 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianjia Shao
BASAR:Black-box Attack on Skeletal Action Recognition
Mar 19, 2021
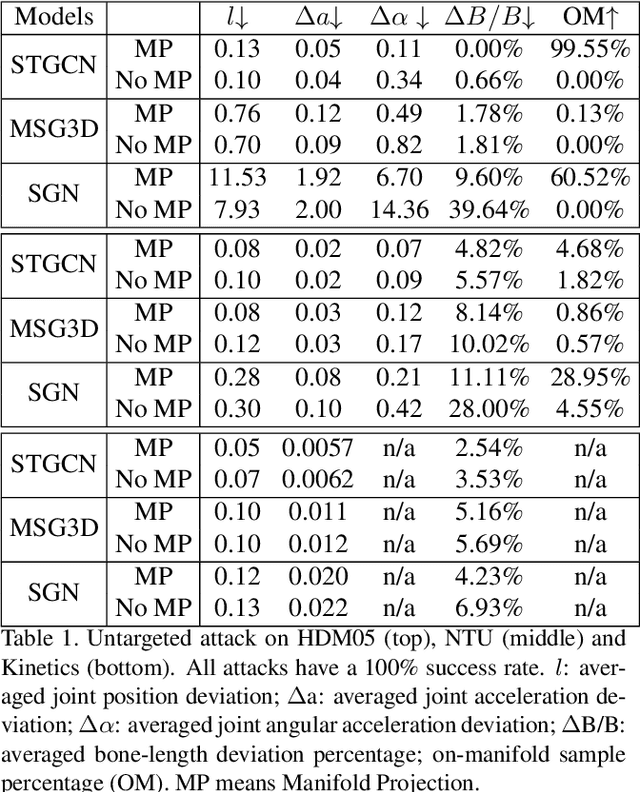
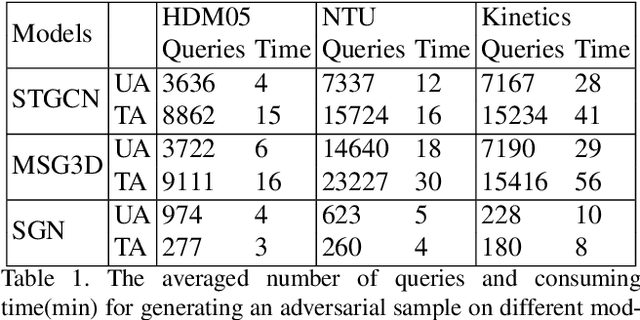
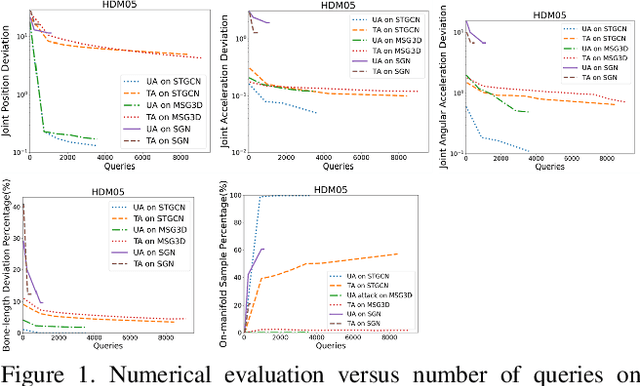
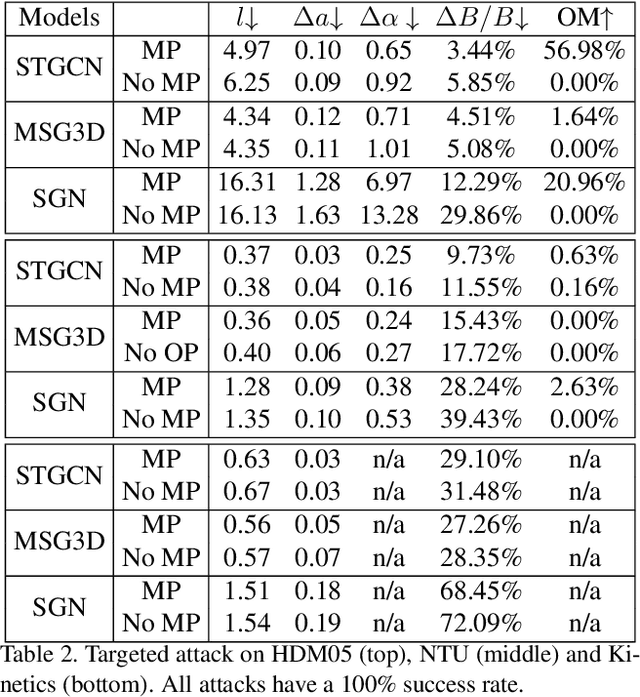
Skeletal motion plays a vital role in human activity recognition as either an independent data source or a complement. The robustness of skeleton-based activity recognizers has been questioned recently, which shows that they are vulnerable to adversarial attacks when the full-knowledge of the recognizer is accessible to the attacker. However, this white-box requirement is overly restrictive in most scenarios and the attack is not truly threatening. In this paper, we show that such threats do exist under black-box settings too. To this end, we propose the first black-box adversarial attack method BASAR. Through BASAR, we show that adversarial attack is not only truly a threat but also can be extremely deceitful, because on-manifold adversarial samples are rather common in skeletal motions, in contrast to the common belief that adversarial samples only exist off-manifold. Through exhaustive evaluation and comparison, we show that BASAR can deliver successful attacks across models, data, and attack modes. Through harsh perceptual studies, we show that it achieves effective yet imperceptible attacks. By analyzing the attack on different activity recognizers, BASAR helps identify the potential causes of their vulnerability and provides insights on what classifiers are likely to be more robust against attack.
Understanding the Robustness of Skeleton-based Action Recognition under Adversarial Attack
Mar 18, 2021
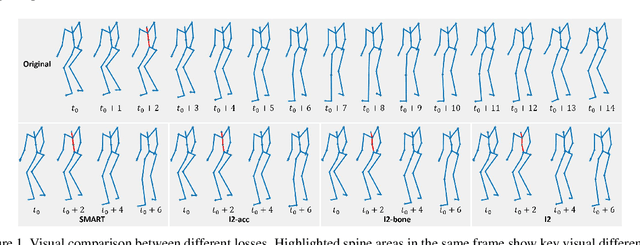
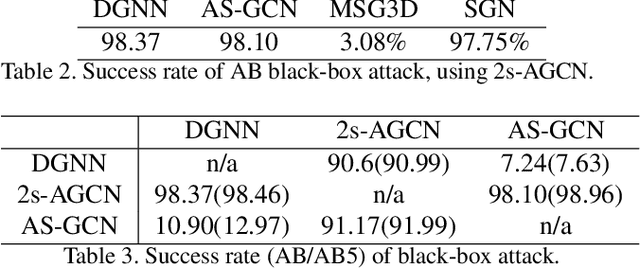

Action recognition has been heavily employed in many applications such as autonomous vehicles, surveillance, etc, where its robustness is a primary concern. In this paper, we examine the robustness of state-of-the-art action recognizers against adversarial attack, which has been rarely investigated so far. To this end, we propose a new method to attack action recognizers that rely on 3D skeletal motion. Our method involves an innovative perceptual loss that ensures the imperceptibility of the attack. Empirical studies demonstrate that our method is effective in both white-box and black-box scenarios. Its generalizability is evidenced on a variety of action recognizers and datasets. Its versatility is shown in different attacking strategies. Its deceitfulness is proven in extensive perceptual studies. Our method shows that adversarial attack on 3D skeletal motions, one type of time-series data, is significantly different from traditional adversarial attack problems. Its success raises serious concern on the robustness of action recognizers and provides insights on potential improvements.
In-game Residential Home Planning via Visual Context-aware Global Relation Learning
Feb 23, 2021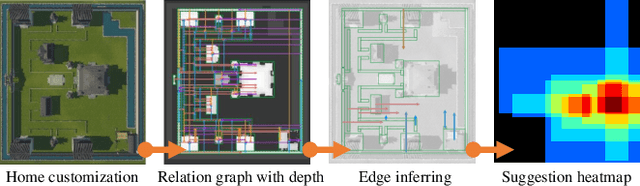
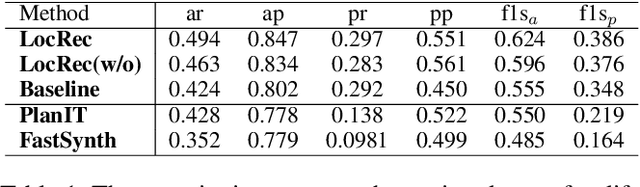
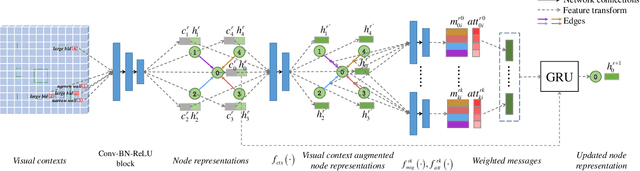
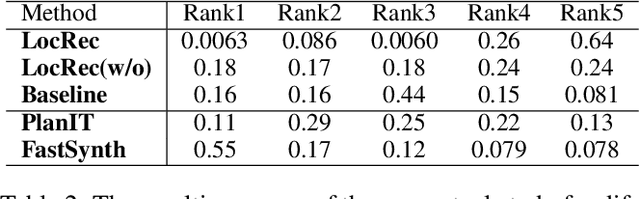
In this paper, we propose an effective global relation learning algorithm to recommend an appropriate location of a building unit for in-game customization of residential home complex. Given a construction layout, we propose a visual context-aware graph generation network that learns the implicit global relations among the scene components and infers the location of a new building unit. The proposed network takes as input the scene graph and the corresponding top-view depth image. It provides the location recommendations for a newly-added building units by learning an auto-regressive edge distribution conditioned on existing scenes. We also introduce a global graph-image matching loss to enhance the awareness of essential geometry semantics of the site. Qualitative and quantitative experiments demonstrate that the recommended location well reflects the implicit spatial rules of components in the residential estates, and it is instructive and practical to locate the building units in the 3D scene of the complex construction.
One-shot Face Reenactment Using Appearance Adaptive Normalization
Feb 20, 2021
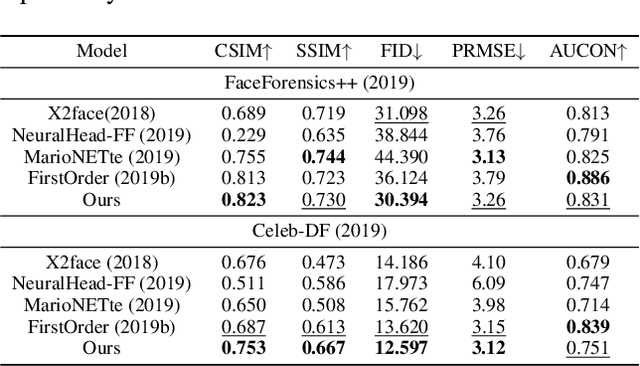
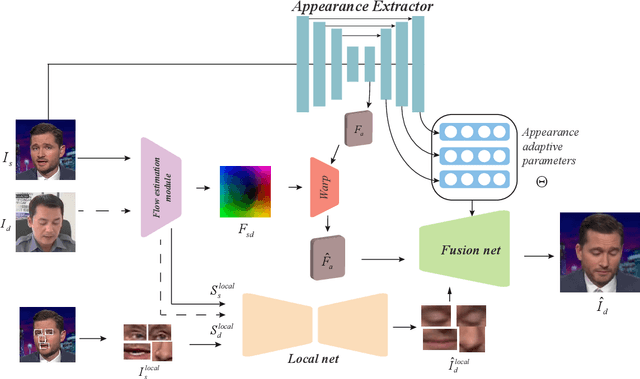
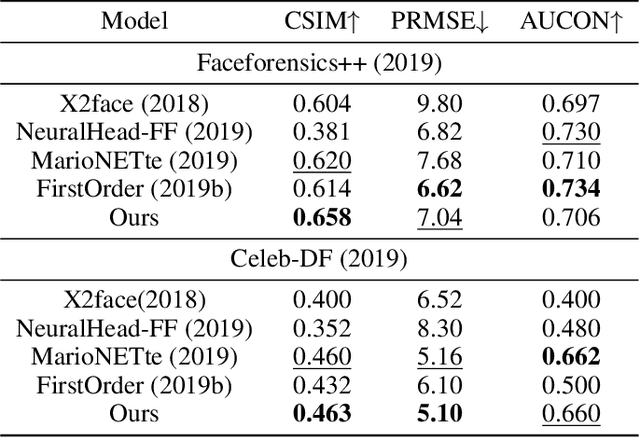
The paper proposes a novel generative adversarial network for one-shot face reenactment, which can animate a single face image to a different pose-and-expression (provided by a driving image) while keeping its original appearance. The core of our network is a novel mechanism called appearance adaptive normalization, which can effectively integrate the appearance information from the input image into our face generator by modulating the feature maps of the generator using the learned adaptive parameters. Furthermore, we specially design a local net to reenact the local facial components (i.e., eyes, nose and mouth) first, which is a much easier task for the network to learn and can in turn provide explicit anchors to guide our face generator to learn the global appearance and pose-and-expression. Extensive quantitative and qualitative experiments demonstrate the significant efficacy of our model compared with prior one-shot methods.
High-order Differentiable Autoencoder for Nonlinear Model Reduction
Feb 19, 2021
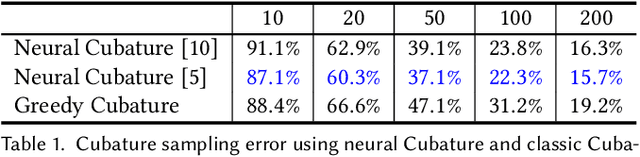

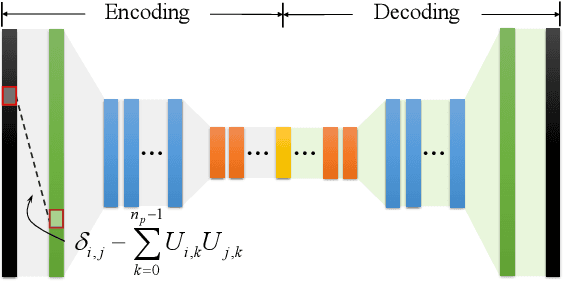
This paper provides a new avenue for exploiting deep neural networks to improve physics-based simulation. Specifically, we integrate the classic Lagrangian mechanics with a deep autoencoder to accelerate elastic simulation of deformable solids. Due to the inertia effect, the dynamic equilibrium cannot be established without evaluating the second-order derivatives of the deep autoencoder network. This is beyond the capability of off-the-shelf automatic differentiation packages and algorithms, which mainly focus on the gradient evaluation. Solving the nonlinear force equilibrium is even more challenging if the standard Newton's method is to be used. This is because we need to compute a third-order derivative of the network to obtain the variational Hessian. We attack those difficulties by exploiting complex-step finite difference, coupled with reverse automatic differentiation. This strategy allows us to enjoy the convenience and accuracy of complex-step finite difference and in the meantime, to deploy complex-value perturbations as collectively as possible to save excessive network passes. With a GPU-based implementation, we are able to wield deep autoencoders (e.g., $10+$ layers) with a relatively high-dimension latent space in real-time. Along this pipeline, we also design a sampling network and a weighting network to enable \emph{weight-varying} Cubature integration in order to incorporate nonlinearity in the model reduction. We believe this work will inspire and benefit future research efforts in nonlinearly reduced physical simulation problems.
Structure-aware Person Image Generation with Pose Decomposition and Semantic Correlation
Feb 05, 2021

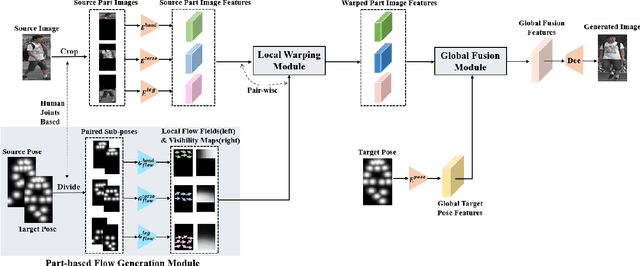
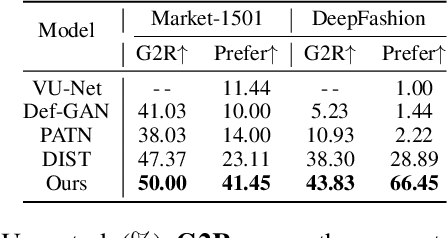
In this paper we tackle the problem of pose guided person image generation, which aims to transfer a person image from the source pose to a novel target pose while maintaining the source appearance. Given the inefficiency of standard CNNs in handling large spatial transformation, we propose a structure-aware flow based method for high-quality person image generation. Specifically, instead of learning the complex overall pose changes of human body, we decompose the human body into different semantic parts (e.g., head, torso, and legs) and apply different networks to predict the flow fields for these parts separately. Moreover, we carefully design the network modules to effectively capture the local and global semantic correlations of features within and among the human parts respectively. Extensive experimental results show that our method can generate high-quality results under large pose discrepancy and outperforms state-of-the-art methods in both qualitative and quantitative comparisons.