 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a General Framework for ML-based Self-tuning Databases
Nov 16, 2020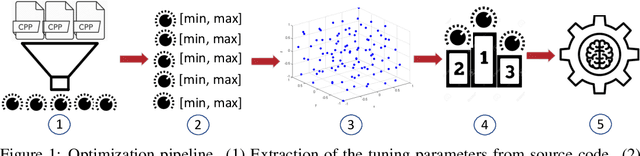
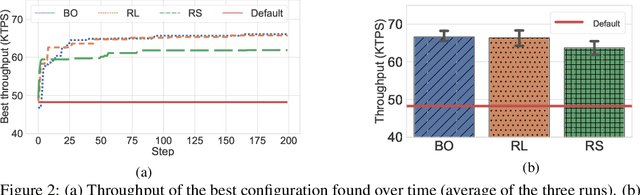
Machine learning (ML) methods have recently emerged as an effective way to perform automated parameter tuning of databases. State-of-the-art approaches include Bayesian optimization (BO) and reinforcement learning (RL). In this work, we describe our experience when applying these methods to a database not yet studied in this context: FoundationDB. Firstly, we describe the challenges we faced, such as unknown valid ranges of configuration parameters and combinations of parameter values that result in invalid runs, and how we mitigated them. While these issues are typically overlooked, we argue that they are a crucial barrier to the adoption of ML self-tuning techniques in databases, and thus deserve more attention from the research community. Secondly, we present experimental results obtained when tuning FoundationDB using ML methods. Unlike prior work in this domain, we also compare with the simplest of baselines: random search. Our results show that, while BO and RL methods can improve the throughput of FoundationDB by up to 38%, random search is a highly competitive baseline, finding a configuration that is only 4% worse than the, vastly more complex, ML methods. We conclude that future work in this area may want to focus more on randomized, model-free optimization algorithms.