 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSayTap: Language to Quadrupedal Locomotion
Jun 14, 2023Large language models (LLMs) have demonstrated the potential to perform high-level planning. Yet, it remains a challenge for LLMs to comprehend low-level commands, such as joint angle targets or motor torques. This paper proposes an approach to use foot contact patterns as an interface that bridges human commands in natural language and a locomotion controller that outputs these low-level commands. This results in an interactive system for quadrupedal robots that allows the users to craft diverse locomotion behaviors flexibly. We contribute an LLM prompt design, a reward function, and a method to expose the controller to the feasible distribution of contact patterns. The results are a controller capable of achieving diverse locomotion patterns that can be transferred to real robot hardware. Compared with other design choices, the proposed approach enjoys more than 50% success rate in predicting the correct contact patterns and can solve 10 more tasks out of a total of 30 tasks. Our project site is: https://saytap.github.io.
HiPerformer: Hierarchically Permutation-Equivariant Transformer for Time Series Forecasting
May 14, 2023



It is imperative to discern the relationships between multiple time series for accurate forecasting. In particular, for stock prices, components are often divided into groups with the same characteristics, and a model that extracts relationships consistent with this group structure should be effective. Thus, we propose the concept of hierarchical permutation-equivariance, focusing on index swapping of components within and among groups, to design a model that considers this group structure. When the prediction model has hierarchical permutation-equivariance, the prediction is consistent with the group relationships of the components. Therefore, we propose a hierarchically permutation-equivariant model that considers both the relationship among components in the same group and the relationship among groups. The experiments conducted on real-world data demonstrate that the proposed method outperforms existing state-of-the-art methods.
Domain Adaptive Multiple Instance Learning for Instance-level Prediction of Pathological Images
Apr 07, 2023



Pathological image analysis is an important process for detecting abnormalities such as cancer from cell images. However, since the image size is generally very large, the cost of providing detailed annotations is high, which makes it difficult to apply machine learning techniques. One way to improve the performance of identifying abnormalities while keeping the annotation cost low is to use only labels for each slide, or to use information from another dataset that has already been labeled. However, such weak supervisory information often does not provide sufficient performance. In this paper, we proposed a new task setting to improve the classification performance of the target dataset without increasing annotation costs. And to solve this problem, we propose a pipeline that uses multiple instance learning (MIL) and domain adaptation (DA) methods. Furthermore, in order to combine the supervisory information of both methods effectively, we propose a method to create pseudo-labels with high confidence. We conducted experiments on the pathological image dataset we created for this study and showed that the proposed method significantly improves the classification performance compared to existing methods.
Aleth-NeRF: Low-light Condition View Synthesis with Concealing Fields
Mar 10, 2023



Common capture low-light scenes are challenging for most computer vision techniques, including Neural Radiance Fields (NeRF). Vanilla NeRF is viewer-centred that simplifies the rendering process only as light emission from 3D locations in the viewing direction, thus failing to model the low-illumination induced darkness. Inspired by emission theory of ancient Greek that visual perception is accomplished by rays casting from eyes, we make slight modifications on vanilla NeRF to train on multiple views of low-light scene, we can thus render out the well-lit scene in an unsupervised manner. We introduce a surrogate concept, Concealing Fields, that reduce the transport of light during the volume rendering stage. Specifically, our proposed method, Aleth-NeRF, directly learns from the dark image to understand volumetric object representation and concealing field under priors. By simply eliminating Concealing Fields, we can render a single or multi-view well-lit image(s) and gain superior performance over other 2D low light enhancement methods. Additionally, we collect the first paired LOw-light and normal-light Multi-view (LOM) datasets for future research.
Self-Supervised Learning for Group Equivariant Neural Networks
Mar 08, 2023



This paper proposes a method to construct pretext tasks for self-supervised learning on group equivariant neural networks. Group equivariant neural networks are the models whose structure is restricted to commute with the transformations on the input. Therefore, it is important to construct pretext tasks for self-supervised learning that do not contradict this equivariance. To ensure that training is consistent with the equivariance, we propose two concepts for self-supervised tasks: equivariant pretext labels and invariant contrastive loss. Equivariant pretext labels use a set of labels on which we can define the transformations that correspond to the input change. Invariant contrastive loss uses a modified contrastive loss that absorbs the effect of transformations on each input. Experiments on standard image recognition benchmarks demonstrate that the equivariant neural networks exploit the proposed equivariant self-supervised tasks.
Sketch-based Medical Image Retrieval
Mar 07, 2023



The amount of medical images stored in hospitals is increasing faster than ever; however, utilizing the accumulated medical images has been limited. This is because existing content-based medical image retrieval (CBMIR) systems usually require example images to construct query vectors; nevertheless, example images cannot always be prepared. Besides, there can be images with rare characteristics that make it difficult to find similar example images, which we call isolated samples. Here, we introduce a novel sketch-based medical image retrieval (SBMIR) system that enables users to find images of interest without example images. The key idea lies in feature decomposition of medical images, whereby the entire feature of a medical image can be decomposed into and reconstructed from normal and abnormal features. By extending this idea, our SBMIR system provides an easy-to-use two-step graphical user interface: users first select a template image to specify a normal feature and then draw a semantic sketch of the disease on the template image to represent an abnormal feature. Subsequently, it integrates the two kinds of input to construct a query vector and retrieves reference images with the closest reference vectors. Using two datasets, ten healthcare professionals with various clinical backgrounds participated in the user test for evaluation. As a result, our SBMIR system enabled users to overcome previous challenges, including image retrieval based on fine-grained image characteristics, image retrieval without example images, and image retrieval for isolated samples. Our SBMIR system achieves flexible medical image retrieval on demand, thereby expanding the utility of medical image databases.
Interpretable Medical Image Visual Question Answering via Multi-Modal Relationship Graph Learning
Feb 19, 2023



Medical visual question answering (VQA) aims to answer clinically relevant questions regarding input medical images. This technique has the potential to improve the efficiency of medical professionals while relieving the burden on the public health system, particularly in resource-poor countries. Existing medical VQA methods tend to encode medical images and learn the correspondence between visual features and questions without exploiting the spatial, semantic, or medical knowledge behind them. This is partially because of the small size of the current medical VQA dataset, which often includes simple questions. Therefore, we first collected a comprehensive and large-scale medical VQA dataset, focusing on chest X-ray images. The questions involved detailed relationships, such as disease names, locations, levels, and types in our dataset. Based on this dataset, we also propose a novel baseline method by constructing three different relationship graphs: spatial relationship, semantic relationship, and implicit relationship graphs on the image regions, questions, and semantic labels. The answer and graph reasoning paths are learned for different questions.
Name Your Colour For the Task: Artificially Discover Colour Naming via Colour Quantisation Transformer
Dec 07, 2022



The long-standing theory that a colour-naming system evolves under the dual pressure of efficient communication and perceptual mechanism is supported by more and more linguistic studies including the analysis of four decades' diachronic data from the Nafaanra language. This inspires us to explore whether artificial intelligence could evolve and discover a similar colour-naming system via optimising the communication efficiency represented by high-level recognition performance. Here, we propose a novel colour quantisation transformer, CQFormer, that quantises colour space while maintaining the accuracy of machine recognition on the quantised images. Given an RGB image, Annotation Branch maps it into an index map before generating the quantised image with a colour palette, meanwhile the Palette Branch utilises a key-point detection way to find proper colours in palette among whole colour space. By interacting with colour annotation, CQFormer is able to balance both the machine vision accuracy and colour perceptual structure such as distinct and stable colour distribution for discovered colour system. Very interestingly, we even observe the consistent evolution pattern between our artificial colour system and basic colour terms across human languages. Besides, our colour quantisation method also offers an efficient quantisation method that effectively compresses the image storage while maintaining a high performance in high-level recognition tasks such as classification and detection. Extensive experiments demonstrate the superior performance of our method with extremely low bit-rate colours. We will release the source code soon.
Learning by Asking Questions for Knowledge-based Novel Object Recognition
Oct 12, 2022
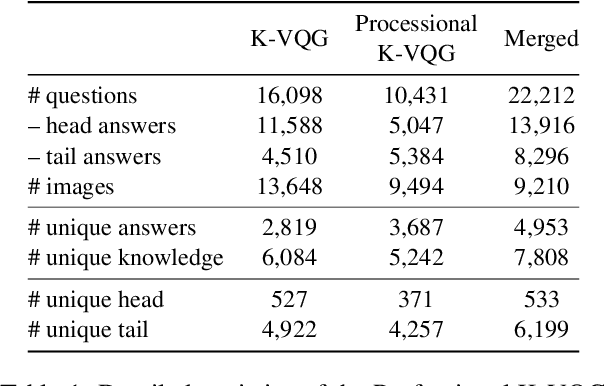
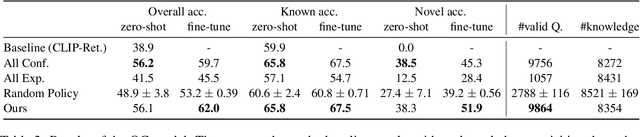
In real-world object recognition, there are numerous object classes to be recognized. Conventional image recognition based on supervised learning can only recognize object classes that exist in the training data, and thus has limited applicability in the real world. On the other hand, humans can recognize novel objects by asking questions and acquiring knowledge about them. Inspired by this, we study a framework for acquiring external knowledge through question generation that would help the model instantly recognize novel objects. Our pipeline consists of two components: the Object Classifier, which performs knowledge-based object recognition, and the Question Generator, which generates knowledge-aware questions to acquire novel knowledge. We also propose a question generation strategy based on the confidence of the knowledge-aware prediction of the Object Classifier. To train the Question Generator, we construct a dataset that contains knowledge-aware questions about objects in the images. Our experiments show that the proposed pipeline effectively acquires knowledge about novel objects compared to several baselines.
Grouped self-attention mechanism for a memory-efficient Transformer
Oct 06, 2022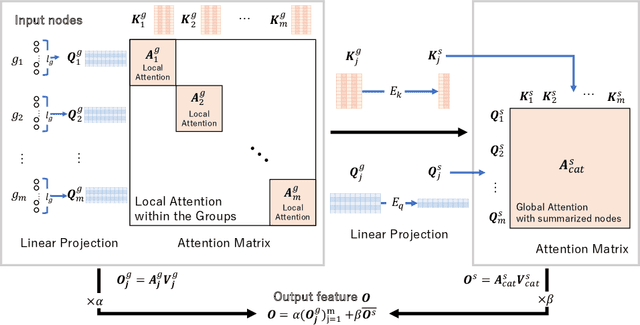
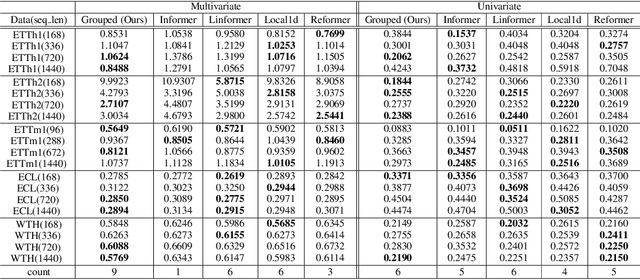
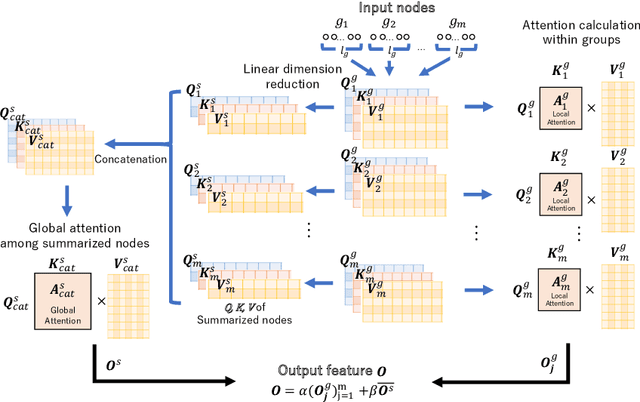
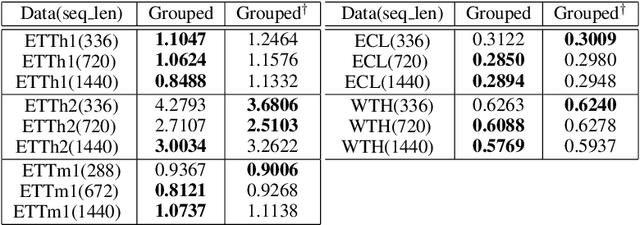
Time-series data analysis is important because numerous real-world tasks such as forecasting weather, electricity consumption, and stock market involve predicting data that vary over time. Time-series data are generally recorded over a long period of observation with long sequences owing to their periodic characteristics and long-range dependencies over time. Thus, capturing long-range dependency is an important factor in time-series data forecasting. To solve these problems, we proposed two novel modules, Grouped Self-Attention (GSA) and Compressed Cross-Attention (CCA). With both modules, we achieved a computational space and time complexity of order $O(l)$ with a sequence length $l$ under small hyperparameter limitations, and can capture locality while considering global information. The results of experiments conducted on time-series datasets show that our proposed model efficiently exhibited reduced computational complexity and performance comparable to or better than existing methods.