 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
Learning to Evaluate Translation Beyond English: BLEURT Submissions to the WMT Metrics 2020 Shared Task
Oct 19, 2020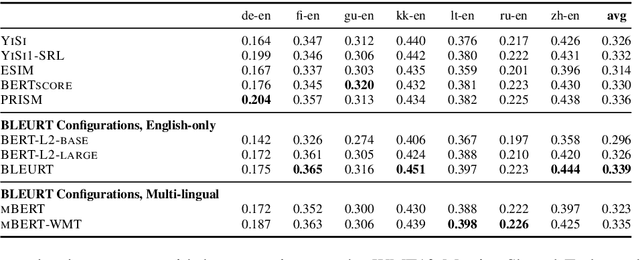
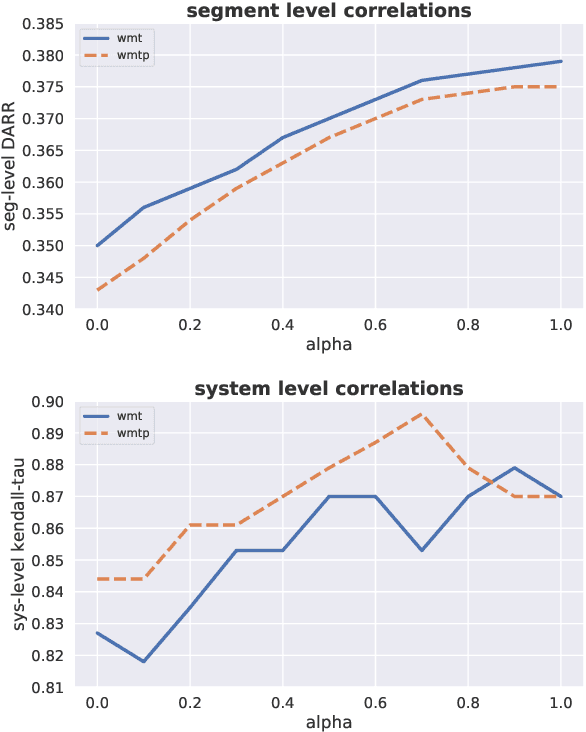
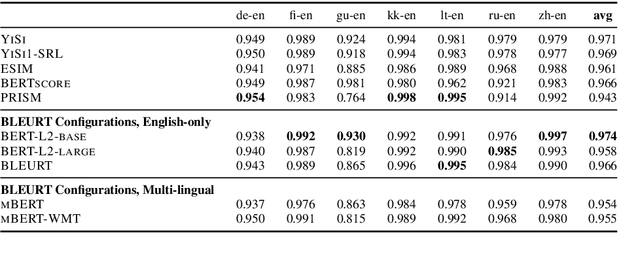
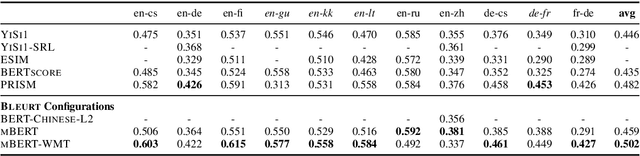
The quality of machine translation systems has dramatically improved over the last decade, and as a result, evaluation has become an increasingly challenging problem. This paper describes our contribution to the WMT 2020 Metrics Shared Task, the main benchmark for automatic evaluation of translation. We make several submissions based on BLEURT, a previously published metric based on transfer learning. We extend the metric beyond English and evaluate it on 14 language pairs for which fine-tuning data is available, as well as 4 "zero-shot" language pairs, for which we have no labelled examples. Additionally, we focus on English to German and demonstrate how to combine BLEURT's predictions with those of YiSi and use alternative reference translations to enhance the performance. Empirical results show that the models achieve competitive results on the WMT Metrics 2019 Shared Task, indicating their promise for the 2020 edition.
BLEURT: Learning Robust Metrics for Text Generation
May 14, 2020
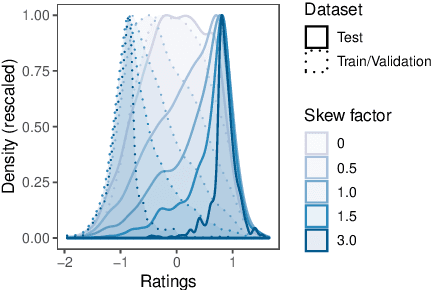
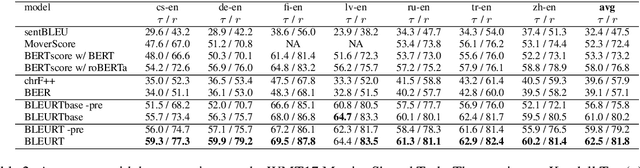
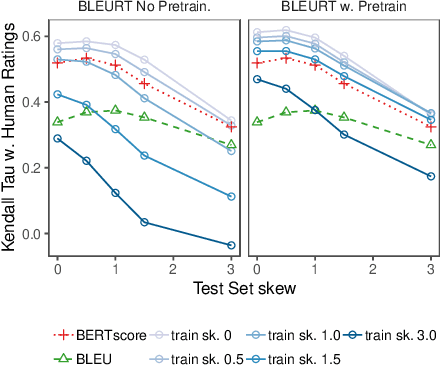
Text generation has made significant advances in the last few years. Yet, evaluation metrics have lagged behind, as the most popular choices (e.g., BLEU and ROUGE) may correlate poorly with human judgments. We propose BLEURT, a learned evaluation metric based on BERT that can model human judgments with a few thousand possibly biased training examples. A key aspect of our approach is a novel pre-training scheme that uses millions of synthetic examples to help the model generalize. BLEURT provides state-of-the-art results on the last three years of the WMT Metrics shared task and the WebNLG Competition dataset. In contrast to a vanilla BERT-based approach, it yields superior results even when the training data is scarce and out-of-distribution.
A Multilingual View of Unsupervised Machine Translation
Feb 21, 2020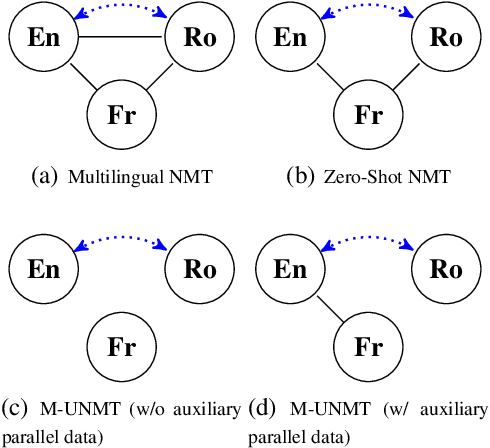
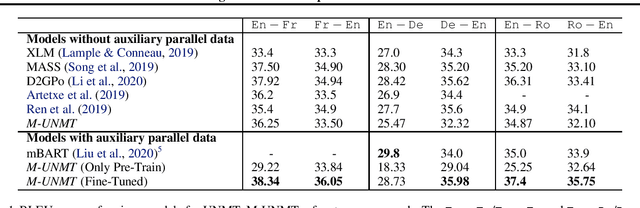
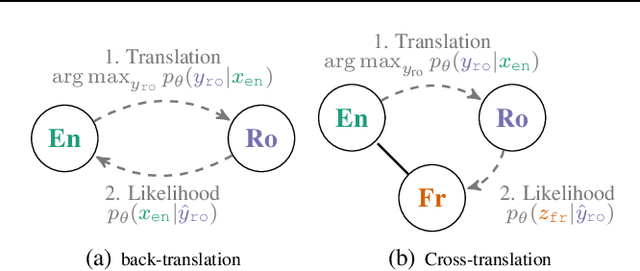
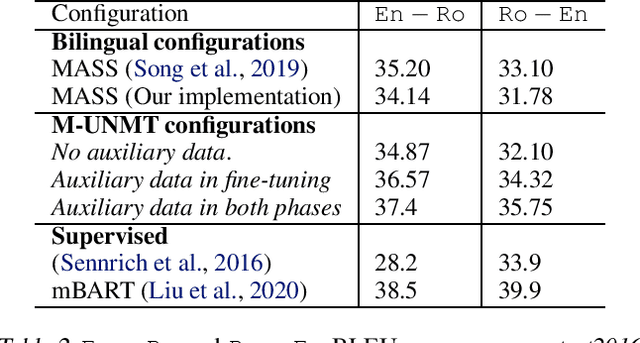
We present a probabilistic framework for multilingual neural machine translation that encompasses supervised and unsupervised setups, focusing on unsupervised translation. In addition to studying the vanilla case where there is only monolingual data available, we propose a novel setup where one language in the (source, target) pair is not associated with any parallel data, but there may exist auxiliary parallel data that contains the other. This auxiliary data can naturally be utilized in our probabilistic framework via a novel cross-translation loss term. Empirically, we show that our approach results in higher BLEU scores over state-of-the-art unsupervised models on the WMT'14 English-French, WMT'16 English-German, and WMT'16 English-Romanian datasets in most directions. In particular, we obtain a +1.65 BLEU advantage over the best-performing unsupervised model in the Romanian-English direction.
Sticking to the Facts: Confident Decoding for Faithful Data-to-Text Generation
Nov 15, 2019

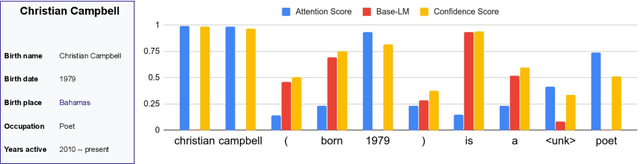
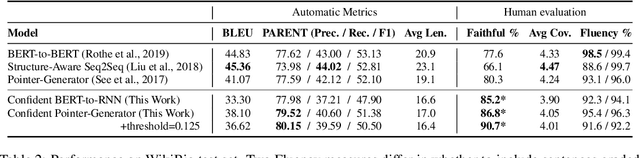
Neural conditional text generation systems have achieved significant progress in recent years, showing the ability to produce highly fluent text. However, the inherent lack of controllability in these systems allows them to hallucinate factually incorrect phrases that are unfaithful to the source, making them often unsuitable for many real world systems that require high degrees of precision. In this work, we propose a novel confidence oriented decoder that assigns a confidence score to each target position. This score is learned in training using a variational Bayes objective, and can be leveraged at inference time using a calibration technique to promote more faithful generation. Experiments on a structured data-to-text dataset -- WikiBio -- show that our approach is more faithful to the source than existing state-of-the-art approaches, according to both automatic metrics and human evaluation.