 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Think: Bootstrapping LLM Reasoning Capability Through Graph Representation Learning
May 17, 2025Large Language Models (LLMs) have achieved remarkable success across various domains. However, they still face significant challenges, including high computational costs for training and limitations in solving complex reasoning problems. Although existing methods have extended the reasoning capabilities of LLMs through structured paradigms, these approaches often rely on task-specific prompts and predefined reasoning processes, which constrain their flexibility and generalizability. To address these limitations, we propose a novel framework that leverages graph learning to enable more flexible and adaptive reasoning capabilities for LLMs. Specifically, this approach models the reasoning process of a problem as a graph and employs LLM-based graph learning to guide the adaptive generation of each reasoning step. To further enhance the adaptability of the model, we introduce a Graph Neural Network (GNN) module to perform representation learning on the generated reasoning process, enabling real-time adjustments to both the model and the prompt. Experimental results demonstrate that this method significantly improves reasoning performance across multiple tasks without requiring additional training or task-specific prompt design. Code can be found in https://github.com/zch65458525/L2T.
Retrieval-Augmented Generation with Knowledge Graphs for Customer Service Question Answering
Apr 26, 2024In customer service technical support, swiftly and accurately retrieving relevant past issues is critical for efficiently resolving customer inquiries. The conventional retrieval methods in retrieval-augmented generation (RAG) for large language models (LLMs) treat a large corpus of past issue tracking tickets as plain text, ignoring the crucial intra-issue structure and inter-issue relations, which limits performance. We introduce a novel customer service question-answering method that amalgamates RAG with a knowledge graph (KG). Our method constructs a KG from historical issues for use in retrieval, retaining the intra-issue structure and inter-issue relations. During the question-answering phase, our method parses consumer queries and retrieves related sub-graphs from the KG to generate answers. This integration of a KG not only improves retrieval accuracy by preserving customer service structure information but also enhances answering quality by mitigating the effects of text segmentation. Empirical assessments on our benchmark datasets, utilizing key retrieval (MRR, Recall@K, NDCG@K) and text generation (BLEU, ROUGE, METEOR) metrics, reveal that our method outperforms the baseline by 77.6% in MRR and by 0.32 in BLEU. Our method has been deployed within LinkedIn's customer service team for approximately six months and has reduced the median per-issue resolution time by 28.6%.
AlerTiger: Deep Learning for AI Model Health Monitoring at LinkedIn
Jun 03, 2023



Data-driven companies use AI models extensively to develop products and intelligent business solutions, making the health of these models crucial for business success. Model monitoring and alerting in industries pose unique challenges, including a lack of clear model health metrics definition, label sparsity, and fast model iterations that result in short-lived models and features. As a product, there are also requirements for scalability, generalizability, and explainability. To tackle these challenges, we propose AlerTiger, a deep-learning-based MLOps model monitoring system that helps AI teams across the company monitor their AI models' health by detecting anomalies in models' input features and output score over time. The system consists of four major steps: model statistics generation, deep-learning-based anomaly detection, anomaly post-processing, and user alerting. Our solution generates three categories of statistics to indicate AI model health, offers a two-stage deep anomaly detection solution to address label sparsity and attain the generalizability of monitoring new models, and provides holistic reports for actionable alerts. This approach has been deployed to most of LinkedIn's production AI models for over a year and has identified several model issues that later led to significant business metric gains after fixing.
Are Interpretations Fairly Evaluated? A Definition Driven Pipeline for Post-Hoc Interpretability
Sep 16, 2020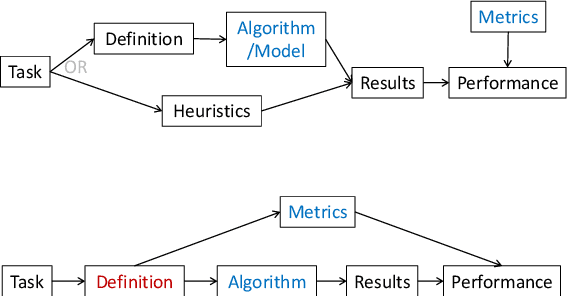

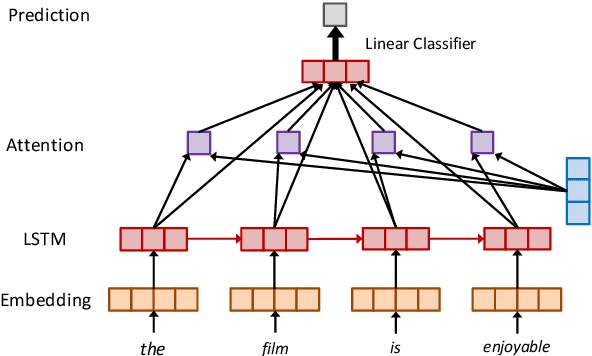
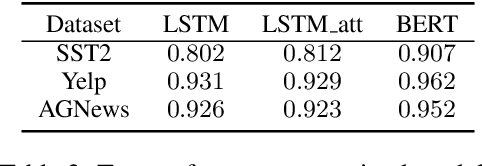
Recent years have witnessed an increasing number of interpretation methods being developed for improving transparency of NLP models. Meanwhile, researchers also try to answer the question that whether the obtained interpretation is faithful in explaining mechanisms behind model prediction? Specifically, (Jain and Wallace, 2019) proposes that "attention is not explanation" by comparing attention interpretation with gradient alternatives. However, it raises a new question that can we safely pick one interpretation method as the ground-truth? If not, on what basis can we compare different interpretation methods? In this work, we propose that it is crucial to have a concrete definition of interpretation before we could evaluate faithfulness of an interpretation. The definition will affect both the algorithm to obtain interpretation and, more importantly, the metric used in evaluation. Through both theoretical and experimental analysis, we find that although interpretation methods perform differently under a certain evaluation metric, such a difference may not result from interpretation quality or faithfulness, but rather the inherent bias of the evaluation metric.