 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a General Framework for ML-based Self-tuning Databases
Nov 16, 2020
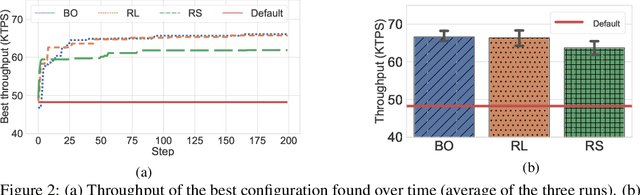
Machine learning (ML) methods have recently emerged as an effective way to perform automated parameter tuning of databases. State-of-the-art approaches include Bayesian optimization (BO) and reinforcement learning (RL). In this work, we describe our experience when applying these methods to a database not yet studied in this context: FoundationDB. Firstly, we describe the challenges we faced, such as unknown valid ranges of configuration parameters and combinations of parameter values that result in invalid runs, and how we mitigated them. While these issues are typically overlooked, we argue that they are a crucial barrier to the adoption of ML self-tuning techniques in databases, and thus deserve more attention from the research community. Secondly, we present experimental results obtained when tuning FoundationDB using ML methods. Unlike prior work in this domain, we also compare with the simplest of baselines: random search. Our results show that, while BO and RL methods can improve the throughput of FoundationDB by up to 38%, random search is a highly competitive baseline, finding a configuration that is only 4% worse than the, vastly more complex, ML methods. We conclude that future work in this area may want to focus more on randomized, model-free optimization algorithms.
MixBoost: A Heterogeneous Boosting Machine
Jun 17, 2020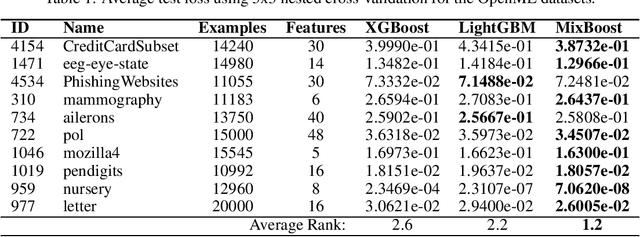
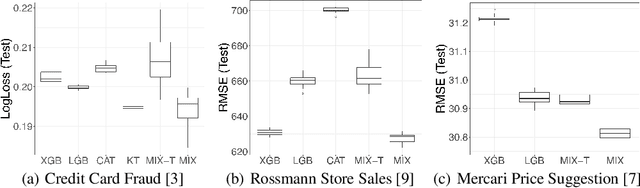
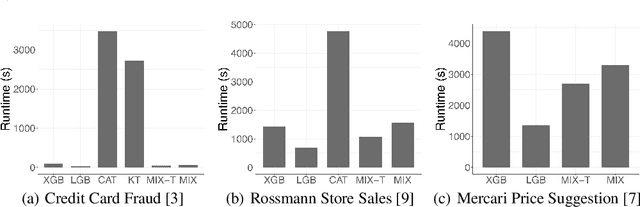

Modern gradient boosting software frameworks, such as XGBoost and LightGBM, implement Newton descent in a functional space. At each boosting iteration, their goal is to find the base hypothesis, selected from some base hypothesis class, that is closest to the Newton descent direction in a Euclidean sense. Typically, the base hypothesis class is fixed to be all binary decision trees up to a given depth. In this work, we study a Heterogeneous Newton Boosting Machine (HNBM) in which the base hypothesis class may vary across boosting iterations. Specifically, at each boosting iteration, the base hypothesis class is chosen, from a fixed set of subclasses, by sampling from a probability distribution. We derive a global linear convergence rate for the HNBM under certain assumptions, and show that it agrees with existing rates for Newton's method when the Newton direction can be perfectly fitted by the base hypothesis at each boosting iteration. We then describe a particular realization of a HNBM, MixBoost, that, at each boosting iteration, randomly selects between either a decision tree of variable depth or a linear regressor with random Fourier features. We describe how MixBoost is implemented, with a focus on the training complexity. Finally, we present experimental results, using OpenML and Kaggle datasets, that show that MixBoost is able to achieve better generalization loss than competing boosting frameworks, without taking significantly longer to tune.
Compiling Neural Networks for a Computational Memory Accelerator
Mar 05, 2020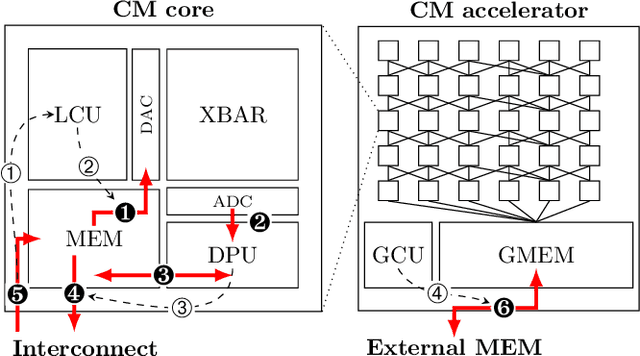

Computational memory (CM) is a promising approach for accelerating inference on neural networks (NN) by using enhanced memories that, in addition to storing data, allow computations on them. One of the main challenges of this approach is defining a hardware/software interface that allows a compiler to map NN models for efficient execution on the underlying CM accelerator. This is a non-trivial task because efficiency dictates that the CM accelerator is explicitly programmed as a dataflow engine where the execution of the different NN layers form a pipeline. In this paper, we present our work towards a software stack for executing ML models on such a multi-core CM accelerator. We describe an architecture for the hardware and software, and focus on the problem of implementing the appropriate control logic so that data dependencies are respected. We propose a solution to the latter that is based on polyhedral compilation.
SySCD: A System-Aware Parallel Coordinate Descent Algorithm
Nov 18, 2019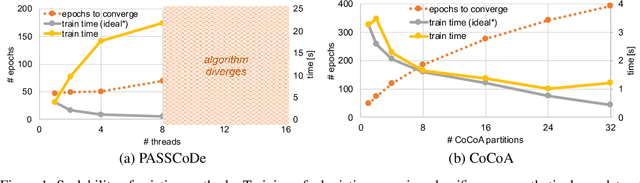
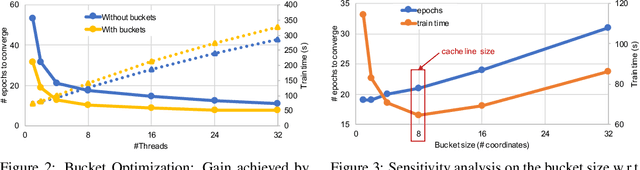

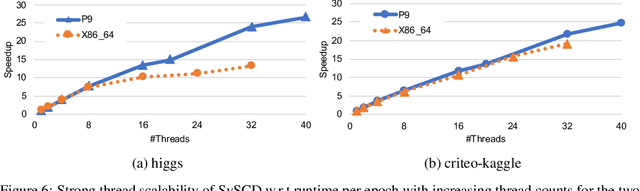
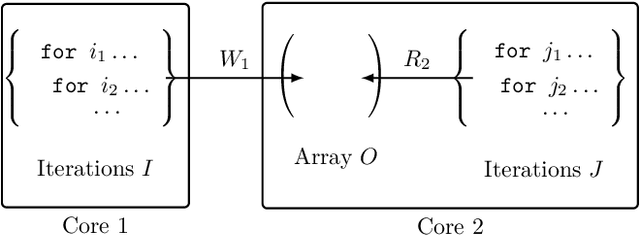
In this paper we propose a novel parallel stochastic coordinate descent (SCD) algorithm with convergence guarantees that exhibits strong scalability. We start by studying a state-of-the-art parallel implementation of SCD and identify scalability as well as system-level performance bottlenecks of the respective implementation. We then take a principled approach to develop a new SCD variant which is designed to avoid the identified system bottlenecks, such as limited scaling due to coherence traffic of model sharing across threads, and inefficient CPU cache accesses. Our proposed system-aware parallel coordinate descent algorithm (SySCD) scales to many cores and across numa nodes, and offers a consistent bottom line speedup in training time of up to x12 compared to an optimized asynchronous parallel SCD algorithm and up to x42, compared to state-of-the-art GLM solvers (scikit-learn, Vowpal Wabbit, and H2O) on a range of datasets and multi-core CPU architectures.
Breadth-first, Depth-next Training of Random Forests
Oct 15, 2019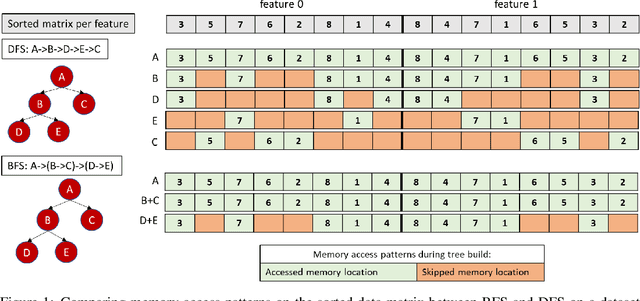
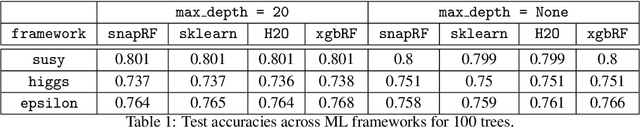
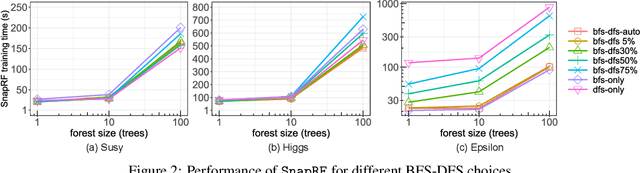
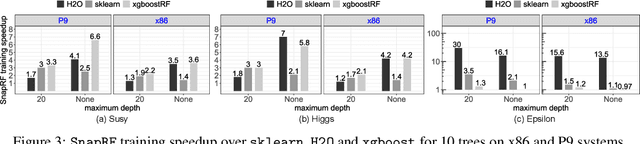
In this paper we analyze, evaluate, and improve the performance of training Random Forest (RF) models on modern CPU architectures. An exact, state-of-the-art binary decision tree building algorithm is used as the basis of this study. Firstly, we investigate the trade-offs between using different tree building algorithms, namely breadth-first-search (BFS) and depth-search-first (DFS). We design a novel, dynamic, hybrid BFS-DFS algorithm and demonstrate that it performs better than both BFS and DFS, and is more robust in the presence of workloads with different characteristics. Secondly, we identify CPU performance bottlenecks when generating trees using this approach, and propose optimizations to alleviate them. The proposed hybrid tree building algorithm for RF is implemented in the Snap Machine Learning framework, and speeds up the training of RFs by 7.8x on average when compared to state-of-the-art RF solvers (sklearn, H2O, and xgboost) on a range of datasets, RF configurations, and multi-core CPU architectures.
Parallel training of linear models without compromising convergence
Nov 05, 2018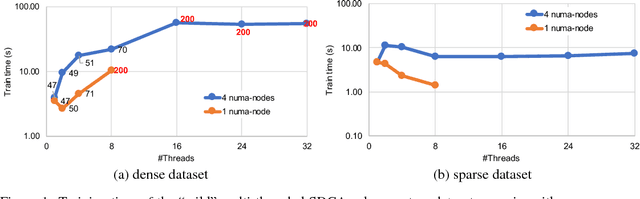
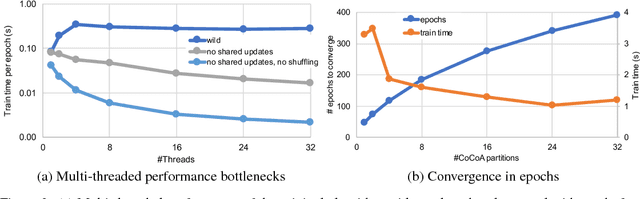
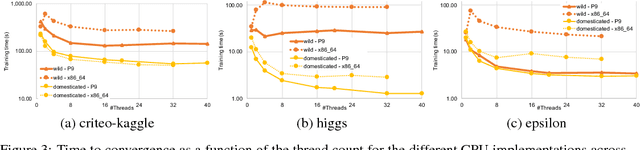
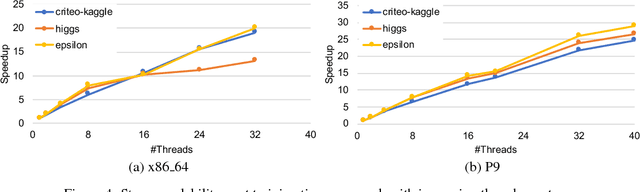
In this paper we analyze, evaluate, and improve the performance of training generalized linear models on modern CPUs. We start with a state-of-the-art asynchronous parallel training algorithm, identify system-level performance bottlenecks, and apply optimizations that improve data parallelism, cache line locality, and cache line prefetching of the algorithm. These modifications reduce the per-epoch run-time significantly, but take a toll on algorithm convergence in terms of the required number of epochs. To alleviate these shortcomings of our systems-optimized version, we propose a novel, dynamic data partitioning scheme across threads which allows us to approach the convergence of the sequential version. The combined set of optimizations result in a consistent bottom line speedup in convergence of up to $\times12$ compared to the initial asynchronous parallel training algorithm and up to $\times42$, compared to state of the art implementations (scikit-learn and h2o) on a range of multi-core CPU architectures.
Snap ML: A Hierarchical Framework for Machine Learning
Jun 18, 2018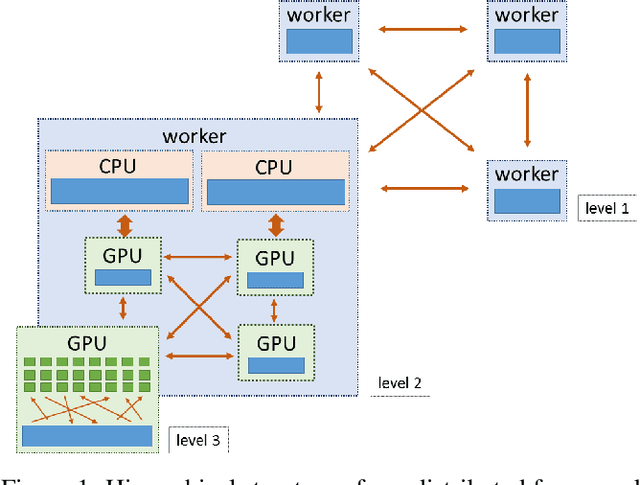

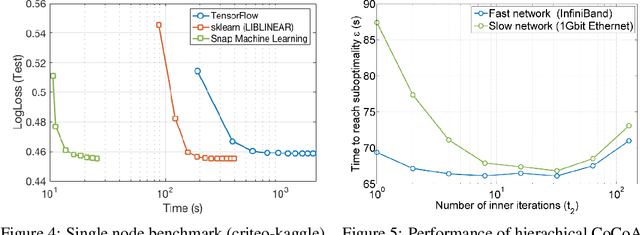
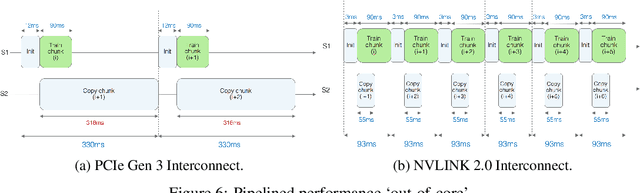
We describe a new software framework for fast training of generalized linear models. The framework, named Snap Machine Learning (Snap ML), combines recent advances in machine learning systems and algorithms in a nested manner to reflect the hierarchical architecture of modern computing systems. We prove theoretically that such a hierarchical system can accelerate training in distributed environments where intra-node communication is cheaper than inter-node communication. Additionally, we provide a review of the implementation of Snap ML in terms of GPU acceleration, pipelining, communication patterns and software architecture, highlighting aspects that were critical for achieving high performance. We evaluate the performance of Snap ML in both single-node and multi-node environments, quantifying the benefit of the hierarchical scheme and the data streaming functionality, and comparing with other widely-used machine learning software frameworks. Finally, we present a logistic regression benchmark on the Criteo Terabyte Click Logs dataset and show that Snap ML achieves the same test loss an order of magnitude faster than any of the previously reported results.