 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Distillation for Language Models
Dec 05, 2021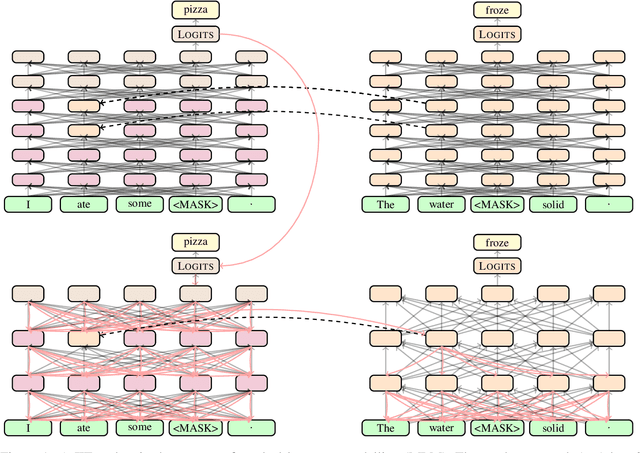

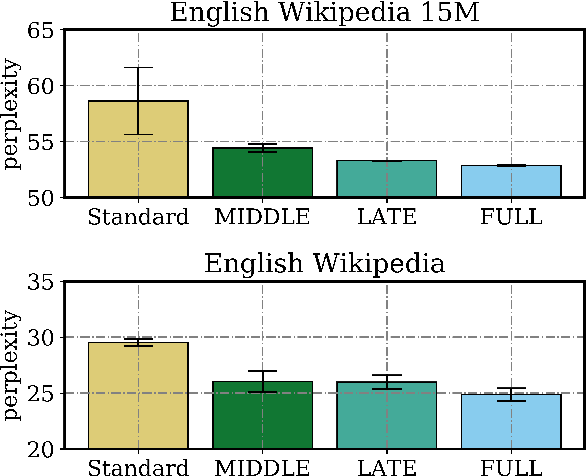
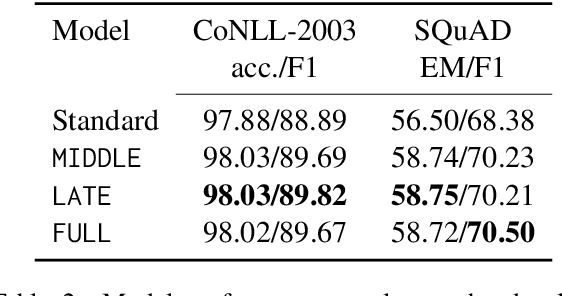
Distillation efforts have led to language models that are more compact and efficient without serious drops in performance. The standard approach to distillation trains a student model against two objectives: a task-specific objective (e.g., language modeling) and an imitation objective that encourages the hidden states of the student model to be similar to those of the larger teacher model. In this paper, we show that it is beneficial to augment distillation with a third objective that encourages the student to imitate the causal computation process of the teacher through interchange intervention training(IIT). IIT pushes the student model to become a causal abstraction of the teacher model - a simpler model with the same causal structure. IIT is fully differentiable, easily implemented, and combines flexibly with other objectives. Compared with standard distillation of BERT, distillation via IIT results in lower perplexity on Wikipedia (masked language modeling) and marked improvements on the GLUE benchmark (natural language understanding), SQuAD (question answering), and CoNLL-2003 (named entity recognition).
Inducing Causal Structure for Interpretable Neural Networks
Dec 01, 2021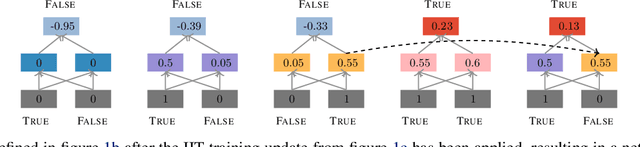
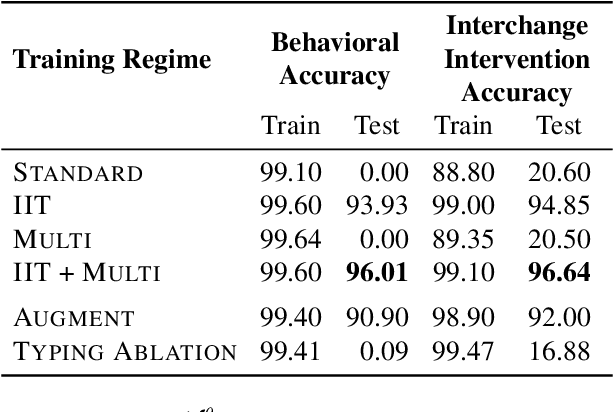
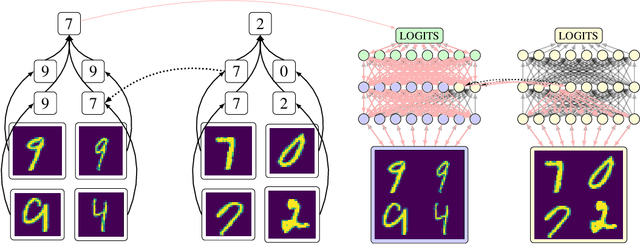
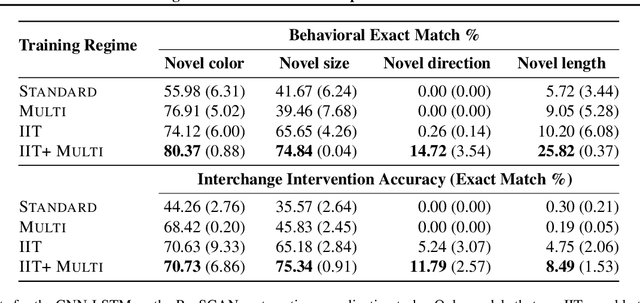
In many areas, we have well-founded insights about causal structure that would be useful to bring into our trained models while still allowing them to learn in a data-driven fashion. To achieve this, we present the new method of interchange intervention training(IIT). In IIT, we (1)align variables in the causal model with representations in the neural model and (2) train a neural model to match the counterfactual behavior of the causal model on a base input when aligned representations in both models are set to be the value they would be for a second source input. IIT is fully differentiable, flexibly combines with other objectives, and guarantees that the target causal model is acausal abstraction of the neural model when its loss is minimized. We evaluate IIT on a structured vision task (MNIST-PVR) and a navigational instruction task (ReaSCAN). We compare IIT against multi-task training objectives and data augmentation. In all our experiments, IIT achieves the best results and produces neural models that are more interpretable in the sense that they realize the target causal model.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
A Topological Perspective on Causal Inference
Jul 18, 2021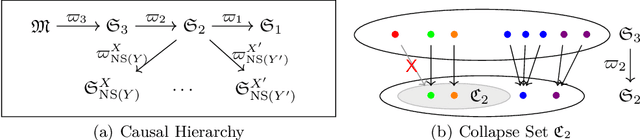
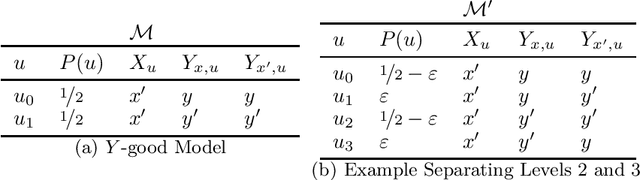
This paper presents a topological learning-theoretic perspective on causal inference by introducing a series of topologies defined on general spaces of structural causal models (SCMs). As an illustration of the framework we prove a topological causal hierarchy theorem, showing that substantive assumption-free causal inference is possible only in a meager set of SCMs. Thanks to a known correspondence between open sets in the weak topology and statistically verifiable hypotheses, our results show that inductive assumptions sufficient to license valid causal inferences are statistically unverifiable in principle. Similar to no-free-lunch theorems for statistical inference, the present results clarify the inevitability of substantial assumptions for causal inference. An additional benefit of our topological approach is that it easily accommodates SCMs with infinitely many variables. We finally suggest that the framework may be helpful for the positive project of exploring and assessing alternative causal-inductive assumptions.
Causal Abstractions of Neural Networks
Jun 06, 2021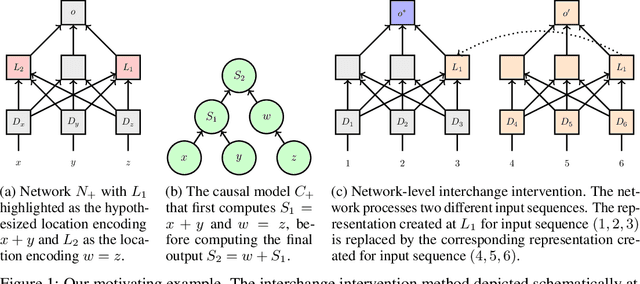


Structural analysis methods (e.g., probing and feature attribution) are increasingly important tools for neural network analysis. We propose a new structural analysis method grounded in a formal theory of \textit{causal abstraction} that provides rich characterizations of model-internal representations and their roles in input/output behavior. In this method, neural representations are aligned with variables in interpretable causal models, and then \textit{interchange interventions} are used to experimentally verify that the neural representations have the causal properties of their aligned variables. We apply this method in a case study to analyze neural models trained on Multiply Quantified Natural Language Inference (MQNLI) corpus, a highly complex NLI dataset that was constructed with a tree-structured natural logic causal model. We discover that a BERT-based model with state-of-the-art performance successfully realizes the approximate causal structure of the natural logic causal model, whereas a simpler baseline model fails to show any such structure, demonstrating that neural representations encode the compositional structure of MQNLI examples.
Intention as Commitment toward Time
Apr 17, 2020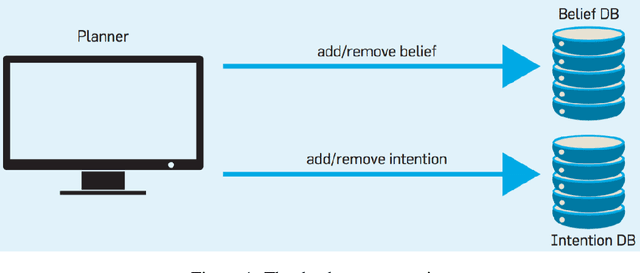
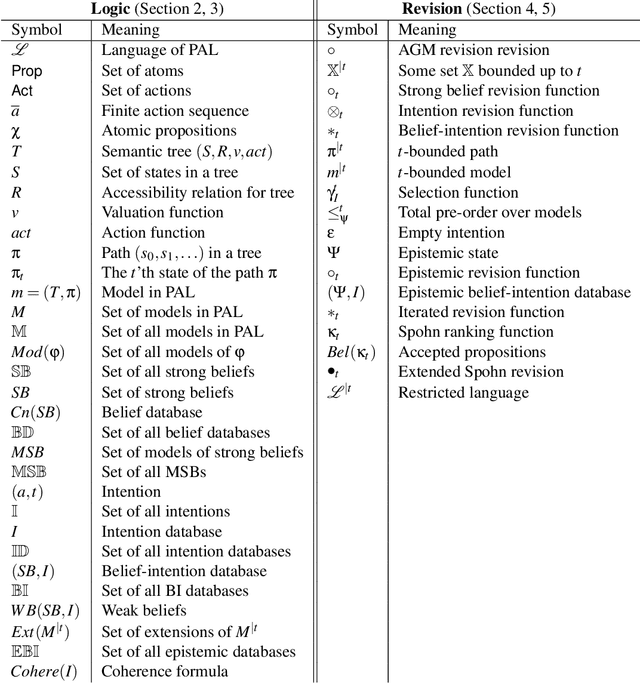
In this paper we address the interplay among intention, time, and belief in dynamic environments. The first contribution is a logic for reasoning about intention, time and belief, in which assumptions of intentions are represented by preconditions of intended actions. Intentions and beliefs are coherent as long as these assumptions are not violated, i.e. as long as intended actions can be performed such that their preconditions hold as well. The second contribution is the formalization of what-if scenarios: what happens with intentions and beliefs if a new (possibly conflicting) intention is adopted, or a new fact is learned? An agent is committed to its intended actions as long as its belief-intention database is coherent. We conceptualize intention as commitment toward time and we develop AGM-based postulates for the iterated revision of belief-intention databases, and we prove a Katsuno-Mendelzon-style representation theorem.
* 83 pages, 4 figures, Artificial Intelligence journal pre-print
Probabilistic Reasoning across the Causal Hierarchy
Feb 08, 2020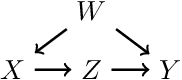
We propose a formalization of the three-tier causal hierarchy of association, intervention, and counterfactuals as a series of probabilistic logical languages. Our languages are of strictly increasing expressivity, the first capable of expressing quantitative probabilistic reasoning---including conditional independence and Bayesian inference---the second encoding do-calculus reasoning for causal effects, and the third capturing a fully expressive do-calculus for arbitrary counterfactual queries. We give a corresponding series of finitary axiomatizations complete over both structural causal models and probabilistic programs, and show that satisfiability and validity for each language are decidable in polynomial space.
On Open-Universe Causal Reasoning
Jul 04, 2019We extend two kinds of causal models, structural equation models and simulation models, to infinite variable spaces. This enables a semantics for conditionals founded on a calculus of intervention, and axiomatization of causal reasoning for rich, expressive generative models---including those in which a causal representation exists only implicitly---in an open-universe setting. Further, we show that under suitable restrictions the two kinds of models are equivalent, perhaps surprisingly as their axiomatizations differ substantially in the general case. We give a series of complete axiomatizations in which the open-universe nature of the setting is seen to be essential.
On the Conditional Logic of Simulation Models
May 08, 2018We propose analyzing conditional reasoning by appeal to a notion of intervention on a simulation program, formalizing and subsuming a number of approaches to conditional thinking in the recent AI literature. Our main results include a series of axiomatizations, allowing comparison between this framework and existing frameworks (normality-ordering models, causal structural equation models), and a complexity result establishing NP-completeness of the satisfiability problem. Perhaps surprisingly, some of the basic logical principles common to all existing approaches are invalidated in our causal simulation approach. We suggest that this additional flexibility is important in modeling some intuitive examples.