 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Networks for Image Super-Resolution with Sparse Prior
Oct 15, 2015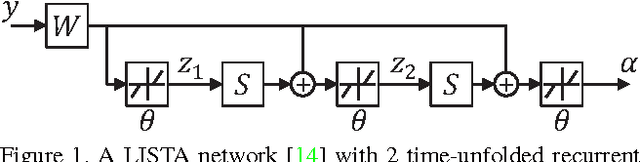
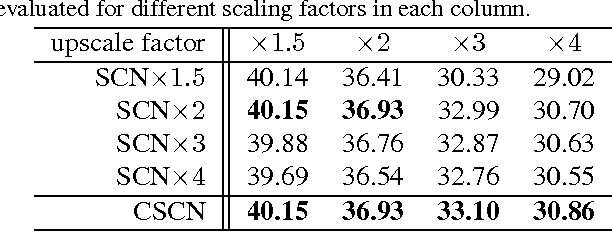
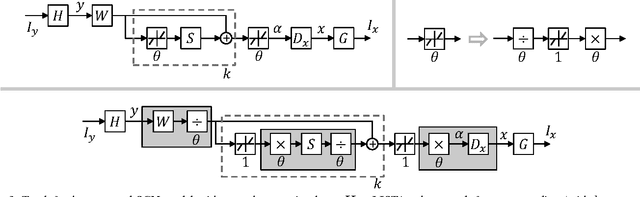

Deep learning techniques have been successfully applied in many areas of computer vision, including low-level image restoration problems. For image super-resolution, several models based on deep neural networks have been recently proposed and attained superior performance that overshadows all previous handcrafted models. The question then arises whether large-capacity and data-driven models have become the dominant solution to the ill-posed super-resolution problem. In this paper, we argue that domain expertise represented by the conventional sparse coding model is still valuable, and it can be combined with the key ingredients of deep learning to achieve further improved results. We show that a sparse coding model particularly designed for super-resolution can be incarnated as a neural network, and trained in a cascaded structure from end to end. The interpretation of the network based on sparse coding leads to much more efficient and effective training, as well as a reduced model size. Our model is evaluated on a wide range of images, and shows clear advantage over existing state-of-the-art methods in terms of both restoration accuracy and human subjective quality.
Scalable Similarity Learning using Large Margin Neighborhood Embedding
Apr 24, 2014


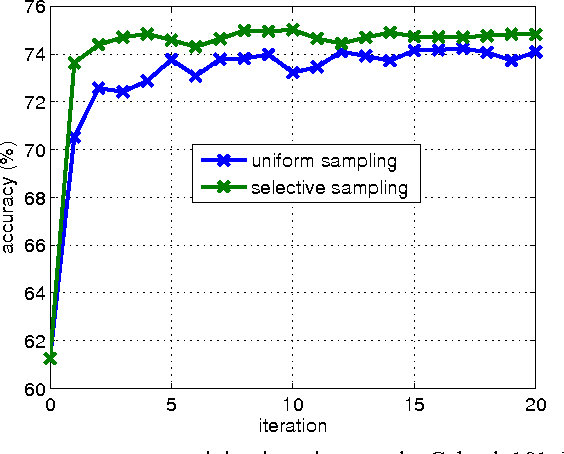
Classifying large-scale image data into object categories is an important problem that has received increasing research attention. Given the huge amount of data, non-parametric approaches such as nearest neighbor classifiers have shown promising results, especially when they are underpinned by a learned distance or similarity measurement. Although metric learning has been well studied in the past decades, most existing algorithms are impractical to handle large-scale data sets. In this paper, we present an image similarity learning method that can scale well in both the number of images and the dimensionality of image descriptors. To this end, similarity comparison is restricted to each sample's local neighbors and a discriminative similarity measure is induced from large margin neighborhood embedding. We also exploit the ensemble of projections so that high-dimensional features can be processed in a set of lower-dimensional subspaces in parallel without much performance compromise. The similarity function is learned online using a stochastic gradient descent algorithm in which the triplet sampling strategy is customized for quick convergence of classification performance. The effectiveness of our proposed model is validated on several data sets with scales varying from tens of thousands to one million images. Recognition accuracies competitive with the state-of-the-art performance are achieved with much higher efficiency and scalability.
GPU Asynchronous Stochastic Gradient Descent to Speed Up Neural Network Training
Dec 21, 2013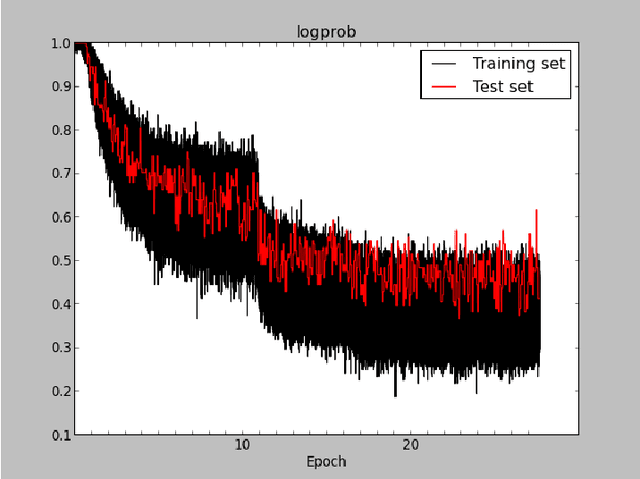
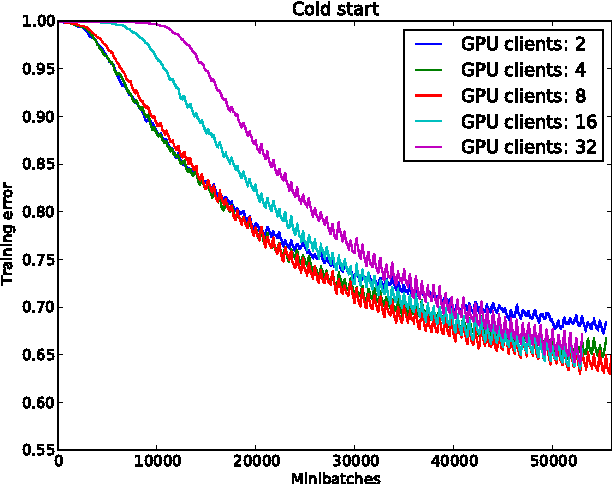
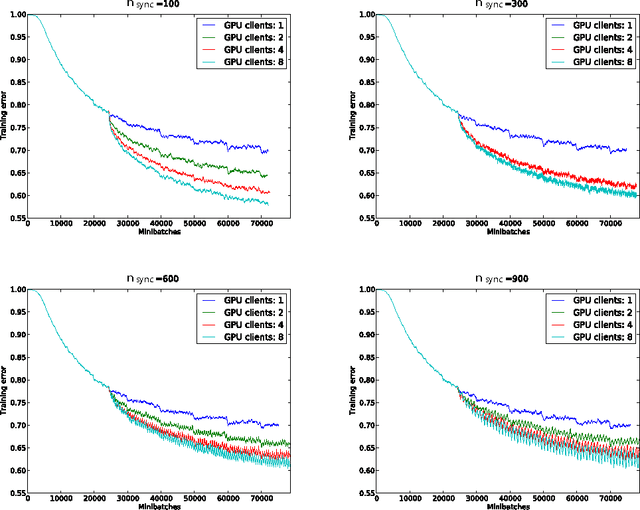
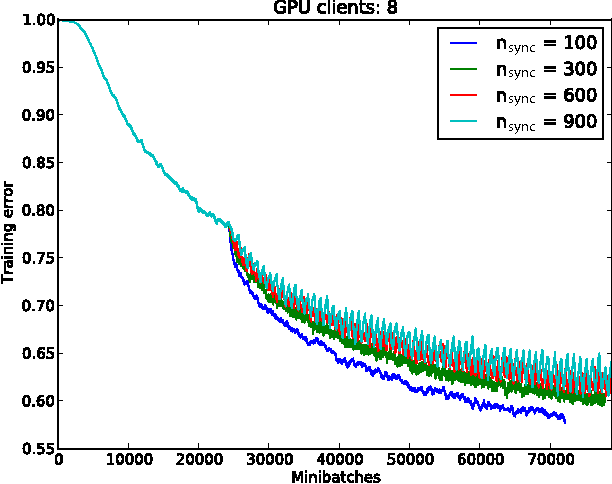
The ability to train large-scale neural networks has resulted in state-of-the-art performance in many areas of computer vision. These results have largely come from computational break throughs of two forms: model parallelism, e.g. GPU accelerated training, which has seen quick adoption in computer vision circles, and data parallelism, e.g. A-SGD, whose large scale has been used mostly in industry. We report early experiments with a system that makes use of both model parallelism and data parallelism, we call GPU A-SGD. We show using GPU A-SGD it is possible to speed up training of large convolutional neural networks useful for computer vision. We believe GPU A-SGD will make it possible to train larger networks on larger training sets in a reasonable amount of time.
Learning from Collective Intelligence in Groups
Oct 03, 2012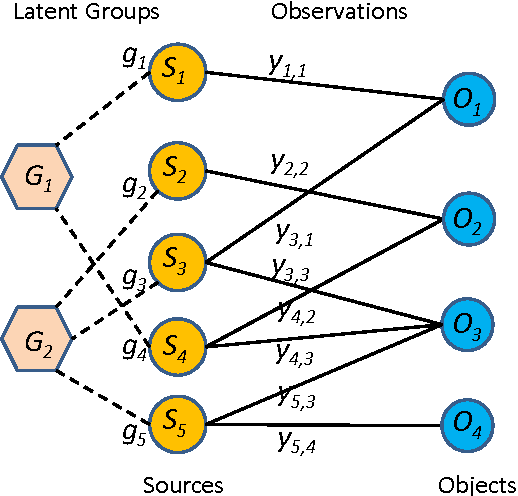

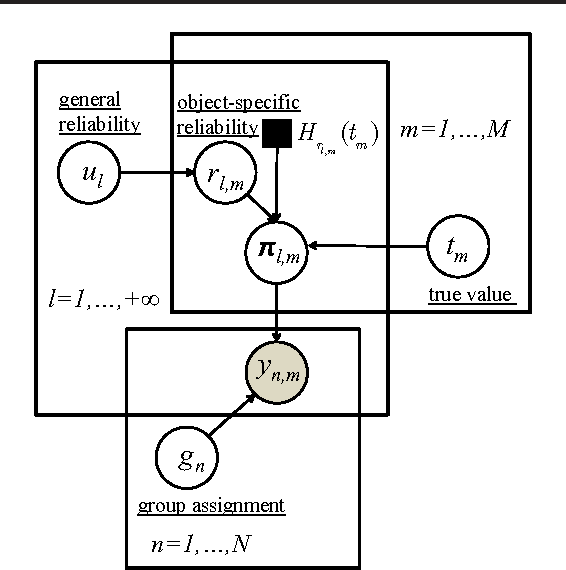

Collective intelligence, which aggregates the shared information from large crowds, is often negatively impacted by unreliable information sources with the low quality data. This becomes a barrier to the effective use of collective intelligence in a variety of applications. In order to address this issue, we propose a probabilistic model to jointly assess the reliability of sources and find the true data. We observe that different sources are often not independent of each other. Instead, sources are prone to be mutually influenced, which makes them dependent when sharing information with each other. High dependency between sources makes collective intelligence vulnerable to the overuse of redundant (and possibly incorrect) information from the dependent sources. Thus, we reveal the latent group structure among dependent sources, and aggregate the information at the group level rather than from individual sources directly. This can prevent the collective intelligence from being inappropriately dominated by dependent sources. We will also explicitly reveal the reliability of groups, and minimize the negative impacts of unreliable groups. Experimental results on real-world data sets show the effectiveness of the proposed approach with respect to existing algorithms.
Substructure and Boundary Modeling for Continuous Action Recognition
Mar 09, 2012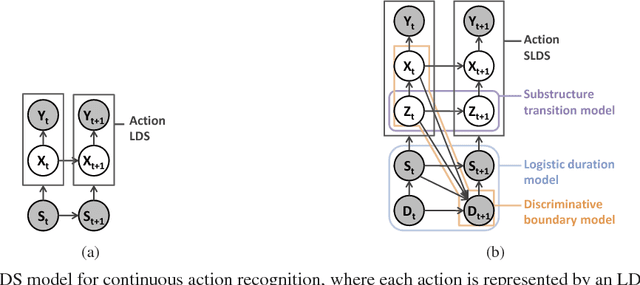

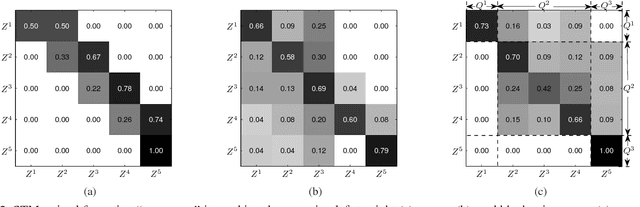
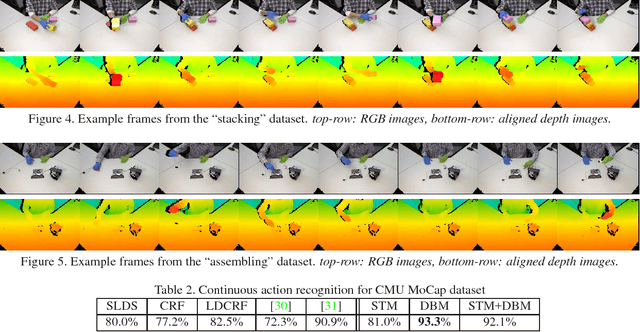
This paper introduces a probabilistic graphical model for continuous action recognition with two novel components: substructure transition model and discriminative boundary model. The first component encodes the sparse and global temporal transition prior between action primitives in state-space model to handle the large spatial-temporal variations within an action class. The second component enforces the action duration constraint in a discriminative way to locate the transition boundaries between actions more accurately. The two components are integrated into a unified graphical structure to enable effective training and inference. Our comprehensive experimental results on both public and in-house datasets show that, with the capability to incorporate additional information that had not been explicitly or efficiently modeled by previous methods, our proposed algorithm achieved significantly improved performance for continuous action recognition.