 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Segmentation for Histopathology using Learned Regularization based on Global Proportions
Apr 27, 2026In pathology, the spatial distribution and proportions of tissue types are key indicators of disease progression, and are more readily available than fine-grained annotations. However, these assessments are rarely mapped to pixel-wise segmentation. The task is fundamentally underdetermined, as many spatially distinct segmentations can satisfy the same global proportions in the absence of pixel-wise constraints. To address this, we introduce Variational Segmentation from Label Proportions (VSLP), a two-stage framework that infers dense segmentations from global label proportions, without any pixel-level annotations. This framework first leverages a pre-trained transformer model with test-time augmentation to produce a pixel-wise confidence estimate. In the second stage, these estimates are fused by solving a variational optimization problem that incorporates a Wasserstein data fidelity term alongside a learned regularizer. Unlike end-to-end networks, our variational method can visualize the fidelity-regularization energy, resulting in more interpretable segmentation. We validate our approach on two public datasets, achieving superior performance over existing weakly supervised and unsupervised methods. For one of these datasets, proportions have been estimated by an experienced pathologist to provide a realistic benchmark to the community. Furthermore, the method scales to an in-house dataset with noisy pathologist labels, severely outperforming state-of-the-art methods, thereby demonstrating practical applicability. The code and data will be made publicly available upon acceptance at https://github.com/xiaoliangpi/VSLP.
Closing the Domain Gap in Biomedical Imaging by In-Context Control Samples
Apr 22, 2026The central problem in biomedical imaging are batch effects: systematic technical variations unrelated to the biological signal of interest. These batch effects critically undermine experimental reproducibility and are the primary cause of failure of deep learning systems on new experimental batches, preventing their practical use in the real world. Despite years of research, no method has succeeded in closing this performance gap for deep learning models. We propose Control-Stabilized Adaptive Risk Minimization via Batch Normalization (CS-ARM-BN), a meta-learning adaptation method that exploits negative control samples. Such unperturbed reference images are present in every experimental batch by design and serve as stable context for adaptation. We validate our novel method on Mechanism-of-Action (MoA) classification, a crucial task for drug discovery, on the large-scale JUMP-CP dataset. The accuracy of standard ResNets drops from 0.939 $\pm$ 0.005, on the training domain, to 0.862 $\pm$ 0.060 on data from new experimental batches. Foundation models, even after Typical Variation Normalization, fail to close this gap. We are the first to show that meta-learning approaches close the domain gap by achieving 0.935 $\pm$ 0.018. If the new experimental batches exhibit strong domain shifts, such as being generated in a different lab, meta-learning approaches can be stabilized with control samples, which are always available in biomedical experiments. Our work shows that batch effects in bioimaging data can be effectively neutralized through principled in-context adaptation, which also makes them practically usable and efficient.
Exploiting Intermediate Reconstructions in Optical Coherence Tomography for Test-Time Adaption of Medical Image Segmentation
Mar 05, 2026Primary health care frequently relies on low-cost imaging devices, which are commonly used for screening purposes. To ensure accurate diagnosis, these systems depend on advanced reconstruction algorithms designed to approximate the performance of high-quality counterparts. Such algorithms typically employ iterative reconstruction methods that incorporate domain-specific prior knowledge. However, downstream task performance is generally assessed using only the final reconstructed image, thereby disregarding the informative intermediate representations generated throughout the reconstruction process. In this work, we propose IRTTA to exploit these intermediate representations at test-time by adapting the normalization-layer parameters of a frozen downstream network via a modulator network that conditions on the current reconstruction timescale. The modulator network is learned during test-time using an averaged entropy loss across all individual timesteps. Variation among the timestep-wise segmentations additionally provides uncertainty estimates at no extra cost. This approach enhances segmentation performance and enables semantically meaningful uncertainty estimation, all without modifying either the reconstruction process or the downstream model.
Learned Finite Element-based Regularization of the Inverse Problem in Electrocardiographic Imaging
Feb 07, 2026Electrocardiographic imaging (ECGI) seeks to reconstruct cardiac electrical activity from body-surface potentials noninvasively. However, the associated inverse problem is severely ill-posed and requires robust regularization. While classical approaches primarily employ spatial smoothing, the temporal structure of cardiac dynamics remains underexploited despite its physiological relevance. We introduce a space-time regularization framework that couples spatial regularization with a learned temporal Fields-of-Experts (FoE) prior to capture complex spatiotemporal activation patterns. We derive a finite element discretization on unstructured cardiac surface meshes, prove Mosco-convergence, and develop a scalable optimization algorithm capable of handling the FoE term. Numerical experiments on synthetic epicardial data demonstrate improved denoising and inverse reconstructions compared to handcrafted spatiotemporal methods, yielding solutions that are both robust to noise and physiologically plausible.
Stochastic Siamese MAE Pretraining for Longitudinal Medical Images
Dec 29, 2025Temporally aware image representations are crucial for capturing disease progression in 3D volumes of longitudinal medical datasets. However, recent state-of-the-art self-supervised learning approaches like Masked Autoencoding (MAE), despite their strong representation learning capabilities, lack temporal awareness. In this paper, we propose STAMP (Stochastic Temporal Autoencoder with Masked Pretraining), a Siamese MAE framework that encodes temporal information through a stochastic process by conditioning on the time difference between the 2 input volumes. Unlike deterministic Siamese approaches, which compare scans from different time points but fail to account for the inherent uncertainty in disease evolution, STAMP learns temporal dynamics stochastically by reframing the MAE reconstruction loss as a conditional variational inference objective. We evaluated STAMP on two OCT and one MRI datasets with multiple visits per patient. STAMP pretrained ViT models outperformed both existing temporal MAE methods and foundation models on different late stage Age-Related Macular Degeneration and Alzheimer's Disease progression prediction which require models to learn the underlying non-deterministic temporal dynamics of the diseases.
Efficient MedSAMs: Segment Anything in Medical Images on Laptop
Dec 20, 2024


Promptable segmentation foundation models have emerged as a transformative approach to addressing the diverse needs in medical images, but most existing models require expensive computing, posing a big barrier to their adoption in clinical practice. In this work, we organized the first international competition dedicated to promptable medical image segmentation, featuring a large-scale dataset spanning nine common imaging modalities from over 20 different institutions. The top teams developed lightweight segmentation foundation models and implemented an efficient inference pipeline that substantially reduced computational requirements while maintaining state-of-the-art segmentation accuracy. Moreover, the post-challenge phase advanced the algorithms through the design of performance booster and reproducibility tasks, resulting in improved algorithms and validated reproducibility of the winning solution. Furthermore, the best-performing algorithms have been incorporated into the open-source software with a user-friendly interface to facilitate clinical adoption. The data and code are publicly available to foster the further development of medical image segmentation foundation models and pave the way for impactful real-world applications.
Finite element-based space-time total variation-type regularization of the inverse problem in electrocardiographic imaging
Aug 21, 2024



Reconstructing cardiac electrical activity from body surface electric potential measurements results in the severely ill-posed inverse problem in electrocardiography. Many different regularization approaches have been proposed to improve numerical results and provide unique results. This work presents a novel approach for reconstructing the epicardial potential from body surface potential maps based on a space-time total variation-type regularization using finite elements, where a first-order primal-dual algorithm solves the underlying convex optimization problem. In several numerical experiments, the superior performance of this method and the benefit of space-time regularization for the reconstruction of epicardial potential on two-dimensional torso data and a three-dimensional rabbit heart compared to state-of-the-art methods are demonstrated.
Gadolinium dose reduction for brain MRI using conditional deep learning
Mar 06, 2024



Recently, deep learning (DL)-based methods have been proposed for the computational reduction of gadolinium-based contrast agents (GBCAs) to mitigate adverse side effects while preserving diagnostic value. Currently, the two main challenges for these approaches are the accurate prediction of contrast enhancement and the synthesis of realistic images. In this work, we address both challenges by utilizing the contrast signal encoded in the subtraction images of pre-contrast and post-contrast image pairs. To avoid the synthesis of any noise or artifacts and solely focus on contrast signal extraction and enhancement from low-dose subtraction images, we train our DL model using noise-free standard-dose subtraction images as targets. As a result, our model predicts the contrast enhancement signal only; thereby enabling synthesization of images beyond the standard dose. Furthermore, we adapt the embedding idea of recent diffusion-based models to condition our model on physical parameters affecting the contrast enhancement behavior. We demonstrate the effectiveness of our approach on synthetic and real datasets using various scanners, field strengths, and contrast agents.
Faithful Synthesis of Low-dose Contrast-enhanced Brain MRI Scans using Noise-preserving Conditional GANs
Jun 26, 2023



Today Gadolinium-based contrast agents (GBCA) are indispensable in Magnetic Resonance Imaging (MRI) for diagnosing various diseases. However, GBCAs are expensive and may accumulate in patients with potential side effects, thus dose-reduction is recommended. Still, it is unclear to which extent the GBCA dose can be reduced while preserving the diagnostic value -- especially in pathological regions. To address this issue, we collected brain MRI scans at numerous non-standard GBCA dosages and developed a conditional GAN model for synthesizing corresponding images at fractional dose levels. Along with the adversarial loss, we advocate a novel content loss function based on the Wasserstein distance of locally paired patch statistics for the faithful preservation of noise. Our numerical experiments show that conditional GANs are suitable for generating images at different GBCA dose levels and can be used to augment datasets for virtual contrast models. Moreover, our model can be transferred to openly available datasets such as BraTS, where non-standard GBCA dosage images do not exist.
Shared Prior Learning of Energy-Based Models for Image Reconstruction
Nov 13, 2020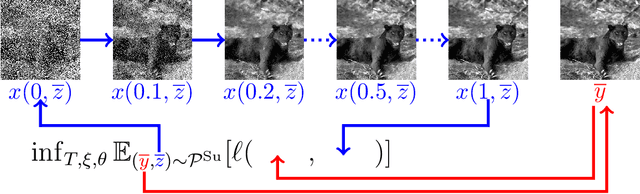
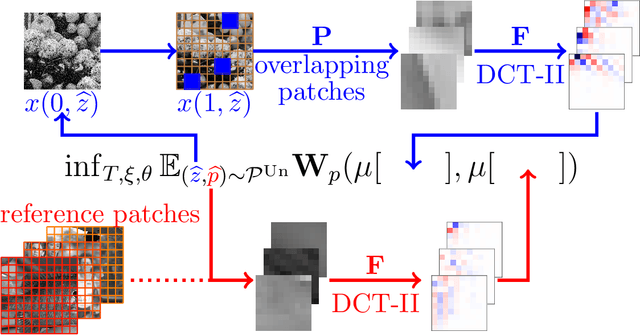
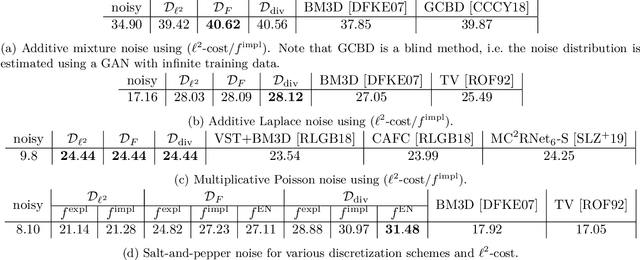
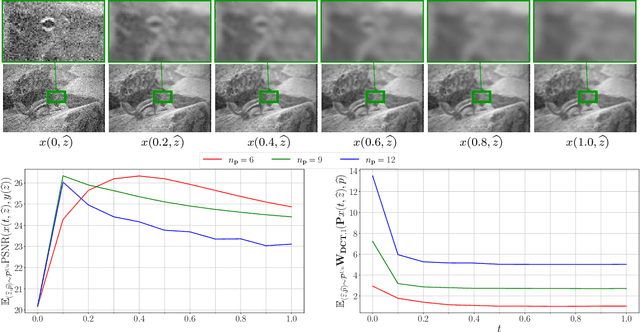
We propose a novel learning-based framework for image reconstruction particularly designed for training without ground truth data, which has three major building blocks: energy-based learning, a patch-based Wasserstein loss functional, and shared prior learning. In energy-based learning, the parameters of an energy functional composed of a learned data fidelity term and a data-driven regularizer are computed in a mean-field optimal control problem. In the absence of ground truth data, we change the loss functional to a patch-based Wasserstein functional, in which local statistics of the output images are compared to uncorrupted reference patches. Finally, in shared prior learning, both aforementioned optimal control problems are optimized simultaneously with shared learned parameters of the regularizer to further enhance unsupervised image reconstruction. We derive several time discretization schemes of the gradient flow and verify their consistency in terms of Mosco convergence. In numerous numerical experiments, we demonstrate that the proposed method generates state-of-the-art results for various image reconstruction applications--even if no ground truth images are available for training.