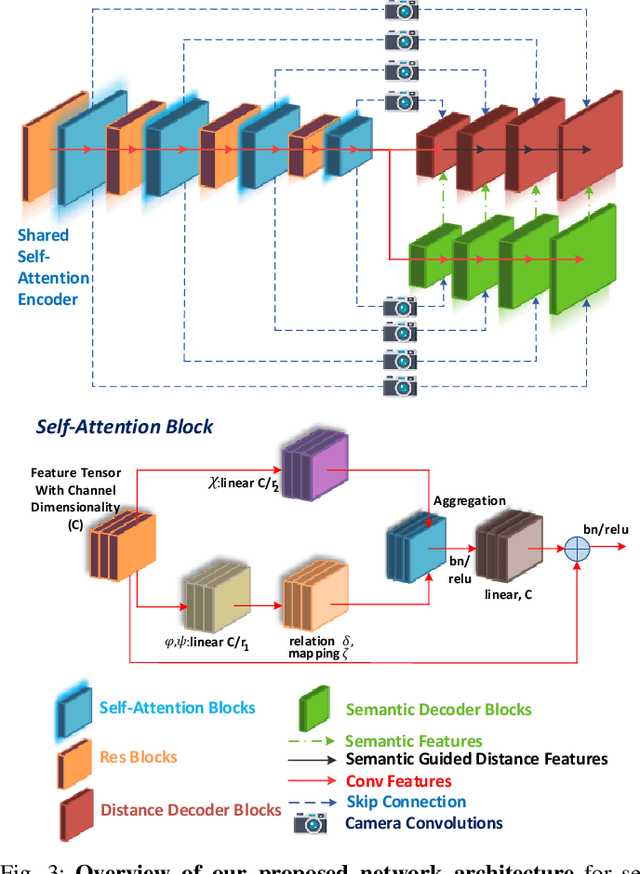

A 360{\deg} perception of scene geometry is essential for automated driving, notably for parking and urban driving scenarios. Typically, it is achieved using surround-view fisheye cameras, focusing on the near-field area around the vehicle. The majority of current depth estimation approaches focus on employing just a single camera, which cannot be straightforwardly generalized to multiple cameras. The depth estimation model must be tested on a variety of cameras equipped to millions of cars with varying camera geometries. Even within a single car, intrinsics vary due to manufacturing tolerances. Deep learning models are sensitive to these changes, and it is practically infeasible to train and test on each camera variant. As a result, we present novel camera-geometry adaptive multi-scale convolutions which utilize the camera parameters as a conditional input, enabling the model to generalize to previously unseen fisheye cameras. Additionally, we improve the distance estimation by pairwise and patchwise vector-based self-attention encoder networks. We evaluate our approach on the Fisheye WoodScape surround-view dataset, significantly improving over previous approaches. We also show a generalization of our approach across different camera viewing angles and perform extensive experiments to support our contributions. To enable comparison with other approaches, we evaluate the front camera data on the KITTI dataset (pinhole camera images) and achieve state-of-the-art performance among self-supervised monocular methods. An overview video with qualitative results is provided at https://youtu.be/bmX0UcU9wtA. Baseline code and dataset will be made public.
Multi-Encoder Learning and Stream Fusion for Transformer-Based End-to-End Automatic Speech Recognition
Mar 31, 2021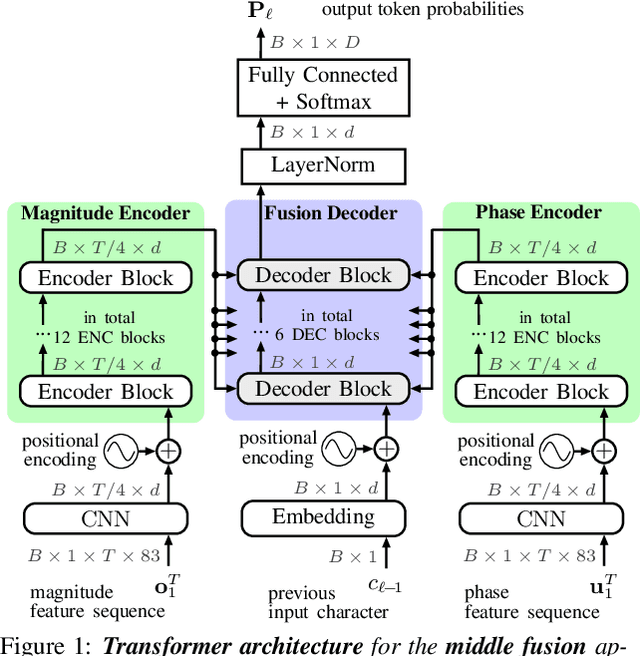
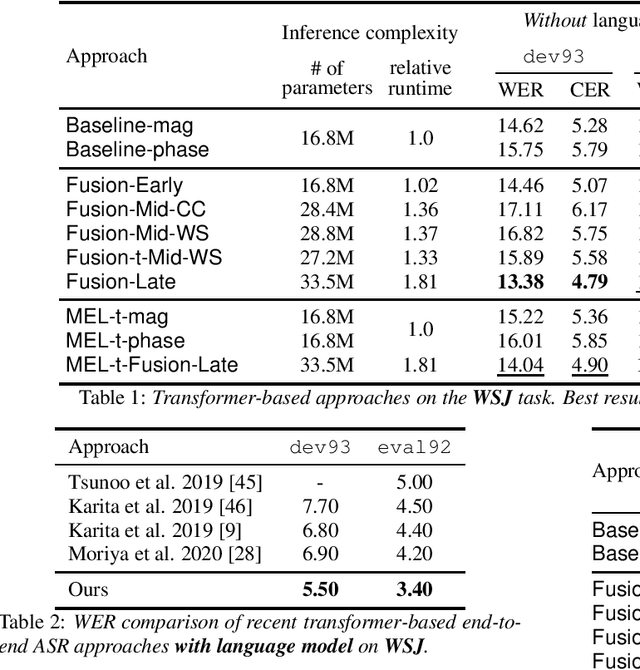
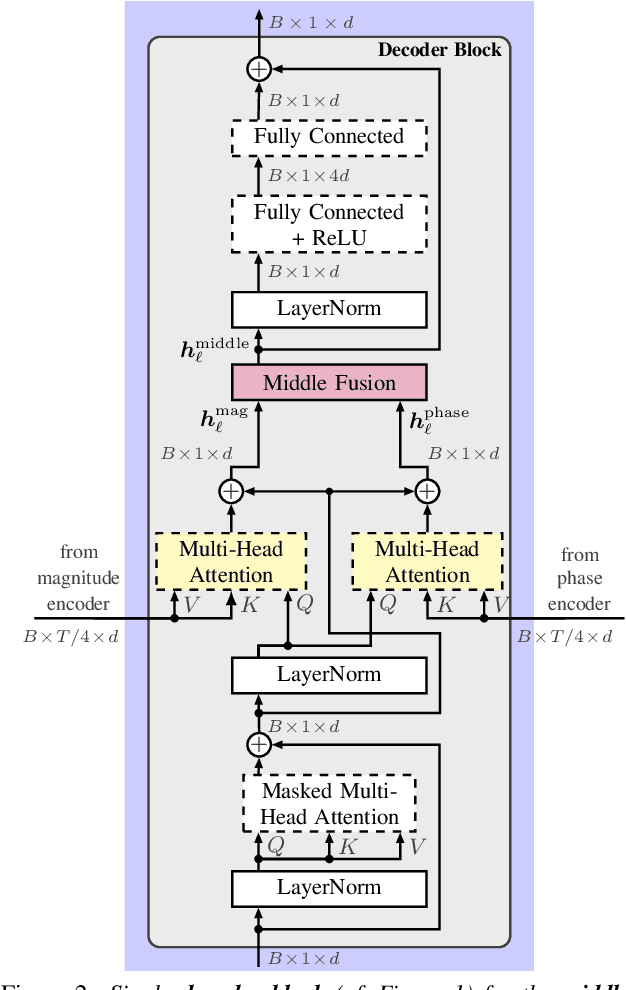
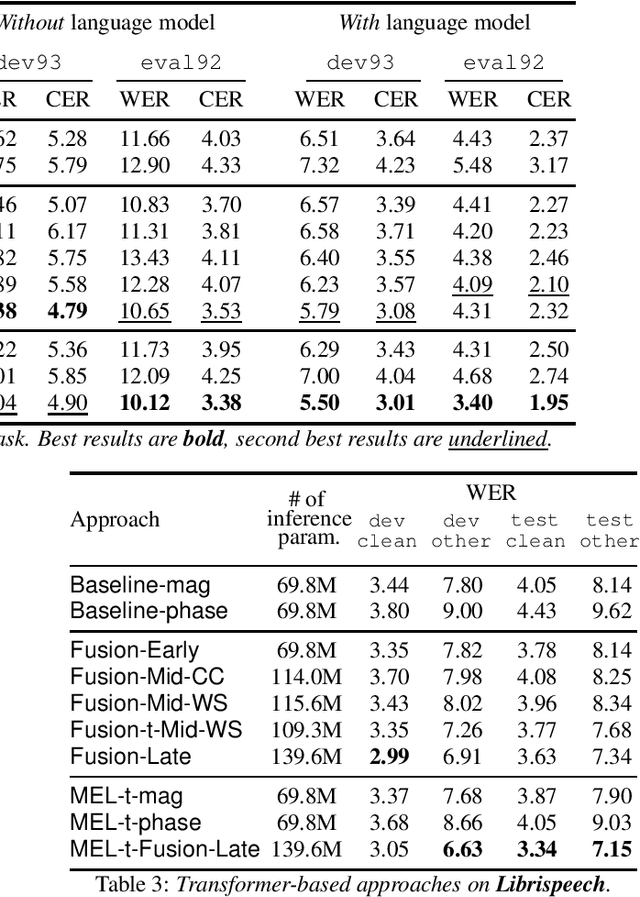
Stream fusion, also known as system combination, is a common technique in automatic speech recognition for traditional hybrid hidden Markov model approaches, yet mostly unexplored for modern deep neural network end-to-end model architectures. Here, we investigate various fusion techniques for the all-attention-based encoder-decoder architecture known as the transformer, striving to achieve optimal fusion by investigating different fusion levels in an example single-microphone setting with fusion of standard magnitude and phase features. We introduce a novel multi-encoder learning method that performs a weighted combination of two encoder-decoder multi-head attention outputs only during training. Employing then only the magnitude feature encoder in inference, we are able to show consistent improvement on Wall Street Journal (WSJ) with language model and on Librispeech, without increase in runtime or parameters. Combining two such multi-encoder trained models by a simple late fusion in inference, we achieve state-of-the-art performance for transformer-based models on WSJ with a significant WER reduction of 19\% relative compared to the current benchmark approach.
Y$^2$-Net FCRN for Acoustic Echo and Noise Suppression
Mar 31, 2021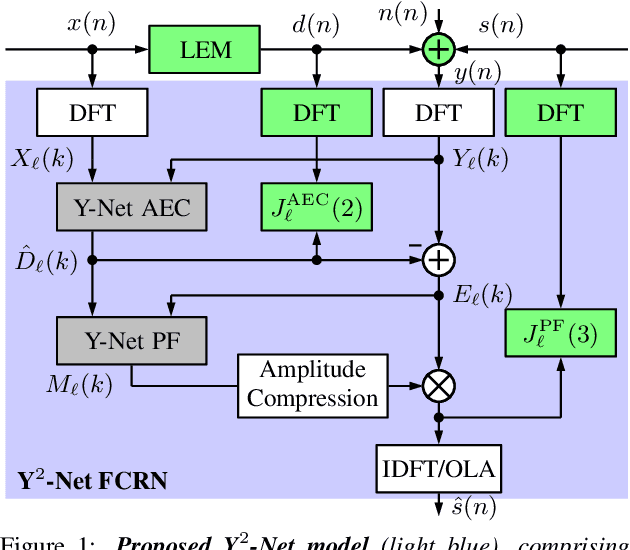
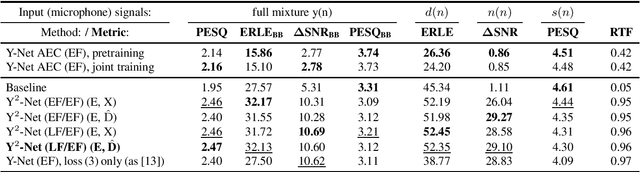
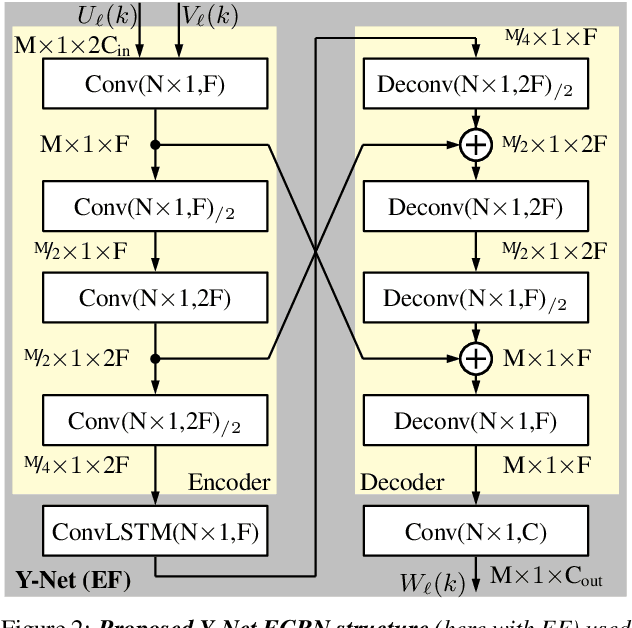
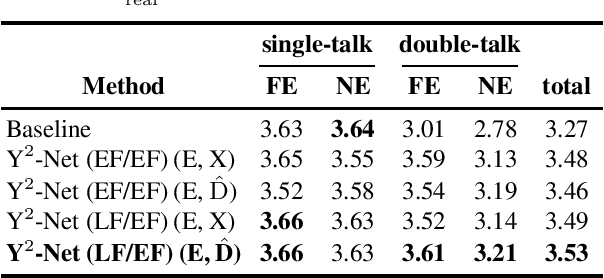
In recent years, deep neural networks (DNNs) were studied as an alternative to traditional acoustic echo cancellation (AEC) algorithms. The proposed models achieved remarkable performance for the separate tasks of AEC and residual echo suppression (RES). A promising network topology is a fully convolutional recurrent network (FCRN) structure, which has already proven its performance on both noise suppression and AEC tasks, individually. However, the combination of AEC, postfiltering, and noise suppression to a single network typically leads to a noticeable decline in the quality of the near-end speech component due to the lack of a separate loss for echo estimation. In this paper, we propose a two-stage model (Y$^2$-Net) which consists of two FCRNs, each with two inputs and one output (Y-Net). The first stage (AEC) yields an echo estimate, which - as a novelty for a DNN AEC model - is further used by the second stage to perform RES and noise suppression. While the subjective listening test of the Interspeech 2021 AEC Challenge mostly yielded results close to the baseline, the proposed method scored an average improvement of 0.46 points over the baseline on the blind testset in double-talk on the instrumental metric DECMOS, provided by the challenge organizers.
Deep Noise Suppression With Non-Intrusive PESQNet Supervision Enabling the Use of Real Training Data
Mar 31, 2021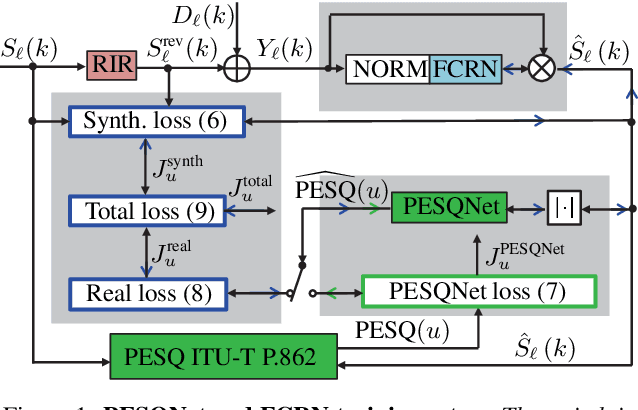
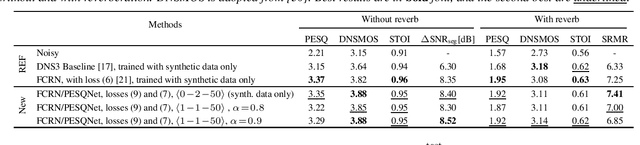


Data-driven speech enhancement employing deep neural networks (DNNs) can provide state-of-the-art performance even in the presence of non-stationary noise. During the training process, most of the speech enhancement neural networks are trained in a fully supervised way with losses requiring noisy speech to be synthesized by clean speech and additive noise. However, in a real implementation, only the noisy speech mixture is available, which leads to the question, how such data could be advantageously employed in training. In this work, we propose an end-to-end non-intrusive PESQNet DNN which estimates perceptual evaluation of speech quality (PESQ) scores, allowing a reference-free loss for real data. As a further novelty, we combine the PESQNet loss with denoising and dereverberation loss terms, and train a complex mask-based fully convolutional recurrent neural network (FCRN) in a "weakly" supervised way, each training cycle employing some synthetic data, some real data, and again synthetic data to keep the PESQNet up-to-date. In a subjective listening test, our proposed framework outperforms the Interspeech 2021 Deep Noise Suppression (DNS) Challenge baseline overall by 0.09 MOS points and in particular by 0.45 background noise MOS points.
AEC in a NetShell: On Target and Topology Choices for FCRN Acoustic Echo Cancellation
Mar 16, 2021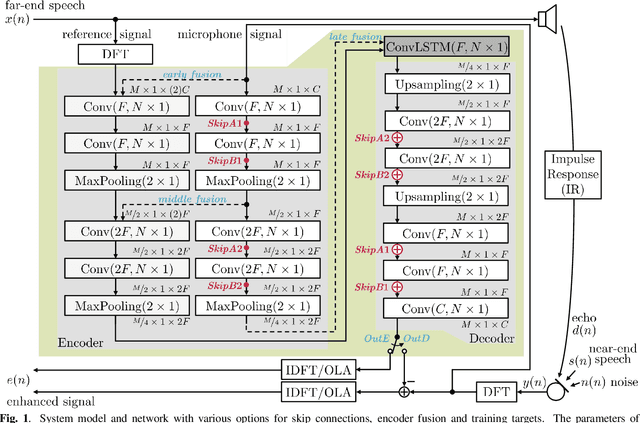
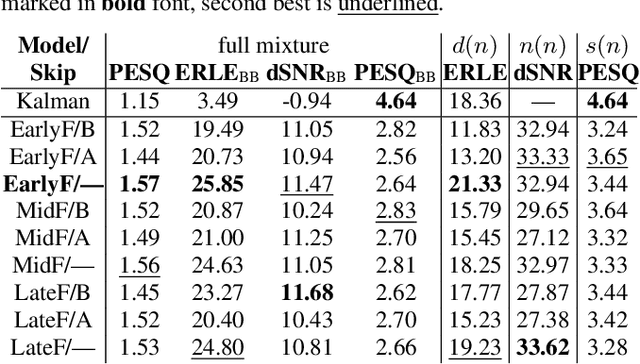
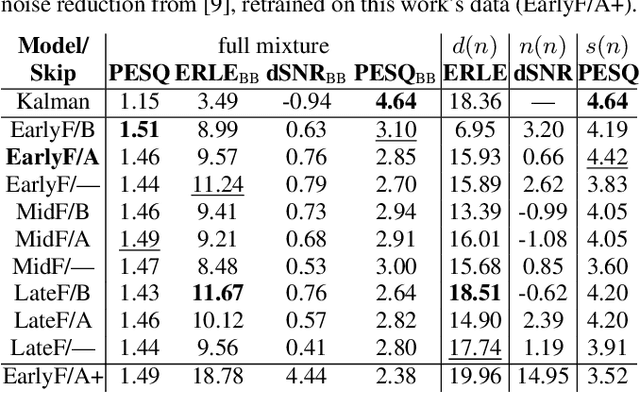
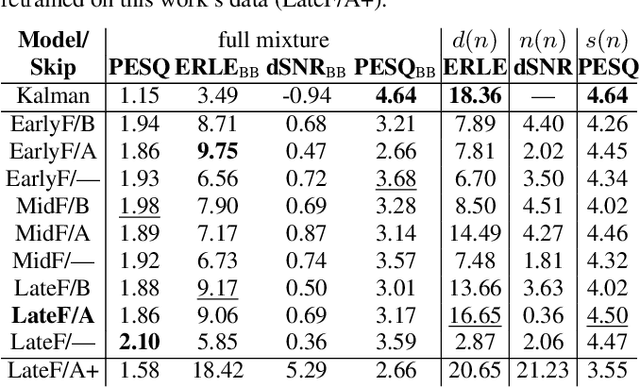
Acoustic echo cancellation (AEC) algorithms have a long-term steady role in signal processing, with approaches improving the performance of applications such as automotive hands-free systems, smart home and loudspeaker devices, or web conference systems. Just recently, very first deep neural network (DNN)-based approaches were proposed with a DNN for joint AEC and residual echo suppression (RES)/noise reduction, showing significant improvements in terms of echo suppression performance. Noise reduction algorithms, on the other hand, have enjoyed already a lot of attention with regard to DNN approaches, with the fully convolutional recurrent network (FCRN) architecture being among state of the art topologies. The recently published impressive echo cancellation performance of joint AEC/RES DNNs, however, so far came along with an undeniable impairment of speech quality. In this work we will heal this issue and significantly improve the near-end speech component quality over existing approaches. Also, we propose for the first time-to the best of our knowledge-a pure DNN AEC in the form of an echo estimator, that is based on a competitive FCRN structure and delivers a quality useful for practical applications.