 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Conversational Goals with Unsupervised Post-hoc Knowledge Injection
Mar 22, 2022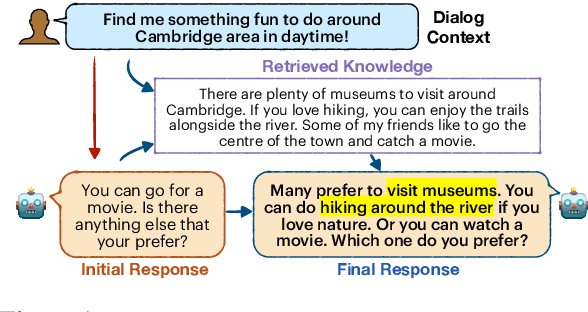
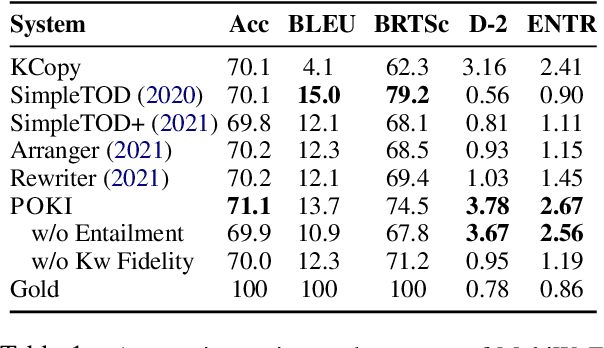
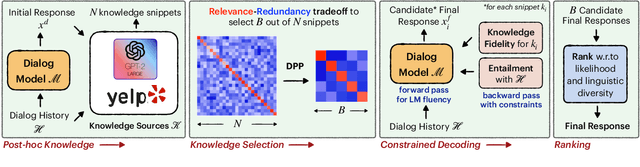
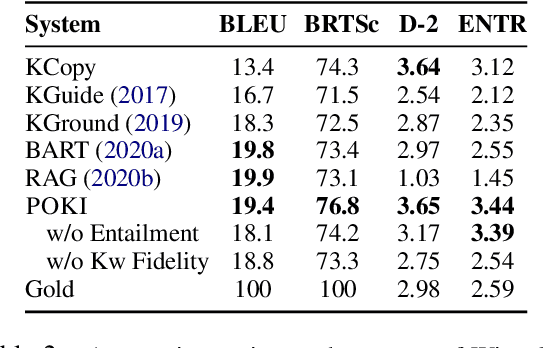
A limitation of current neural dialog models is that they tend to suffer from a lack of specificity and informativeness in generated responses, primarily due to dependence on training data that covers a limited variety of scenarios and conveys limited knowledge. One way to alleviate this issue is to extract relevant knowledge from external sources at decoding time and incorporate it into the dialog response. In this paper, we propose a post-hoc knowledge-injection technique where we first retrieve a diverse set of relevant knowledge snippets conditioned on both the dialog history and an initial response from an existing dialog model. We construct multiple candidate responses, individually injecting each retrieved snippet into the initial response using a gradient-based decoding method, and then select the final response with an unsupervised ranking step. Our experiments in goal-oriented and knowledge-grounded dialog settings demonstrate that human annotators judge the outputs from the proposed method to be more engaging and informative compared to responses from prior dialog systems. We further show that knowledge-augmentation promotes success in achieving conversational goals in both experimental settings.
Quantifying Privacy Risks of Masked Language Models Using Membership Inference Attacks
Mar 08, 2022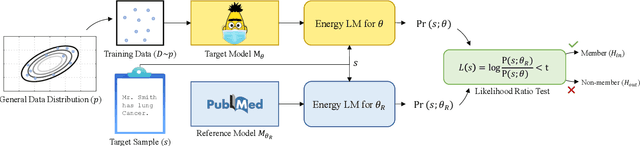


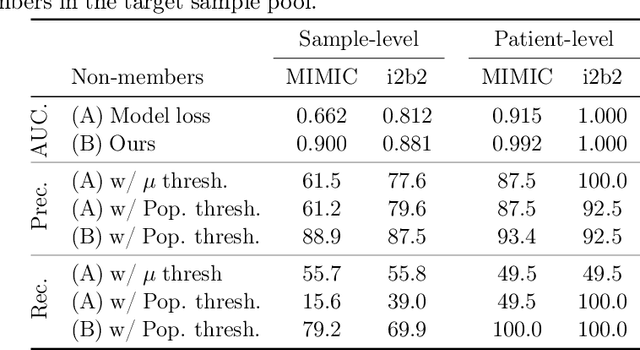
The wide adoption and application of Masked language models~(MLMs) on sensitive data (from legal to medical) necessitates a thorough quantitative investigation into their privacy vulnerabilities -- to what extent do MLMs leak information about their training data? Prior attempts at measuring leakage of MLMs via membership inference attacks have been inconclusive, implying the potential robustness of MLMs to privacy attacks. In this work, we posit that prior attempts were inconclusive because they based their attack solely on the MLM's model score. We devise a stronger membership inference attack based on likelihood ratio hypothesis testing that involves an additional reference MLM to more accurately quantify the privacy risks of memorization in MLMs. We show that masked language models are extremely susceptible to likelihood ratio membership inference attacks: Our empirical results, on models trained on medical notes, show that our attack improves the AUC of prior membership inference attacks from 0.66 to an alarmingly high 0.90 level, with a significant improvement in the low-error region: at 1% false positive rate, our attack is 51X more powerful than prior work.
Deep Performer: Score-to-Audio Music Performance Synthesis
Feb 21, 2022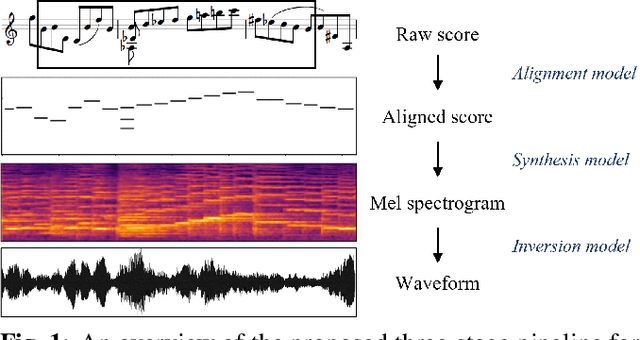

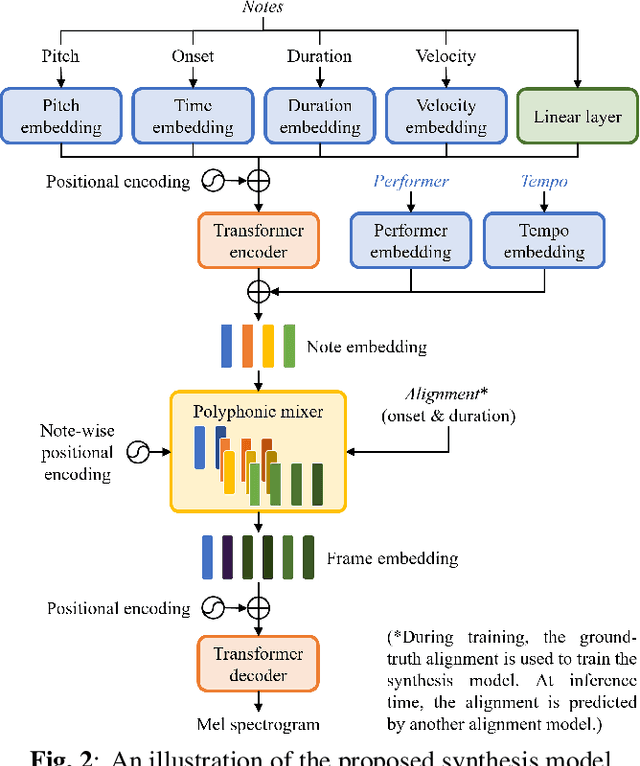

Music performance synthesis aims to synthesize a musical score into a natural performance. In this paper, we borrow recent advances in text-to-speech synthesis and present the Deep Performer -- a novel system for score-to-audio music performance synthesis. Unlike speech, music often contains polyphony and long notes. Hence, we propose two new techniques for handling polyphonic inputs and providing a fine-grained conditioning in a transformer encoder-decoder model. To train our proposed system, we present a new violin dataset consisting of paired recordings and scores along with estimated alignments between them. We show that our proposed model can synthesize music with clear polyphony and harmonic structures. In a listening test, we achieve competitive quality against the baseline model, a conditional generative audio model, in terms of pitch accuracy, timbre and noise level. Moreover, our proposed model significantly outperforms the baseline on an existing piano dataset in overall quality.
TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
Feb 02, 2022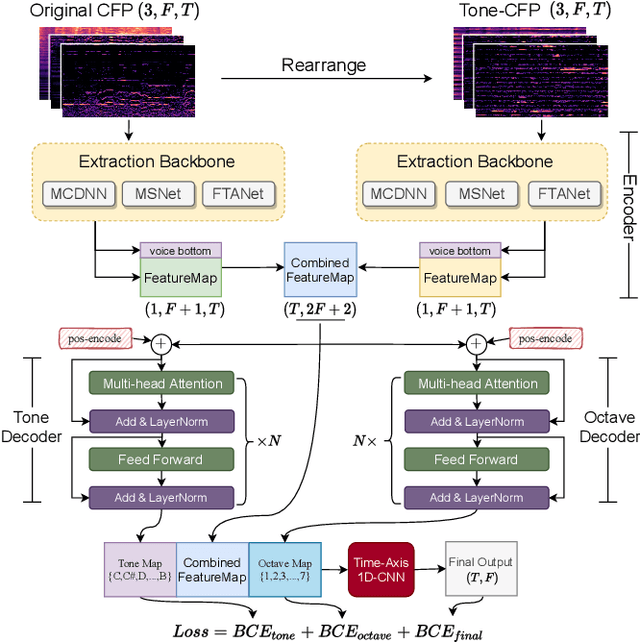
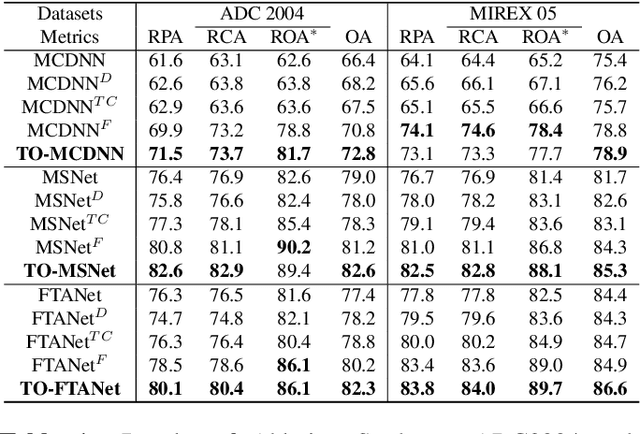
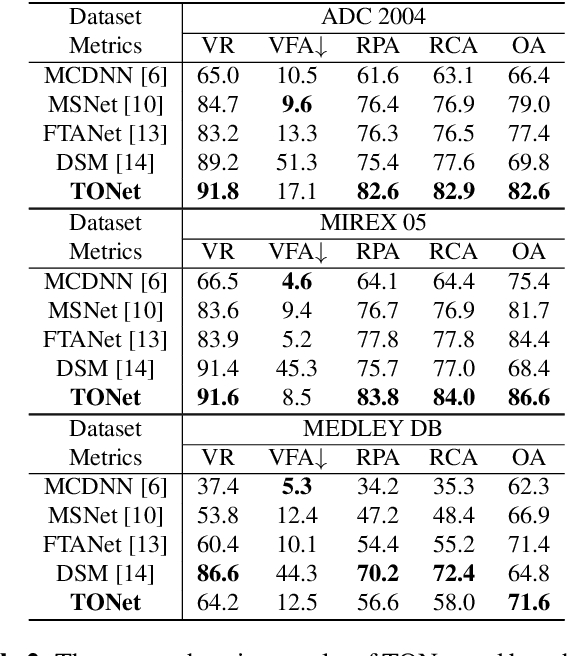
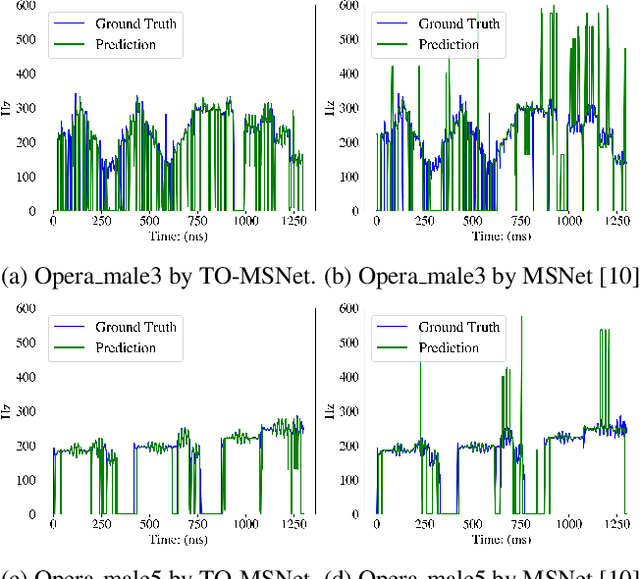
Singing melody extraction is an important problem in the field of music information retrieval. Existing methods typically rely on frequency-domain representations to estimate the sung frequencies. However, this design does not lead to human-level performance in the perception of melody information for both tone (pitch-class) and octave. In this paper, we propose TONet, a plug-and-play model that improves both tone and octave perceptions by leveraging a novel input representation and a novel network architecture. First, we present an improved input representation, the Tone-CFP, that explicitly groups harmonics via a rearrangement of frequency-bins. Second, we introduce an encoder-decoder architecture that is designed to obtain a salience feature map, a tone feature map, and an octave feature map. Third, we propose a tone-octave fusion mechanism to improve the final salience feature map. Experiments are done to verify the capability of TONet with various baseline backbone models. Our results show that tone-octave fusion with Tone-CFP can significantly improve the singing voice extraction performance across various datasets -- with substantial gains in octave and tone accuracy.
HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection
Feb 02, 2022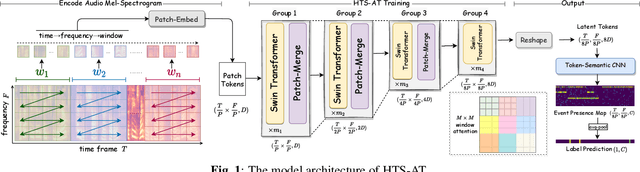
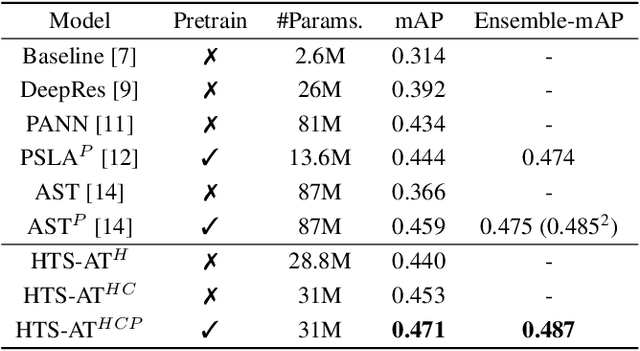
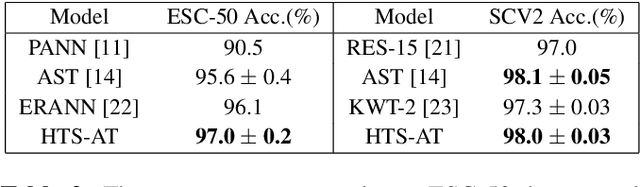

Audio classification is an important task of mapping audio samples into their corresponding labels. Recently, the transformer model with self-attention mechanisms has been adopted in this field. However, existing audio transformers require large GPU memories and long training time, meanwhile relying on pretrained vision models to achieve high performance, which limits the model's scalability in audio tasks. To combat these problems, we introduce HTS-AT: an audio transformer with a hierarchical structure to reduce the model size and training time. It is further combined with a token-semantic module to map final outputs into class featuremaps, thus enabling the model for the audio event detection (i.e. localization in time). We evaluate HTS-AT on three datasets of audio classification where it achieves new state-of-the-art (SOTA) results on AudioSet and ESC-50, and equals the SOTA on Speech Command V2. It also achieves better performance in event localization than the previous CNN-based models. Moreover, HTS-AT requires only 35% model parameters and 15% training time of the previous audio transformer. These results demonstrate the high performance and high efficiency of HTS-AT.
An Unsupervised Masking Objective for Abstractive Multi-Document News Summarization
Jan 07, 2022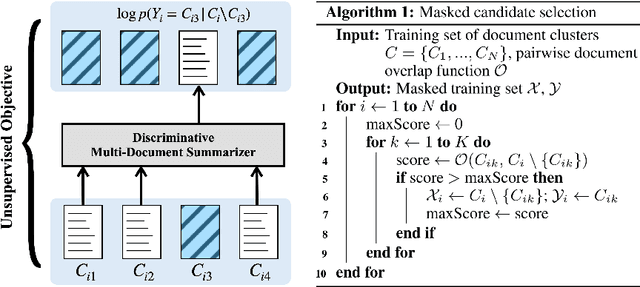
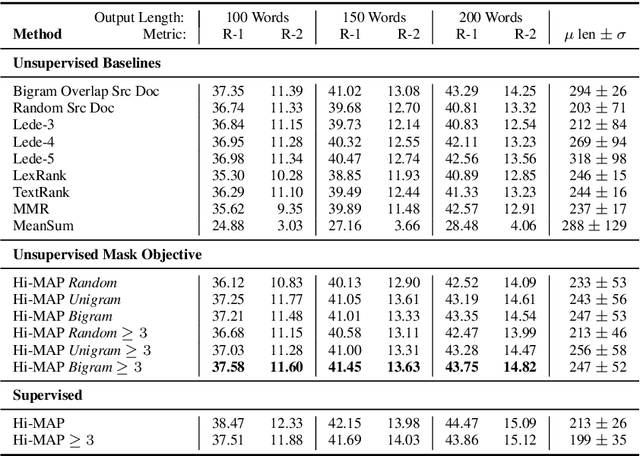
We show that a simple unsupervised masking objective can approach near supervised performance on abstractive multi-document news summarization. Our method trains a state-of-the-art neural summarization model to predict the masked out source document with highest lexical centrality relative to the multi-document group. In experiments on the Multi-News dataset, our masked training objective yields a system that outperforms past unsupervised methods and, in human evaluation, surpasses the best supervised method without requiring access to any ground-truth summaries. Further, we evaluate how different measures of lexical centrality, inspired by past work on extractive summarization, affect final performance.
Lacuna Reconstruction: Self-supervised Pre-training for Low-Resource Historical Document Transcription
Dec 16, 2021
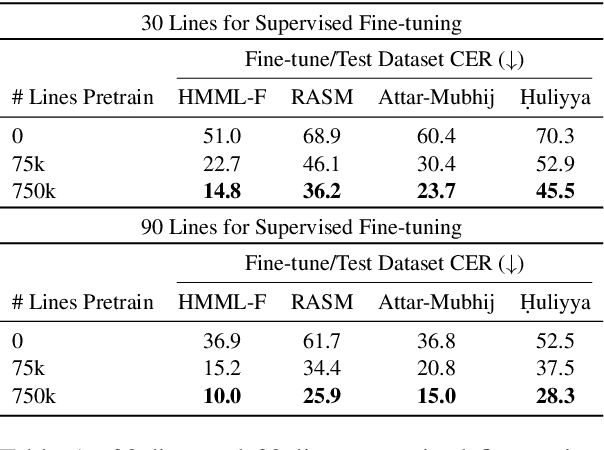
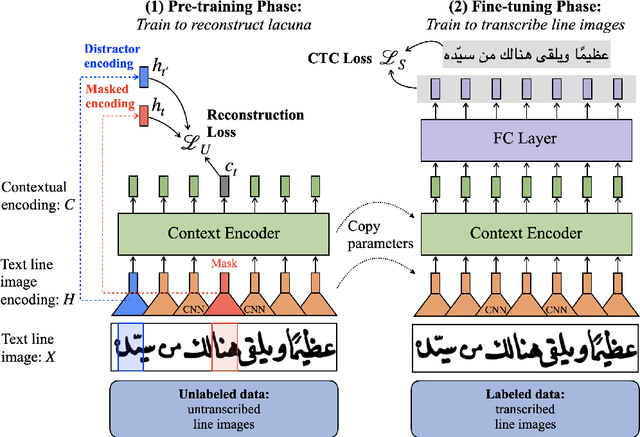

We present a self-supervised pre-training approach for learning rich visual language representations for both handwritten and printed historical document transcription. After supervised fine-tuning of our pre-trained encoder representations for low-resource document transcription on two languages, (1) a heterogeneous set of handwritten Islamicate manuscript images and (2) early modern English printed documents, we show a meaningful improvement in recognition accuracy over the same supervised model trained from scratch with as few as 30 line image transcriptions for training. Our masked language model-style pre-training strategy, where the model is trained to be able to identify the true masked visual representation from distractors sampled from within the same line, encourages learning robust contextualized language representations invariant to scribal writing style and printing noise present across documents.
Masked Measurement Prediction: Learning to Jointly Predict Quantities and Units from Textual Context
Dec 16, 2021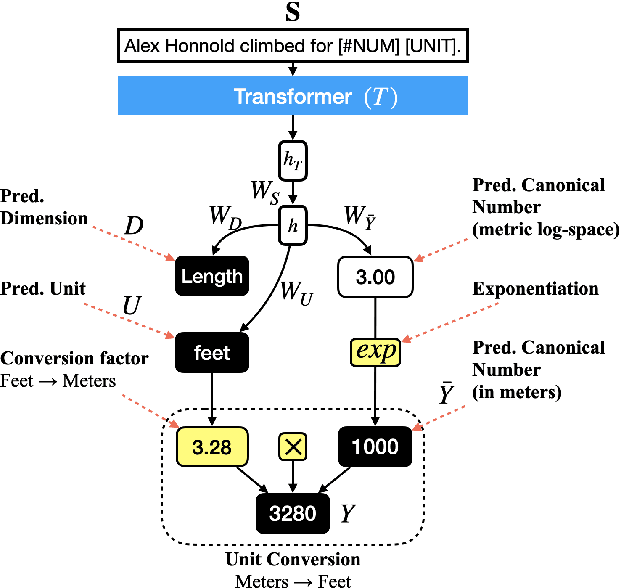
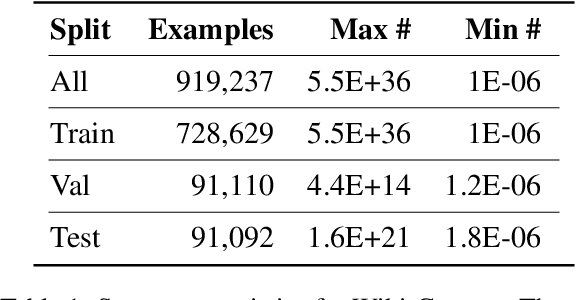
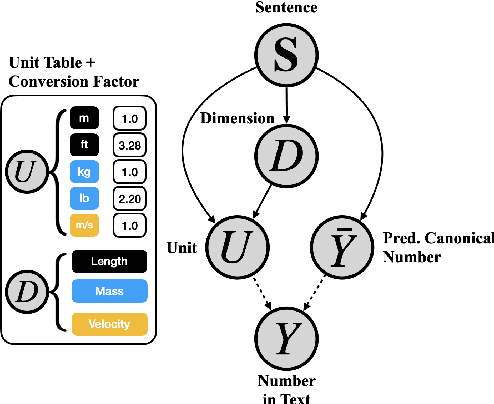
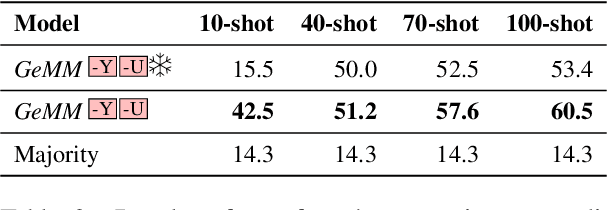
Physical measurements constitute a large portion of numbers in academic papers, engineering reports, and web tables. Current benchmarks fall short of properly evaluating numeracy of pretrained language models on measurements, hindering research on developing new methods and applying them to numerical tasks. To that end, we introduce a novel task, Masked Measurement Prediction (MMP), where a model learns to reconstruct a number together with its associated unit given masked text. MMP is useful for both training new numerically informed models as well as evaluating numeracy of existing systems. In order to address this task, we introduce a new Generative Masked Measurement (GeMM) model that jointly learns to predict numbers along with their units. We perform fine-grained analyses comparing our model with various ablations and baselines. We use linear probing of traditional pretrained transformer models (RoBERTa) to show that they significantly underperform jointly trained number-unit models, highlighting the difficulty of this new task and the benefits of our proposed pretraining approach. We hope this framework accelerates the progress towards building more robust numerical reasoning systems in the future.
Towards a Unified View of Parameter-Efficient Transfer Learning
Oct 08, 2021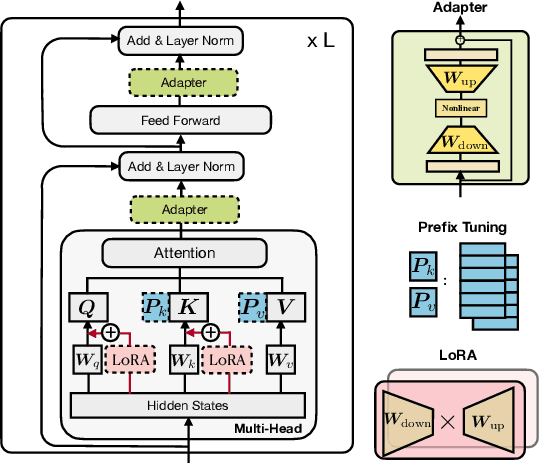
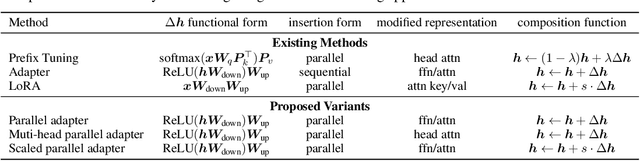
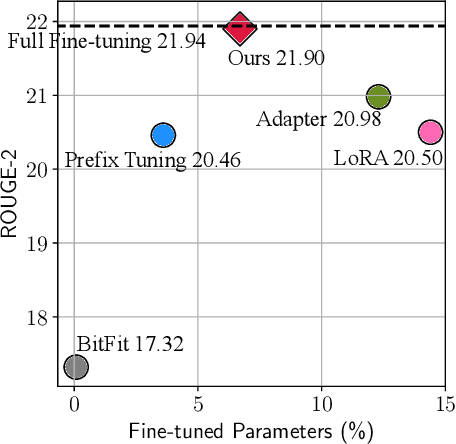
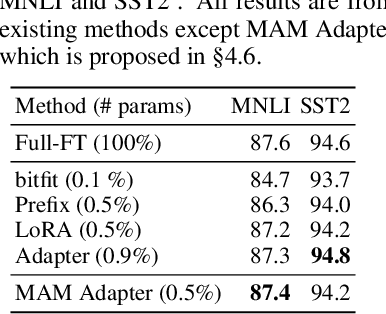
Fine-tuning large pre-trained language models on downstream tasks has become the de-facto learning paradigm in NLP. However, conventional approaches fine-tune all the parameters of the pre-trained model, which becomes prohibitive as the model size and the number of tasks grow. Recent work has proposed a variety of parameter-efficient transfer learning methods that only fine-tune a small number of (extra) parameters to attain strong performance. While effective, the critical ingredients for success and the connections among the various methods are poorly understood. In this paper, we break down the design of state-of-the-art parameter-efficient transfer learning methods and present a unified framework that establishes connections between them. Specifically, we re-frame them as modifications to specific hidden states in pre-trained models, and define a set of design dimensions along which different methods vary, such as the function to compute the modification and the position to apply the modification. Through comprehensive empirical studies across machine translation, text summarization, language understanding, and text classification benchmarks, we utilize the unified view to identify important design choices in previous methods. Furthermore, our unified framework enables the transfer of design elements across different approaches, and as a result we are able to instantiate new parameter-efficient fine-tuning methods that tune less parameters than previous methods while being more effective, achieving comparable results to fine-tuning all parameters on all four tasks.
Truth-Conditional Captioning of Time Series Data
Oct 05, 2021
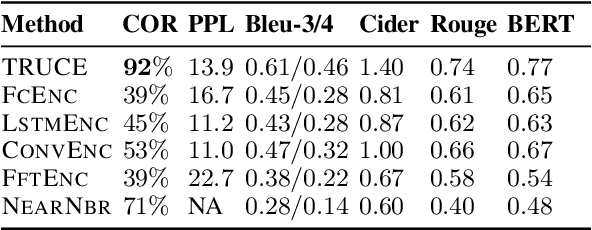
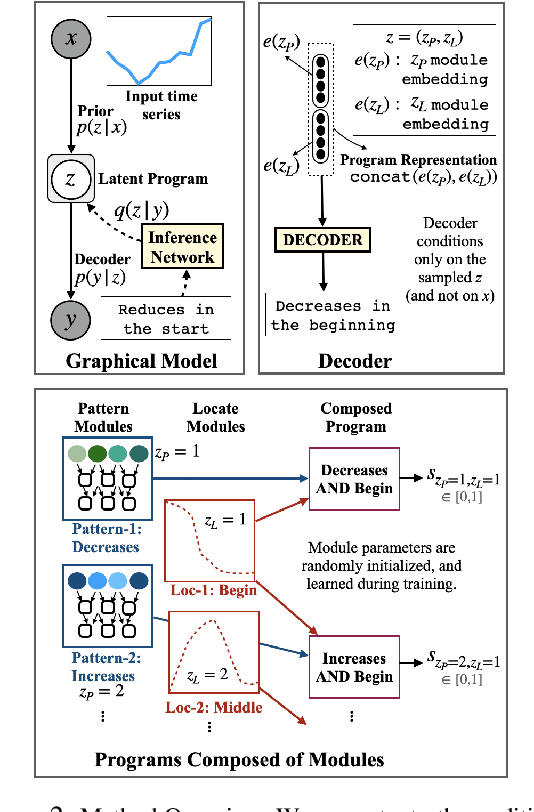
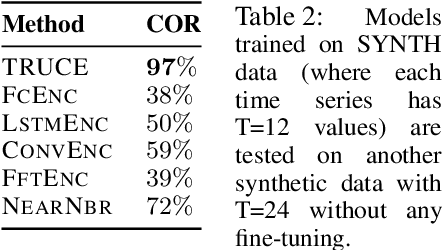
In this paper, we explore the task of automatically generating natural language descriptions of salient patterns in a time series, such as stock prices of a company over a week. A model for this task should be able to extract high-level patterns such as presence of a peak or a dip. While typical contemporary neural models with attention mechanisms can generate fluent output descriptions for this task, they often generate factually incorrect descriptions. We propose a computational model with a truth-conditional architecture which first runs small learned programs on the input time series, then identifies the programs/patterns which hold true for the given input, and finally conditions on only the chosen valid program (rather than the input time series) to generate the output text description. A program in our model is constructed from modules, which are small neural networks that are designed to capture numerical patterns and temporal information. The modules are shared across multiple programs, enabling compositionality as well as efficient learning of module parameters. The modules, as well as the composition of the modules, are unobserved in data, and we learn them in an end-to-end fashion with the only training signal coming from the accompanying natural language text descriptions. We find that the proposed model is able to generate high-precision captions even though we consider a small and simple space of module types.