 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUserIdentifier: Implicit User Representations for Simple and Effective Personalized Sentiment Analysis
Oct 01, 2021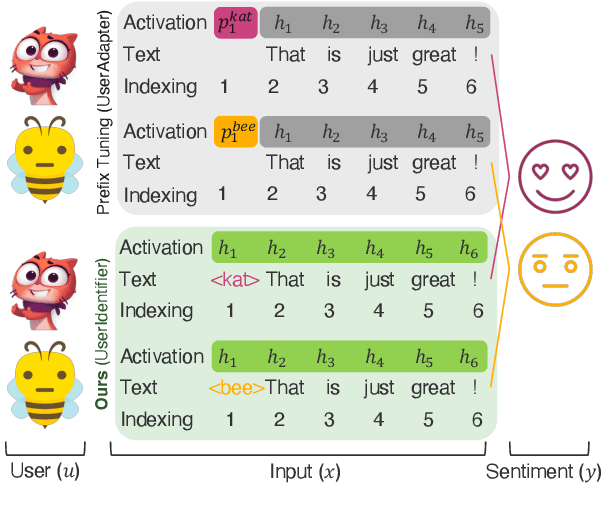
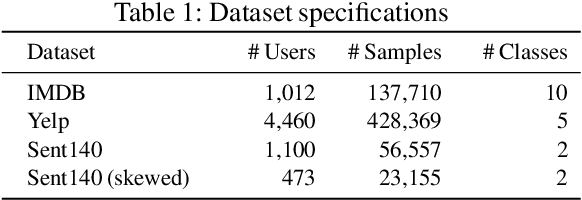
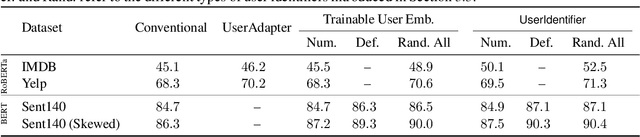
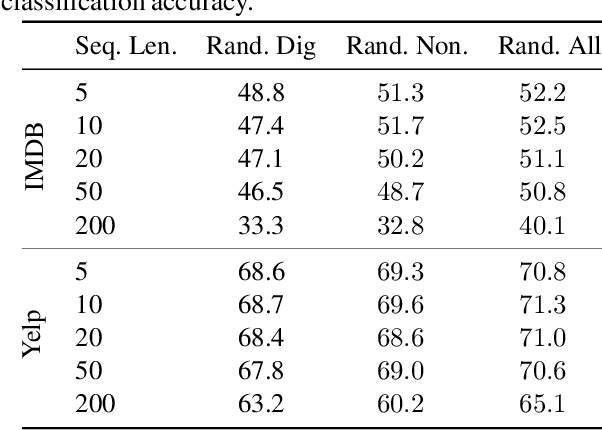
Global models are trained to be as generalizable as possible, with user invariance considered desirable since the models are shared across multitudes of users. As such, these models are often unable to produce personalized responses for individual users, based on their data. Contrary to widely-used personalization techniques based on few-shot learning, we propose UserIdentifier, a novel scheme for training a single shared model for all users. Our approach produces personalized responses by adding fixed, non-trainable user identifiers to the input data. We empirically demonstrate that this proposed method outperforms the prefix-tuning based state-of-the-art approach by up to 13%, on a suite of sentiment analysis datasets. We also show that, unlike prior work, this method needs neither any additional model parameters nor any extra rounds of few-shot fine-tuning.
Scalable Font Reconstruction with Dual Latent Manifolds
Sep 10, 2021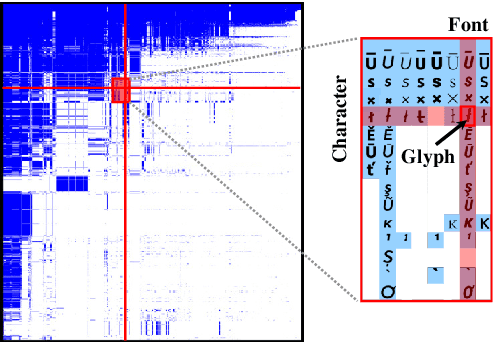
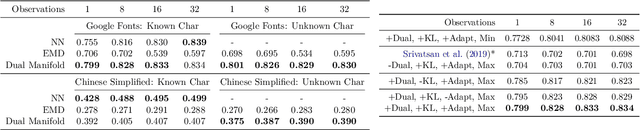
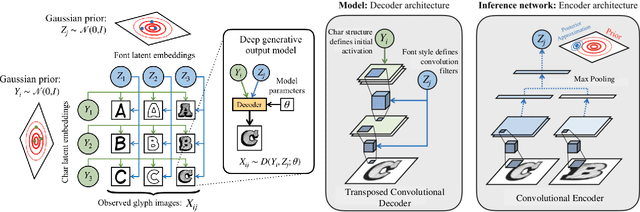
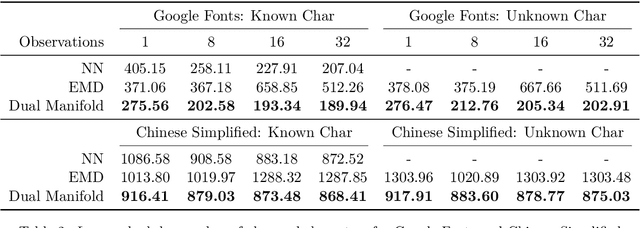
We propose a deep generative model that performs typography analysis and font reconstruction by learning disentangled manifolds of both font style and character shape. Our approach enables us to massively scale up the number of character types we can effectively model compared to previous methods. Specifically, we infer separate latent variables representing character and font via a pair of inference networks which take as input sets of glyphs that either all share a character type, or belong to the same font. This design allows our model to generalize to characters that were not observed during training time, an important task in light of the relative sparsity of most fonts. We also put forward a new loss, adapted from prior work that measures likelihood using an adaptive distribution in a projected space, resulting in more natural images without requiring a discriminator. We evaluate on the task of font reconstruction over various datasets representing character types of many languages, and compare favorably to modern style transfer systems according to both automatic and manually-evaluated metrics.
Style Pooling: Automatic Text Style Obfuscation for Improved Classification Fairness
Sep 10, 2021
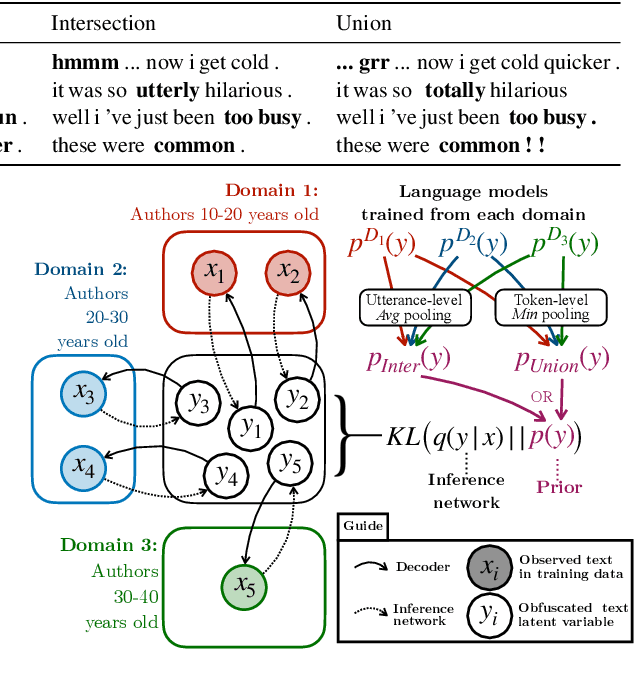
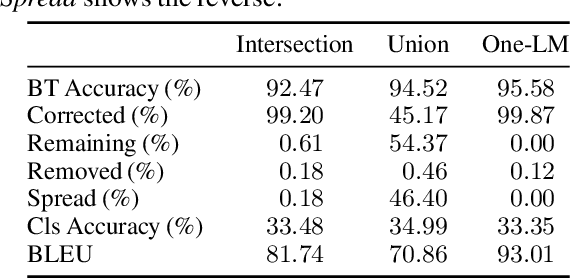
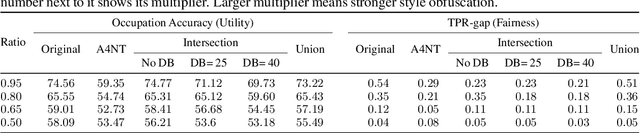
Text style can reveal sensitive attributes of the author (e.g. race or age) to the reader, which can, in turn, lead to privacy violations and bias in both human and algorithmic decisions based on text. For example, the style of writing in job applications might reveal protected attributes of the candidate which could lead to bias in hiring decisions, regardless of whether hiring decisions are made algorithmically or by humans. We propose a VAE-based framework that obfuscates stylistic features of human-generated text through style transfer by automatically re-writing the text itself. Our framework operationalizes the notion of obfuscated style in a flexible way that enables two distinct notions of obfuscated style: (1) a minimal notion that effectively intersects the various styles seen in training, and (2) a maximal notion that seeks to obfuscate by adding stylistic features of all sensitive attributes to text, in effect, computing a union of styles. Our style-obfuscation framework can be used for multiple purposes, however, we demonstrate its effectiveness in improving the fairness of downstream classifiers. We also conduct a comprehensive study on style pooling's effect on fluency, semantic consistency, and attribute removal from text, in two and three domain style obfuscation.
Efficient Nearest Neighbor Language Models
Sep 09, 2021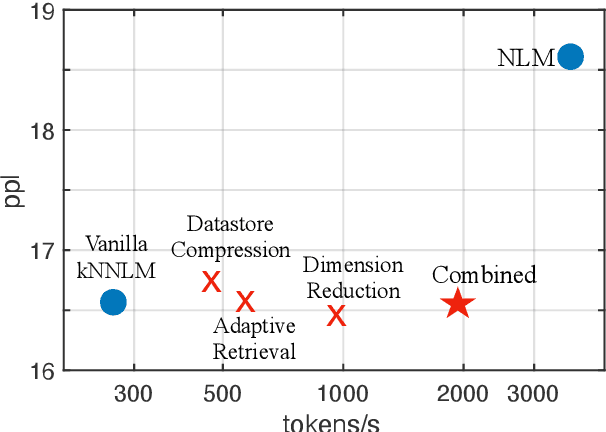
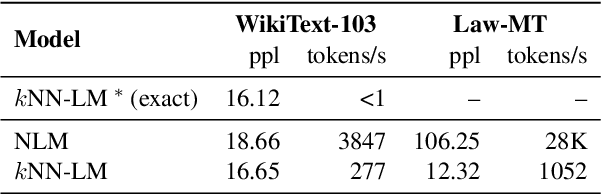
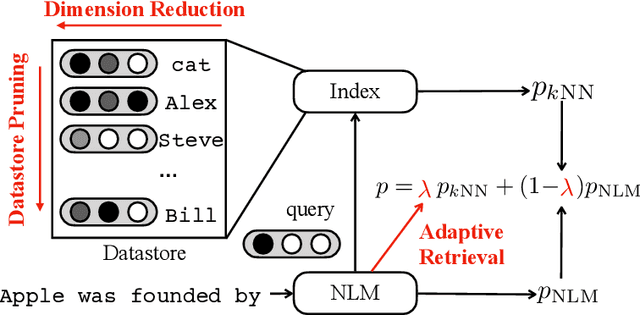

Non-parametric neural language models (NLMs) learn predictive distributions of text utilizing an external datastore, which allows them to learn through explicitly memorizing the training datapoints. While effective, these models often require retrieval from a large datastore at test time, significantly increasing the inference overhead and thus limiting the deployment of non-parametric NLMs in practical applications. In this paper, we take the recently proposed $k$-nearest neighbors language model (Khandelwal et al., 2019) as an example, exploring methods to improve its efficiency along various dimensions. Experiments on the standard WikiText-103 benchmark and domain-adaptation datasets show that our methods are able to achieve up to a 6x speed-up in inference speed while retaining comparable performance. The empirical analysis we present may provide guidelines for future research seeking to develop or deploy more efficient non-parametric NLMs.
An Empirical Evaluation of End-to-End Polyphonic Optical Music Recognition
Aug 03, 2021
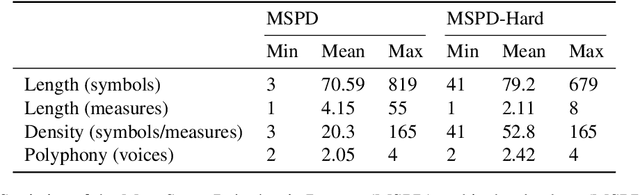
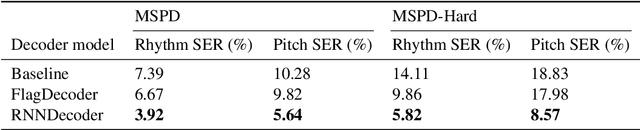
Previous work has shown that neural architectures are able to perform optical music recognition (OMR) on monophonic and homophonic music with high accuracy. However, piano and orchestral scores frequently exhibit polyphonic passages, which add a second dimension to the task. Monophonic and homophonic music can be described as homorhythmic, or having a single musical rhythm. Polyphonic music, on the other hand, can be seen as having multiple rhythmic sequences, or voices, concurrently. We first introduce a workflow for creating large-scale polyphonic datasets suitable for end-to-end recognition from sheet music publicly available on the MuseScore forum. We then propose two novel formulations for end-to-end polyphonic OMR -- one treating the problem as a type of multi-task binary classification, and the other treating it as multi-sequence detection. Building upon the encoder-decoder architecture and an image encoder proposed in past work on end-to-end OMR, we propose two novel decoder models -- FlagDecoder and RNNDecoder -- that correspond to the two formulations. Finally, we compare the empirical performance of these end-to-end approaches to polyphonic OMR and observe a new state-of-the-art performance with our multi-sequence detection decoder, RNNDecoder.
Neural Representation Learning for Scribal Hands of Linear B
Jul 14, 2021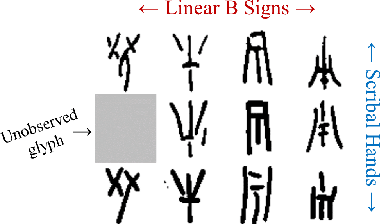
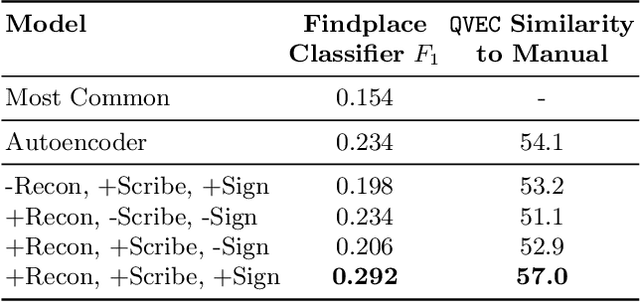
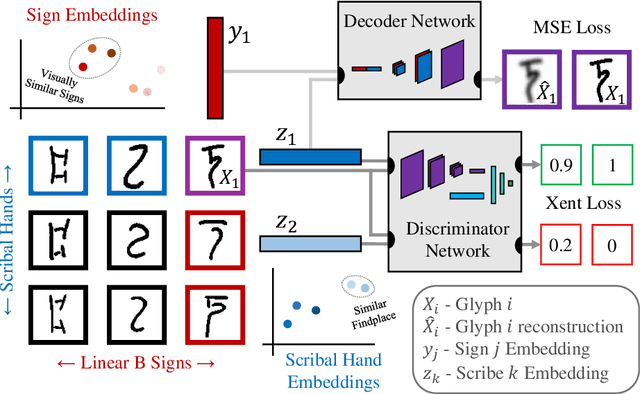
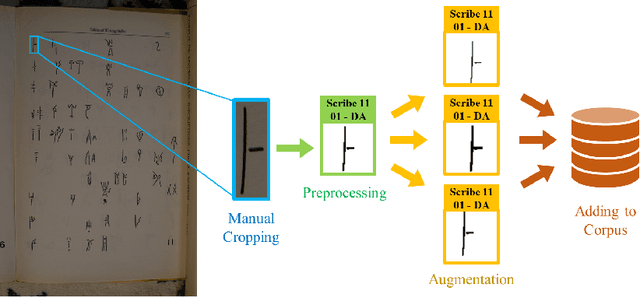
In this work, we present an investigation into the use of neural feature extraction in performing scribal hand analysis of the Linear B writing system. While prior work has demonstrated the usefulness of strategies such as phylogenetic systematics in tracing Linear B's history, these approaches have relied on manually extracted features which can be very time consuming to define by hand. Instead we propose learning features using a fully unsupervised neural network that does not require any human annotation. Specifically our model assigns each glyph written by the same scribal hand a shared vector embedding to represent that author's stylistic patterns, and each glyph representing the same syllabic sign a shared vector embedding to represent the identifying shape of that character. Thus the properties of each image in our dataset are represented as the combination of a scribe embedding and a sign embedding. We train this model using both a reconstructive loss governed by a decoder that seeks to reproduce glyphs from their corresponding embeddings, and a discriminative loss which measures the model's ability to predict whether or not an embedding corresponds to a given image. Among the key contributions of this work we (1) present a new dataset of Linear B glyphs, annotated by scribal hand and sign type, (2) propose a neural model for disentangling properties of scribal hands from glyph shape, and (3) quantitatively evaluate the learned embeddings on findplace prediction and similarity to manually extracted features, showing improvements over simpler baseline methods.
Towards Automatic Instrumentation by Learning to Separate Parts in Symbolic Multitrack Music
Jul 13, 2021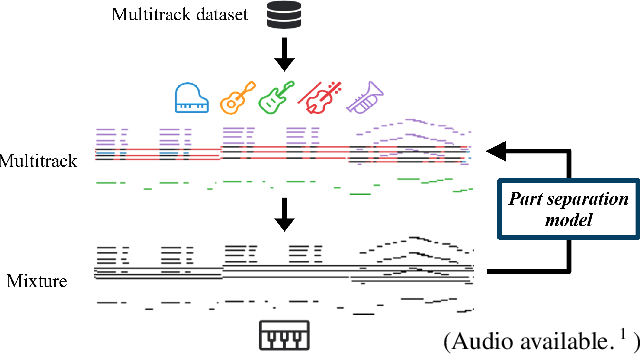


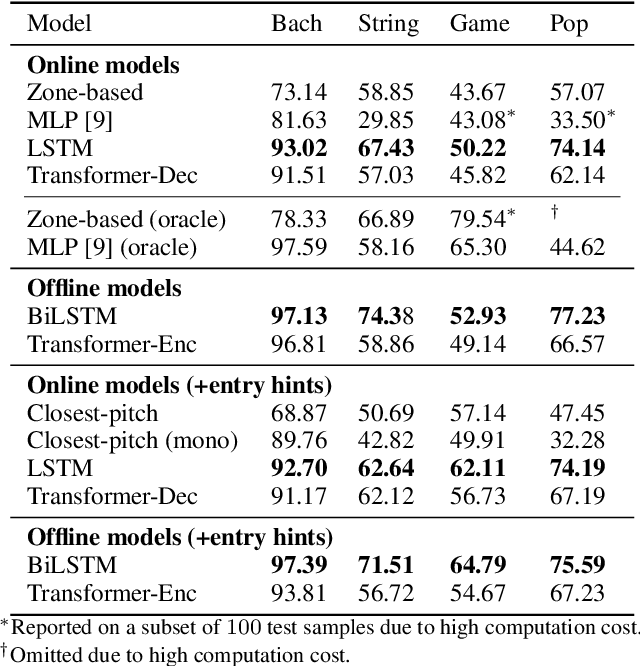
Modern keyboards allow a musician to play multiple instruments at the same time by assigning zones -- fixed pitch ranges of the keyboard -- to different instruments. In this paper, we aim to further extend this idea and examine the feasibility of automatic instrumentation -- dynamically assigning instruments to notes in solo music during performance. In addition to the online, real-time-capable setting for performative use cases, automatic instrumentation can also find applications in assistive composing tools in an offline setting. Due to the lack of paired data of original solo music and their full arrangements, we approach automatic instrumentation by learning to separate parts (e.g., voices, instruments and tracks) from their mixture in symbolic multitrack music, assuming that the mixture is to be played on a keyboard. We frame the task of part separation as a sequential multi-class classification problem and adopt machine learning to map sequences of notes into sequences of part labels. To examine the effectiveness of our proposed models, we conduct a comprehensive empirical evaluation over four diverse datasets of different genres and ensembles -- Bach chorales, string quartets, game music and pop music. Our experiments show that the proposed models outperform various baselines. We also demonstrate the potential for our proposed models to produce alternative convincing instrumentations for an existing arrangement by separating its mixture into parts. All source code and audio samples can be found at https://salu133445.github.io/arranger/ .
Comparative Error Analysis in Neural and Finite-state Models for Unsupervised Character-level Transduction
Jun 24, 2021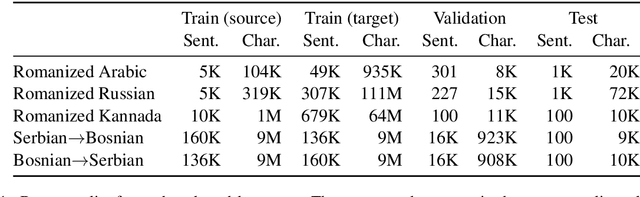

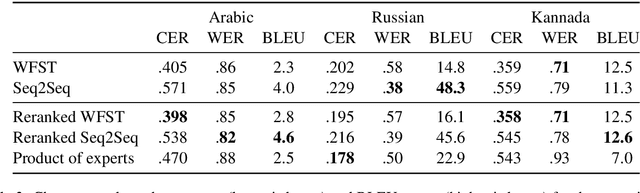

Traditionally, character-level transduction problems have been solved with finite-state models designed to encode structural and linguistic knowledge of the underlying process, whereas recent approaches rely on the power and flexibility of sequence-to-sequence models with attention. Focusing on the less explored unsupervised learning scenario, we compare the two model classes side by side and find that they tend to make different types of errors even when achieving comparable performance. We analyze the distributions of different error classes using two unsupervised tasks as testbeds: converting informally romanized text into the native script of its language (for Russian, Arabic, and Kannada) and translating between a pair of closely related languages (Serbian and Bosnian). Finally, we investigate how combining finite-state and sequence-to-sequence models at decoding time affects the output quantitatively and qualitatively.
Unsupervised Enrichment of Persona-grounded Dialog with Background Stories
Jun 15, 2021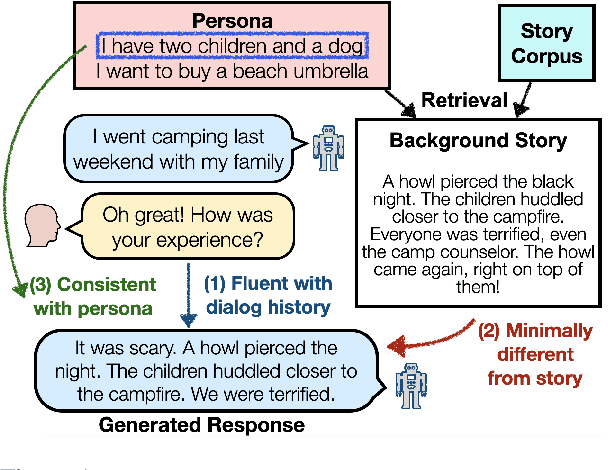
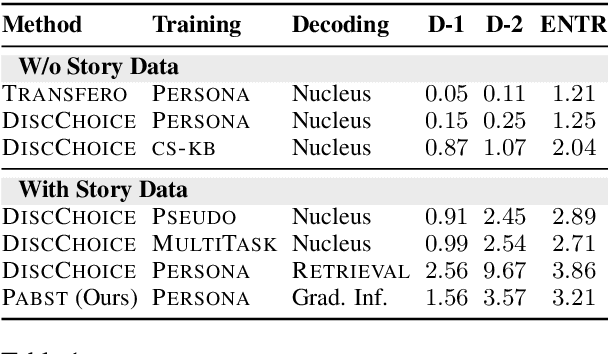

Humans often refer to personal narratives, life experiences, and events to make a conversation more engaging and rich. While persona-grounded dialog models are able to generate responses that follow a given persona, they often miss out on stating detailed experiences or events related to a persona, often leaving conversations shallow and dull. In this work, we equip dialog models with 'background stories' related to a persona by leveraging fictional narratives from existing story datasets (e.g. ROCStories). Since current dialog datasets do not contain such narratives as responses, we perform an unsupervised adaptation of a retrieved story for generating a dialog response using a gradient-based rewriting technique. Our proposed method encourages the generated response to be fluent (i.e., highly likely) with the dialog history, minimally different from the retrieved story to preserve event ordering and consistent with the original persona. We demonstrate that our method can generate responses that are more diverse, and are rated more engaging and human-like by human evaluators, compared to outputs from existing dialog models.
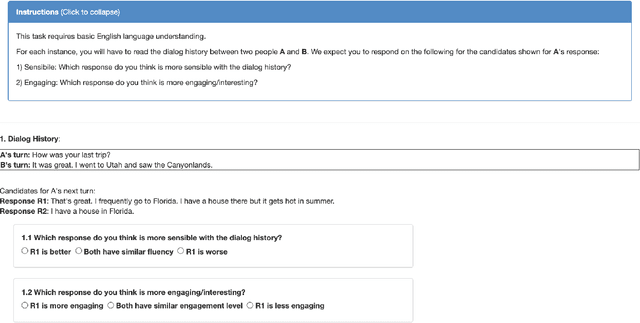
Improving Automated Evaluation of Open Domain Dialog via Diverse Reference Augmentation
Jun 05, 2021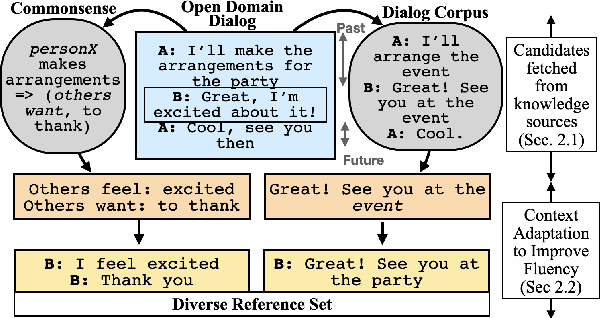



Multiple different responses are often plausible for a given open domain dialog context. Prior work has shown the importance of having multiple valid reference responses for meaningful and robust automated evaluations. In such cases, common practice has been to collect more human written references. However, such collection can be expensive, time consuming, and not easily scalable. Instead, we propose a novel technique for automatically expanding a human generated reference to a set of candidate references. We fetch plausible references from knowledge sources, and adapt them so that they are more fluent in context of the dialog instance in question. More specifically, we use (1) a commonsense knowledge base to elicit a large number of plausible reactions given the dialog history (2) relevant instances retrieved from dialog corpus, using similar past as well as future contexts. We demonstrate that our automatically expanded reference sets lead to large improvements in correlations of automated metrics with human ratings of system outputs for DailyDialog dataset.