 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARTalk: Speech-Driven 3D Head Animation via Autoregressive Model
Feb 28, 2025



Speech-driven 3D facial animation aims to generate realistic lip movements and facial expressions for 3D head models from arbitrary audio clips. Although existing diffusion-based methods are capable of producing natural motions, their slow generation speed limits their application potential. In this paper, we introduce a novel autoregressive model that achieves real-time generation of highly synchronized lip movements and realistic head poses and eye blinks by learning a mapping from speech to a multi-scale motion codebook. Furthermore, our model can adapt to unseen speaking styles using sample motion sequences, enabling the creation of 3D talking avatars with unique personal styles beyond the identities seen during training. Extensive evaluations and user studies demonstrate that our method outperforms existing approaches in lip synchronization accuracy and perceived quality.
HyperVQ: MLR-based Vector Quantization in Hyperbolic Space
Mar 18, 2024



The success of models operating on tokenized data has led to an increased demand for effective tokenization methods, particularly when applied to vision or auditory tasks, which inherently involve non-discrete data. One of the most popular tokenization methods is Vector Quantization (VQ), a key component of several recent state-of-the-art methods across various domains. Typically, a VQ Variational Autoencoder (VQVAE) is trained to transform data to and from its tokenized representation. However, since the VQVAE is trained with a reconstruction objective, there is no constraint for the embeddings to be well disentangled, a crucial aspect for using them in discriminative tasks. Recently, several works have demonstrated the benefits of utilizing hyperbolic spaces for representation learning. Hyperbolic spaces induce compact latent representations due to their exponential volume growth and inherent ability to model hierarchical and structured data. In this work, we explore the use of hyperbolic spaces for vector quantization (HyperVQ), formulating the VQ operation as a hyperbolic Multinomial Logistic Regression (MLR) problem, in contrast to the Euclidean K-Means clustering used in VQVAE. Through extensive experiments, we demonstrate that hyperVQ performs comparably in reconstruction and generative tasks while outperforming VQ in discriminative tasks and learning a highly disentangled latent space.
Advancing Large Multi-modal Models with Explicit Chain-of-Reasoning and Visual Question Generation
Jan 18, 2024



The increasing demand for intelligent systems capable of interpreting and reasoning about visual content requires the development of Large Multi-Modal Models (LMMs) that are not only accurate but also have explicit reasoning capabilities. This paper presents a novel approach to imbue an LMM with the ability to conduct explicit reasoning based on visual content and textual instructions. We introduce a system that can ask a question to acquire necessary knowledge, thereby enhancing the robustness and explicability of the reasoning process. Our method comprises the development of a novel dataset generated by a Large Language Model (LLM), designed to promote chain-of-thought reasoning combined with a question-asking mechanism. We designed an LMM, which has high capabilities on region awareness to address the intricate requirements of image-text alignment. The model undergoes a three-stage training phase, starting with large-scale image-text alignment using a large-scale datasets, followed by instruction tuning, and fine-tuning with a focus on chain-of-thought reasoning. The results demonstrate a stride toward a more robust, accurate, and interpretable LMM, capable of reasoning explicitly and seeking information proactively when confronted with ambiguous visual input.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
Aug 14, 2023



This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding1. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system under the standard MSS formulation achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers/musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.
SATTS: Speaker Attractor Text to Speech, Learning to Speak by Learning to Separate
Jul 13, 2022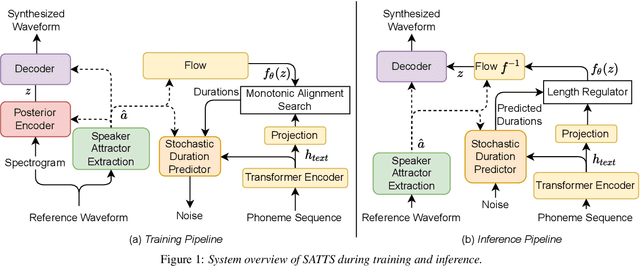
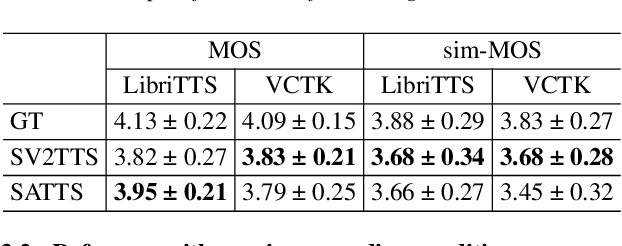

The mapping of text to speech (TTS) is non-deterministic, letters may be pronounced differently based on context, or phonemes can vary depending on various physiological and stylistic factors like gender, age, accent, emotions, etc. Neural speaker embeddings, trained to identify or verify speakers are typically used to represent and transfer such characteristics from reference speech to synthesized speech. Speech separation on the other hand is the challenging task of separating individual speakers from an overlapping mixed signal of various speakers. Speaker attractors are high-dimensional embedding vectors that pull the time-frequency bins of each speaker's speech towards themselves while repelling those belonging to other speakers. In this work, we explore the possibility of using these powerful speaker attractors for zero-shot speaker adaptation in multi-speaker TTS synthesis and propose speaker attractor text to speech (SATTS). Through various experiments, we show that SATTS can synthesize natural speech from text from an unseen target speaker's reference signal which might have less than ideal recording conditions, i.e. reverberations or mixed with other speakers.