 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Deep Alignment Through The Lens Of Incomplete Learning
Nov 15, 2025Large language models exhibit systematic vulnerabilities to adversarial attacks despite extensive safety alignment. We provide a mechanistic analysis revealing that position-dependent gradient weakening during autoregressive training creates signal decay, leading to incomplete safety learning where safety training fails to transform model preferences in later response regions fully. We introduce base-favored tokens -- vocabulary elements where base models assign higher probability than aligned models -- as computational indicators of incomplete safety learning and develop a targeted completion method that addresses undertrained regions through adaptive penalties and hybrid teacher distillation. Experimental evaluation across Llama and Qwen model families demonstrates dramatic improvements in adversarial robustness, with 48--98% reductions in attack success rates while preserving general capabilities. These results establish both a mechanistic understanding and practical solutions for fundamental limitations in safety alignment methodologies.
Symmetry-preserving graph attention network to solve routing problems at multiple resolutions
Oct 24, 2023



Travelling Salesperson Problems (TSPs) and Vehicle Routing Problems (VRPs) have achieved reasonable improvement in accuracy and computation time with the adaptation of Machine Learning (ML) methods. However, none of the previous works completely respects the symmetries arising from TSPs and VRPs including rotation, translation, permutation, and scaling. In this work, we introduce the first-ever completely equivariant model and training to solve combinatorial problems. Furthermore, it is essential to capture the multiscale structure (i.e. from local to global information) of the input graph, especially for the cases of large and long-range graphs, while previous methods are limited to extracting only local information that can lead to a local or sub-optimal solution. To tackle the above limitation, we propose a Multiresolution scheme in combination with Equivariant Graph Attention network (mEGAT) architecture, which can learn the optimal route based on low-level and high-level graph resolutions in an efficient way. In particular, our approach constructs a hierarchy of coarse-graining graphs from the input graph, in which we try to solve the routing problems on simple low-level graphs first, then utilize that knowledge for the more complex high-level graphs. Experimentally, we have shown that our model outperforms existing baselines and proved that symmetry preservation and multiresolution are important recipes for solving combinatorial problems in a data-driven manner. Our source code is publicly available at https://github.com/HySonLab/Multires-NP-hard
Leveraging Video Coding Knowledge for Deep Video Enhancement
Feb 27, 2023



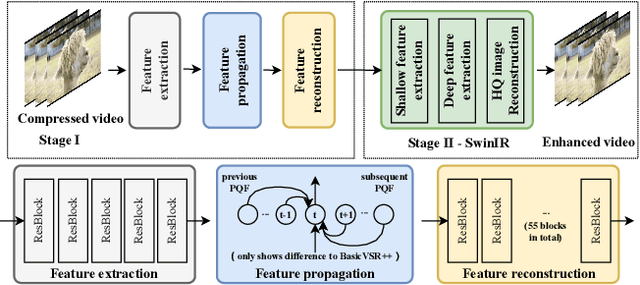
Recent advancements in deep learning techniques have significantly improved the quality of compressed videos. However, previous approaches have not fully exploited the motion characteristics of compressed videos, such as the drastic change in motion between video contents and the hierarchical coding structure of the compressed video. This study proposes a novel framework that leverages the low-delay configuration of video compression to enhance the existing state-of-the-art method, BasicVSR++. We incorporate a context-adaptive video fusion method to enhance the final quality of compressed videos. The proposed approach has been evaluated in the NTIRE22 challenge, a benchmark for video restoration and enhancement, and achieved improvements in both quantitative metrics and visual quality compared to the previous method.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022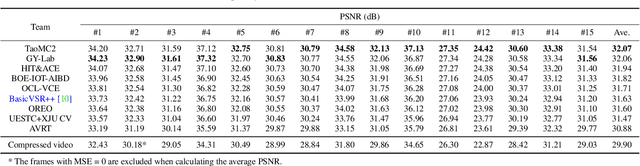
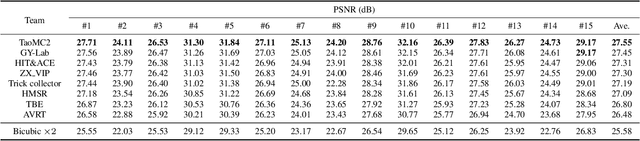

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.