 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHadaCore: Tensor Core Accelerated Hadamard Transform Kernel
Dec 12, 2024We present HadaCore, a modified Fast Walsh-Hadamard Transform (FWHT) algorithm optimized for the Tensor Cores present in modern GPU hardware. HadaCore follows the recursive structure of the original FWHT algorithm, achieving the same asymptotic runtime complexity but leveraging a hardware-aware work decomposition that benefits from Tensor Core acceleration. This reduces bottlenecks from compute and data exchange. On Nvidia A100 and H100 GPUs, HadaCore achieves speedups of 1.1-1.4x and 1.0-1.3x, with a peak gain of 3.5x and 3.6x respectively, when compared to the existing state-of-the-art implementation of the original algorithm. We also show that when using FP16 or BF16, our implementation is numerically accurate, enabling comparable accuracy on MMLU benchmarks when used in an end-to-end Llama3 inference run with quantized (FP8) attention.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024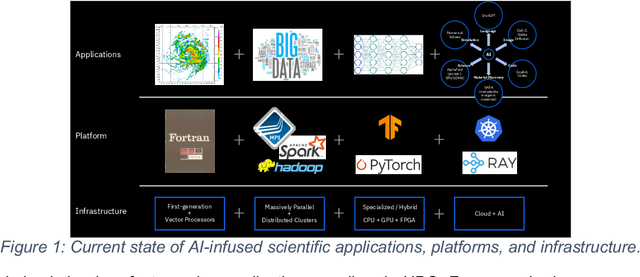
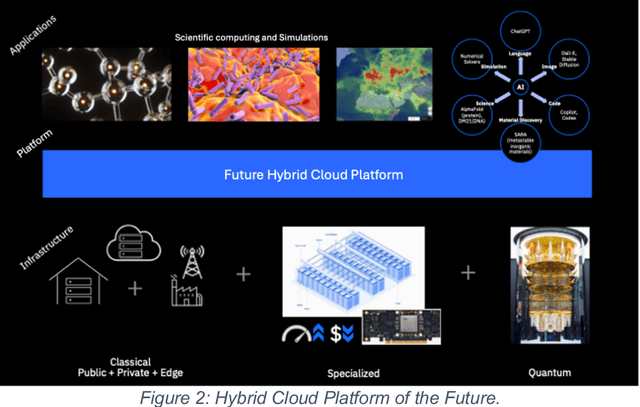
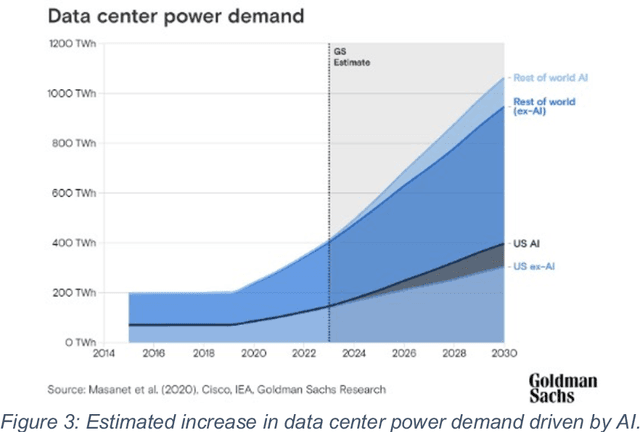
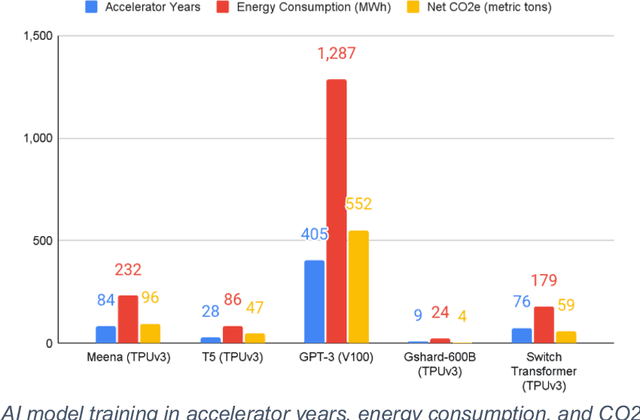
This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
Accelerating Production LLMs with Combined Token/Embedding Speculators
Apr 29, 2024This technical report describes the design and training of novel speculative decoding draft models, for accelerating the inference speeds of large language models in a production environment. By conditioning draft predictions on both context vectors and sampled tokens, we can train our speculators to efficiently predict high-quality n-grams, which the base model then accepts or rejects. This allows us to effectively predict multiple tokens per inference forward pass, accelerating wall-clock inference speeds of highly optimized base model implementations by a factor of 2-3x. We explore these initial results and describe next steps for further improvements.
SudokuSens: Enhancing Deep Learning Robustness for IoT Sensing Applications using a Generative Approach
Feb 08, 2024



This paper introduces SudokuSens, a generative framework for automated generation of training data in machine-learning-based Internet-of-Things (IoT) applications, such that the generated synthetic data mimic experimental configurations not encountered during actual sensor data collection. The framework improves the robustness of resulting deep learning models, and is intended for IoT applications where data collection is expensive. The work is motivated by the fact that IoT time-series data entangle the signatures of observed objects with the confounding intrinsic properties of the surrounding environment and the dynamic environmental disturbances experienced. To incorporate sufficient diversity into the IoT training data, one therefore needs to consider a combinatorial explosion of training cases that are multiplicative in the number of objects considered and the possible environmental conditions in which such objects may be encountered. Our framework substantially reduces these multiplicative training needs. To decouple object signatures from environmental conditions, we employ a Conditional Variational Autoencoder (CVAE) that allows us to reduce data collection needs from multiplicative to (nearly) linear, while synthetically generating (data for) the missing conditions. To obtain robustness with respect to dynamic disturbances, a session-aware temporal contrastive learning approach is taken. Integrating the aforementioned two approaches, SudokuSens significantly improves the robustness of deep learning for IoT applications. We explore the degree to which SudokuSens benefits downstream inference tasks in different data sets and discuss conditions under which the approach is particularly effective.
Foundation Models for Generalist Geospatial Artificial Intelligence
Nov 08, 2023Significant progress in the development of highly adaptable and reusable Artificial Intelligence (AI) models is expected to have a significant impact on Earth science and remote sensing. Foundation models are pre-trained on large unlabeled datasets through self-supervision, and then fine-tuned for various downstream tasks with small labeled datasets. This paper introduces a first-of-a-kind framework for the efficient pre-training and fine-tuning of foundational models on extensive geospatial data. We have utilized this framework to create Prithvi, a transformer-based geospatial foundational model pre-trained on more than 1TB of multispectral satellite imagery from the Harmonized Landsat-Sentinel 2 (HLS) dataset. Our study demonstrates the efficacy of our framework in successfully fine-tuning Prithvi to a range of Earth observation tasks that have not been tackled by previous work on foundation models involving multi-temporal cloud gap imputation, flood mapping, wildfire scar segmentation, and multi-temporal crop segmentation. Our experiments show that the pre-trained model accelerates the fine-tuning process compared to leveraging randomly initialized weights. In addition, pre-trained Prithvi compares well against the state-of-the-art, e.g., outperforming a conditional GAN model in multi-temporal cloud imputation by up to 5pp (or 5.7%) in the structural similarity index. Finally, due to the limited availability of labeled data in the field of Earth observation, we gradually reduce the quantity of available labeled data for refining the model to evaluate data efficiency and demonstrate that data can be decreased significantly without affecting the model's accuracy. The pre-trained 100 million parameter model and corresponding fine-tuning workflows have been released publicly as open source contributions to the global Earth sciences community through Hugging Face.
AI Foundation Models for Weather and Climate: Applications, Design, and Implementation
Sep 20, 2023

Machine learning and deep learning methods have been widely explored in understanding the chaotic behavior of the atmosphere and furthering weather forecasting. There has been increasing interest from technology companies, government institutions, and meteorological agencies in building digital twins of the Earth. Recent approaches using transformers, physics-informed machine learning, and graph neural networks have demonstrated state-of-the-art performance on relatively narrow spatiotemporal scales and specific tasks. With the recent success of generative artificial intelligence (AI) using pre-trained transformers for language modeling and vision with prompt engineering and fine-tuning, we are now moving towards generalizable AI. In particular, we are witnessing the rise of AI foundation models that can perform competitively on multiple domain-specific downstream tasks. Despite this progress, we are still in the nascent stages of a generalizable AI model for global Earth system models, regional climate models, and mesoscale weather models. Here, we review current state-of-the-art AI approaches, primarily from transformer and operator learning literature in the context of meteorology. We provide our perspective on criteria for success towards a family of foundation models for nowcasting and forecasting weather and climate predictions. We also discuss how such models can perform competitively on downstream tasks such as downscaling (super-resolution), identifying conditions conducive to the occurrence of wildfires, and predicting consequential meteorological phenomena across various spatiotemporal scales such as hurricanes and atmospheric rivers. In particular, we examine current AI methodologies and contend they have matured enough to design and implement a weather foundation model.