 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-type Disentanglement without Adversarial Training
Dec 16, 2020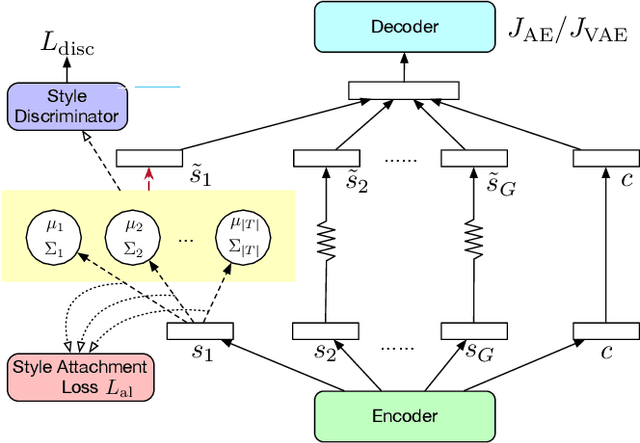
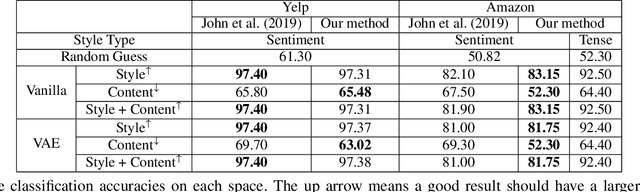
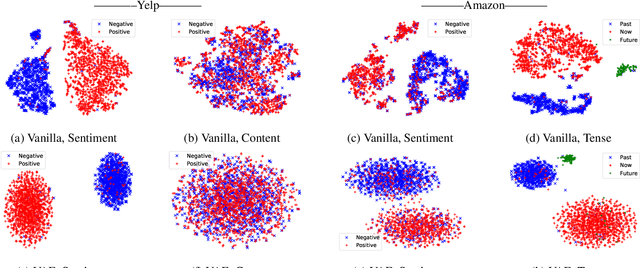
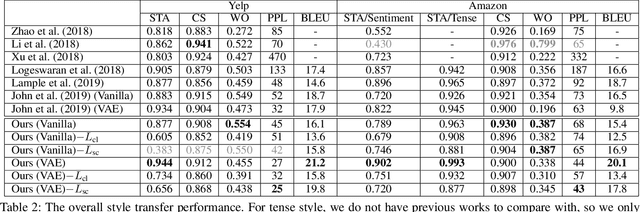
Controlling the style of natural language by disentangling the latent space is an important step towards interpretable machine learning. After the latent space is disentangled, the style of a sentence can be transformed by tuning the style representation without affecting other features of the sentence. Previous works usually use adversarial training to guarantee that disentangled vectors do not affect each other. However, adversarial methods are difficult to train. Especially when there are multiple features (e.g., sentiment, or tense, which we call style types in this paper), each feature requires a separate discriminator for extracting a disentangled style vector corresponding to that feature. In this paper, we propose a unified distribution-controlling method, which provides each specific style value (the value of style types, e.g., positive sentiment, or past tense) with a unique representation. This method contributes a solid theoretical basis to avoid adversarial training in multi-type disentanglement. We also propose multiple loss functions to achieve a style-content disentanglement as well as a disentanglement among multiple style types. In addition, we observe that if two different style types always have some specific style values that occur together in the dataset, they will affect each other when transferring the style values. We call this phenomenon training bias, and we propose a loss function to alleviate such training bias while disentangling multiple types. We conduct experiments on two datasets (Yelp service reviews and Amazon product reviews) to evaluate the style-disentangling effect and the unsupervised style transfer performance on two style types: sentiment and tense. The experimental results show the effectiveness of our model.
Reinforced Medical Report Generation with X-Linear Attention and Repetition Penalty
Nov 16, 2020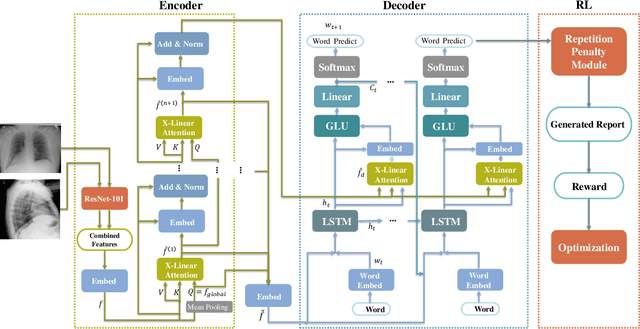
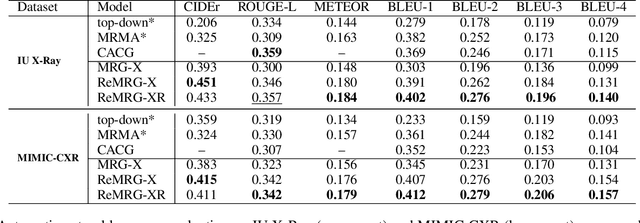

To reduce doctors' workload, deep-learning-based automatic medical report generation has recently attracted more and more research efforts, where attention mechanisms and reinforcement learning are integrated with the classic encoder-decoder architecture to enhance the performance of deep models. However, these state-of-the-art solutions mainly suffer from two shortcomings: (i) their attention mechanisms cannot utilize high-order feature interactions, and (ii) due to the use of TF-IDF-based reward functions, these methods are fragile with generating repeated terms. Therefore, in this work, we propose a reinforced medical report generation solution with x-linear attention and repetition penalty mechanisms (ReMRG-XR) to overcome these problems. Specifically, x-linear attention modules are used to explore high-order feature interactions and achieve multi-modal reasoning, while repetition penalty is used to apply penalties to repeated terms during the model's training process. Extensive experimental studies have been conducted on two public datasets, and the results show that ReMRG-XR greatly outperforms the state-of-the-art baselines in terms of all metrics.
SAG-GAN: Semi-Supervised Attention-Guided GANs for Data Augmentation on Medical Images
Nov 15, 2020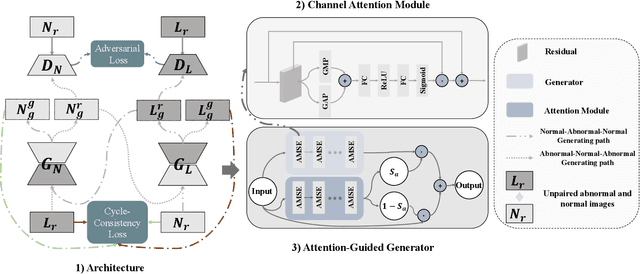
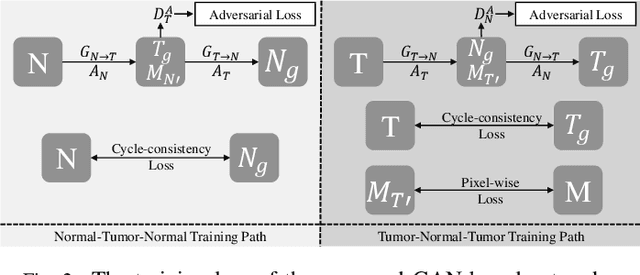
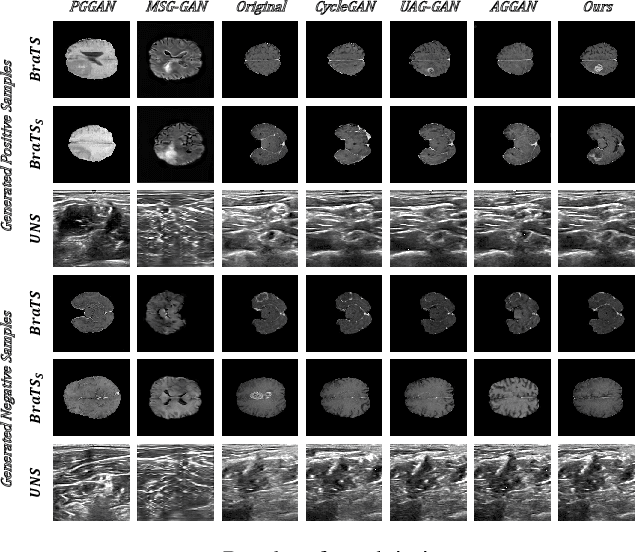
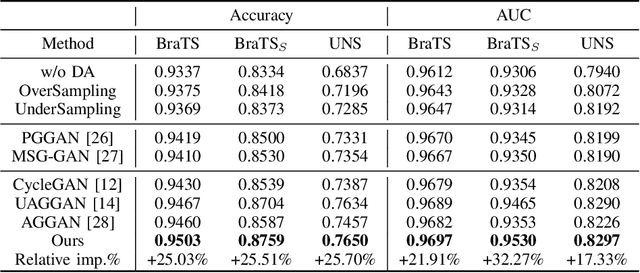
Recently deep learning methods, in particular, convolutional neural networks (CNNs), have led to a massive breakthrough in the range of computer vision. Also, the large-scale annotated dataset is the essential key to a successful training procedure. However, it is a huge challenge to get such datasets in the medical domain. Towards this, we present a data augmentation method for generating synthetic medical images using cycle-consistency Generative Adversarial Networks (GANs). We add semi-supervised attention modules to generate images with convincing details. We treat tumor images and normal images as two domains. The proposed GANs-based model can generate a tumor image from a normal image, and in turn, it can also generate a normal image from a tumor image. Furthermore, we show that generated medical images can be used for improving the performance of ResNet18 for medical image classification. Our model is applied to three limited datasets of tumor MRI images. We first generate MRI images on limited datasets, then we trained three popular classification models to get the best model for tumor classification. Finally, we train the classification model using real images with classic data augmentation methods and classification models using synthetic images. The classification results between those trained models showed that the proposed SAG-GAN data augmentation method can boost Accuracy and AUC compare with classic data augmentation methods. We believe the proposed data augmentation method can apply to other medical image domains, and improve the accuracy of computer-assisted diagnosis.
w-Net: Dual Supervised Medical Image Segmentation Model with Multi-Dimensional Attention and Cascade Multi-Scale Convolution
Nov 15, 2020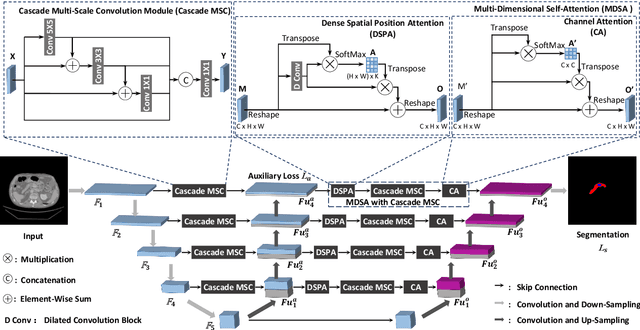
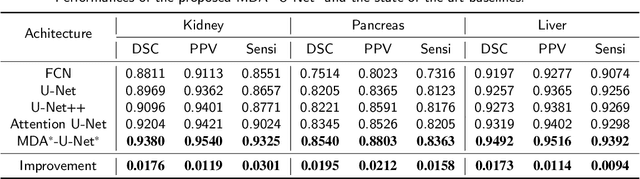
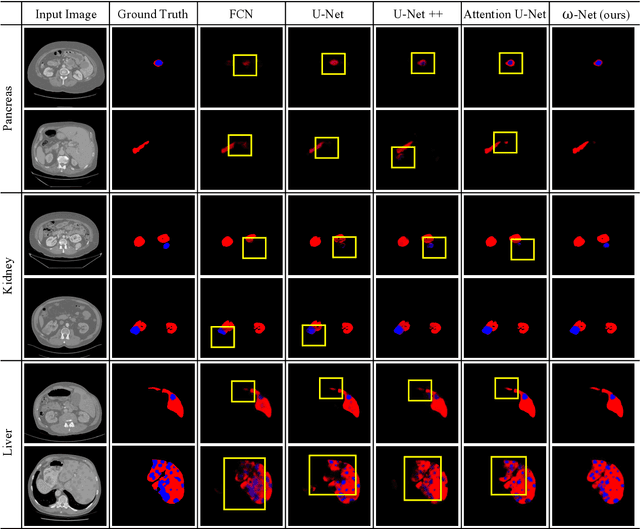
Deep learning-based medical image segmentation technology aims at automatic recognizing and annotating objects on the medical image. Non-local attention and feature learning by multi-scale methods are widely used to model network, which drives progress in medical image segmentation. However, those attention mechanism methods have weakly non-local receptive fields' strengthened connection for small objects in medical images. Then, the features of important small objects in abstract or coarse feature maps may be deserted, which leads to unsatisfactory performance. Moreover, the existing multi-scale methods only simply focus on different sizes of view, whose sparse multi-scale features collected are not abundant enough for small objects segmentation. In this work, a multi-dimensional attention segmentation model with cascade multi-scale convolution is proposed to predict accurate segmentation for small objects in medical images. As the weight function, multi-dimensional attention modules provide coefficient modification for significant/informative small objects features. Furthermore, The cascade multi-scale convolution modules in each skip-connection path are exploited to capture multi-scale features in different semantic depth. The proposed method is evaluated on three datasets: KiTS19, Pancreas CT of Decathlon-10, and MICCAI 2018 LiTS Challenge, demonstrating better segmentation performances than the state-of-the-art baselines.
Efficient Medical Image Segmentation with Intermediate Supervision Mechanism
Nov 15, 2020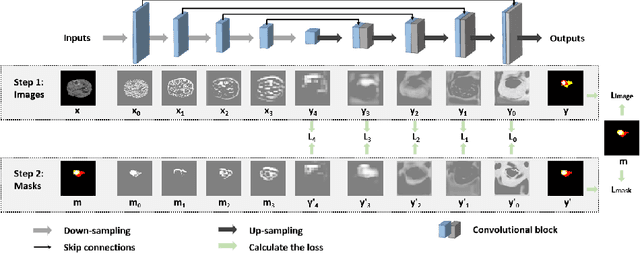
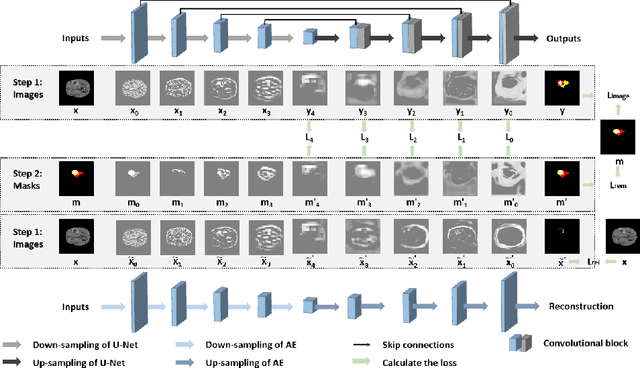
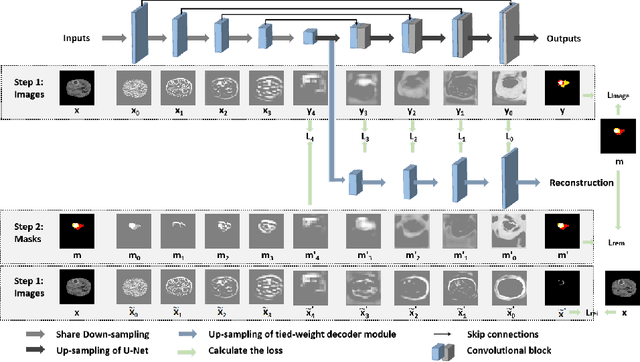
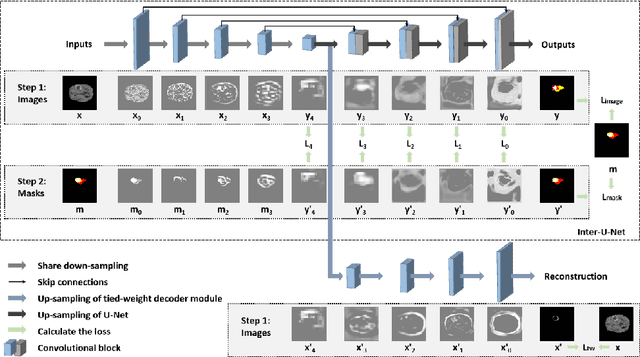
Because the expansion path of U-Net may ignore the characteristics of small targets, intermediate supervision mechanism is proposed. The original mask is also entered into the network as a label for intermediate output. However, U-Net is mainly engaged in segmentation, and the extracted features are also targeted at segmentation location information, and the input and output are different. The label we need is that the input and output are both original masks, which is more similar to the refactoring process, so we propose another intermediate supervision mechanism. However, the features extracted by the contraction path of this intermediate monitoring mechanism are not necessarily consistent. For example, U-Net's contraction path extracts transverse features, while auto-encoder extracts longitudinal features, which may cause the output of the expansion path to be inconsistent with the label. Therefore, we put forward the intermediate supervision mechanism of shared-weight decoder module. Although the intermediate supervision mechanism improves the segmentation accuracy, the training time is too long due to the extra input and multiple loss functions. For one of these problems, we have introduced tied-weight decoder. To reduce the redundancy of the model, we combine shared-weight decoder module with tied-weight decoder module.
The Gap on GAP: Tackling the Problem of Differing Data Distributions in Bias-Measuring Datasets
Nov 12, 2020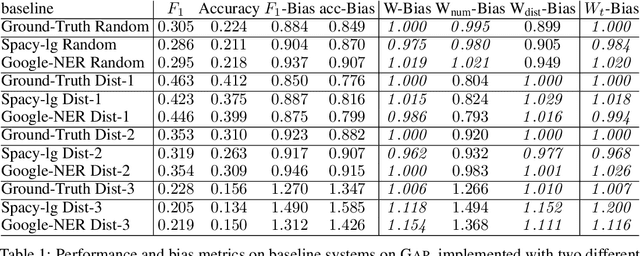
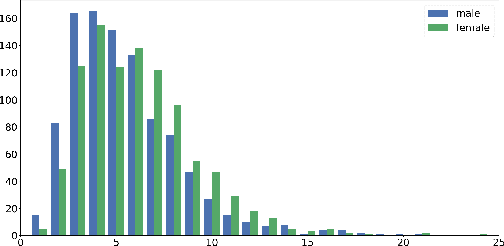
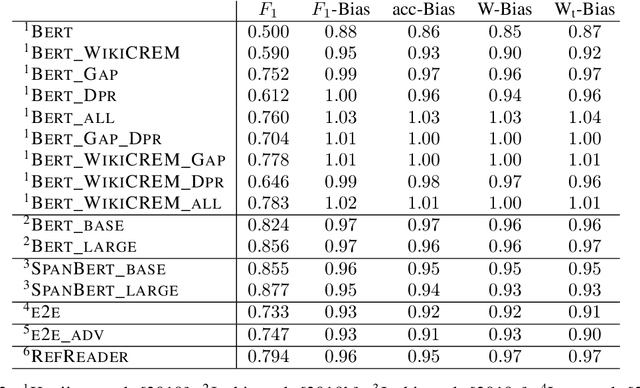
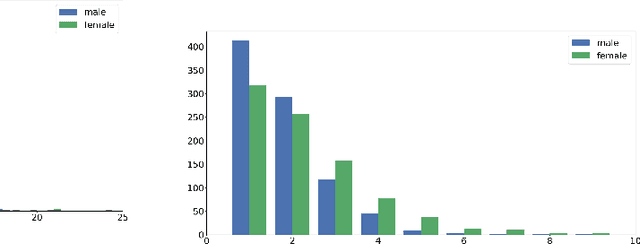
Diagnostic datasets that can detect biased models are an important prerequisite for bias reduction within natural language processing. However, undesired patterns in the collected data can make such tests incorrect. For example, if the feminine subset of a gender-bias-measuring coreference resolution dataset contains sentences with a longer average distance between the pronoun and the correct candidate, an RNN-based model may perform worse on this subset due to long-term dependencies. In this work, we introduce a theoretically grounded method for weighting test samples to cope with such patterns in the test data. We demonstrate the method on the GAP dataset for coreference resolution. We annotate GAP with spans of all personal names and show that examples in the female subset contain more personal names and a longer distance between pronouns and their referents, potentially affecting the bias score in an undesired way. Using our weighting method, we find the set of weights on the test instances that should be used for coping with these correlations, and we re-evaluate 16 recently released coreference models.
Deep Learning in Computer-Aided Diagnosis and Treatment of Tumors: A Survey
Nov 02, 2020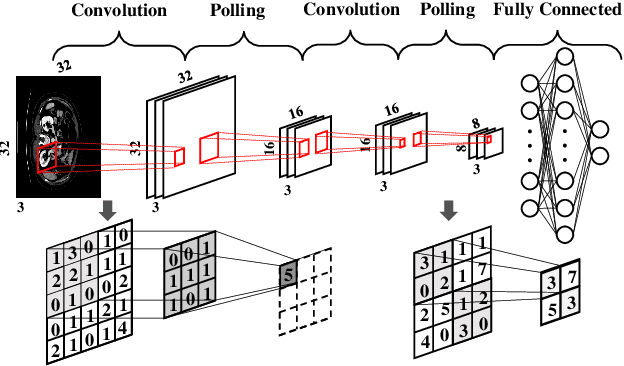
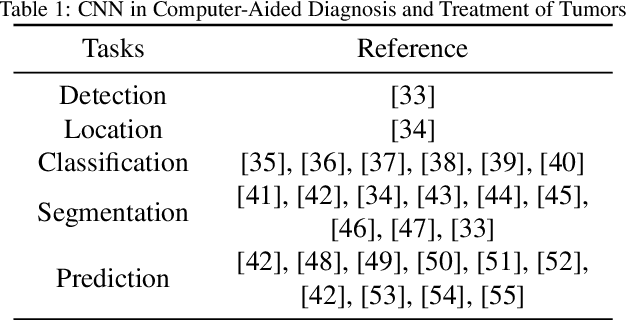
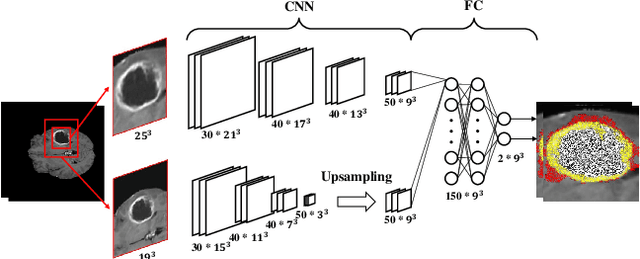

Computer-Aided Diagnosis and Treatment of Tumors is a hot topic of deep learning in recent years, which constitutes a series of medical tasks, such as detection of tumor markers, the outline of tumor leisures, subtypes and stages of tumors, prediction of therapeutic effect, and drug development. Meanwhile, there are some deep learning models with precise positioning and excellent performance produced in mainstream task scenarios. Thus follow to introduce deep learning methods from task-orient, mainly focus on the improvements for medical tasks. Then to summarize the recent progress in four stages of tumor diagnosis and treatment, which named In-Vitro Diagnosis (IVD), Imaging Diagnosis (ID), Pathological Diagnosis (PD), and Treatment Planning (TP). According to the specific data types and medical tasks of each stage, we present the applications of deep learning in the Computer-Aided Diagnosis and Treatment of Tumors and analyzing the excellent works therein. This survey concludes by discussing research issues and suggesting challenges for future improvement.
Lightweight Generative Adversarial Networks for Text-Guided Image Manipulation
Oct 23, 2020
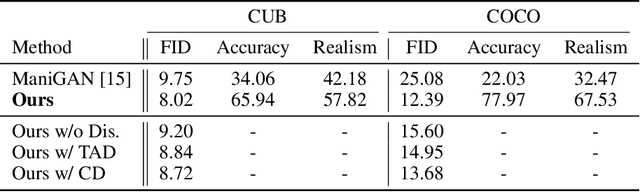
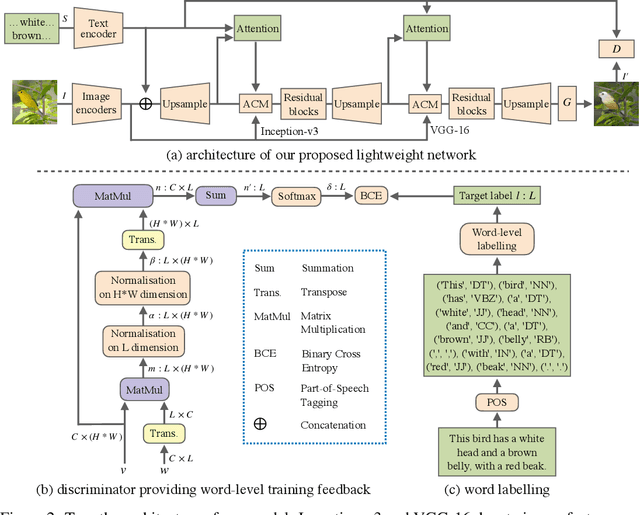

We propose a novel lightweight generative adversarial network for efficient image manipulation using natural language descriptions. To achieve this, a new word-level discriminator is proposed, which provides the generator with fine-grained training feedback at word-level, to facilitate training a lightweight generator that has a small number of parameters, but can still correctly focus on specific visual attributes of an image, and then edit them without affecting other contents that are not described in the text. Furthermore, thanks to the explicit training signal related to each word, the discriminator can also be simplified to have a lightweight structure. Compared with the state of the art, our method has a much smaller number of parameters, but still achieves a competitive manipulation performance. Extensive experimental results demonstrate that our method can better disentangle different visual attributes, then correctly map them to corresponding semantic words, and thus achieve a more accurate image modification using natural language descriptions.
Coherent Hierarchical Multi-Label Classification Networks
Oct 20, 2020
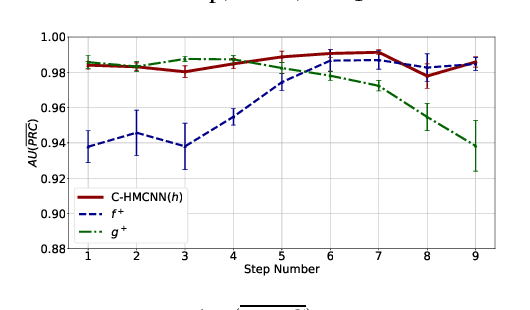
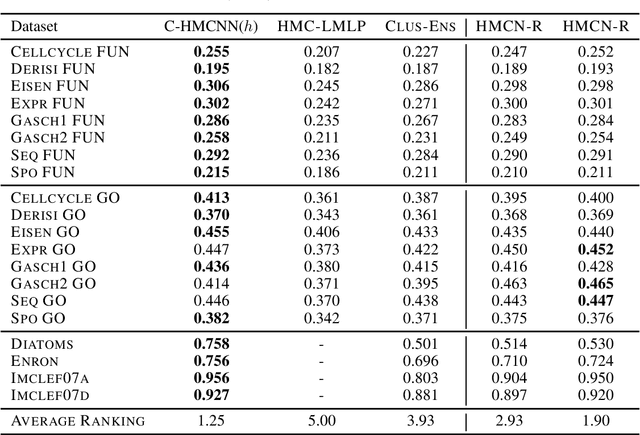
Hierarchical multi-label classification (HMC) is a challenging classification task extending standard multi-label classification problems by imposing a hierarchy constraint on the classes. In this paper, we propose C-HMCNN(h), a novel approach for HMC problems, which, given a network h for the underlying multi-label classification problem, exploits the hierarchy information in order to produce predictions coherent with the constraint and improve performance. We conduct an extensive experimental analysis showing the superior performance of C-HMCNN(h) when compared to state-of-the-art models.
Does the Objective Matter? Comparing Training Objectives for Pronoun Resolution
Oct 06, 2020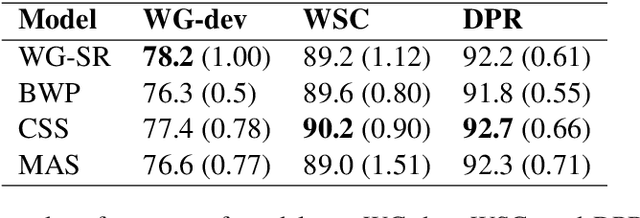
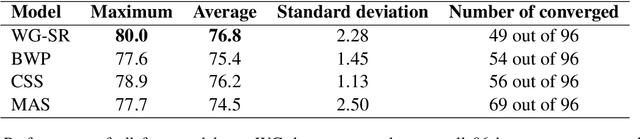
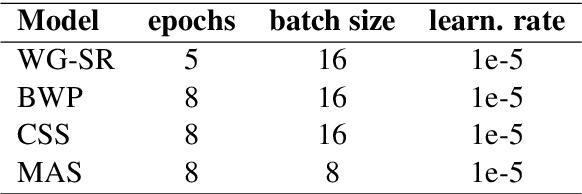
Hard cases of pronoun resolution have been used as a long-standing benchmark for commonsense reasoning. In the recent literature, pre-trained language models have been used to obtain state-of-the-art results on pronoun resolution. Overall, four categories of training and evaluation objectives have been introduced. The variety of training datasets and pre-trained language models used in these works makes it unclear whether the choice of training objective is critical. In this work, we make a fair comparison of the performance and seed-wise stability of four models that represent the four categories of objectives. Our experiments show that the objective of sequence ranking performs the best in-domain, while the objective of semantic similarity between candidates and pronoun performs the best out-of-domain. We also observe a seed-wise instability of the model using sequence ranking, which is not the case when the other objectives are used.