 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Speaking or More Speakers?
Nov 02, 2022



Self-training (ST) and self-supervised learning (SSL) methods have demonstrated strong improvements in automatic speech recognition (ASR). In spite of these advances, to the best of our knowledge, there is no analysis of how the composition of the labelled and unlabelled datasets used in these methods affects the results. In this work we aim to analyse the effect of numbers of speakers in the training data on a recent SSL algorithm (wav2vec 2.0), and a recent ST algorithm (slimIPL). We perform a systematic analysis on both labeled and unlabeled data by varying the number of speakers while keeping the number of hours fixed and vice versa. Our findings suggest that SSL requires a large amount of unlabeled data to produce high accuracy results, while ST requires a sufficient number of speakers in the labelled data, especially in the low-regime setting. In this manner these two approaches improve supervised learning in different regimes of dataset composition.
Continuous Pseudo-Labeling from the Start
Oct 17, 2022
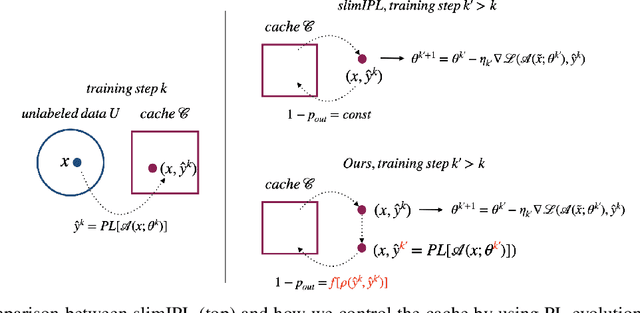
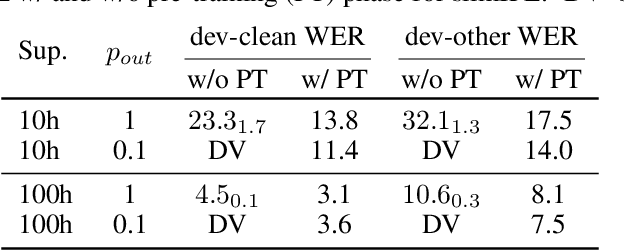
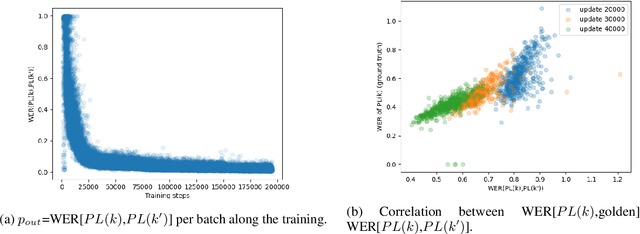
Self-training (ST), or pseudo-labeling has sparked significant interest in the automatic speech recognition (ASR) community recently because of its success in harnessing unlabeled data. Unlike prior semi-supervised learning approaches that relied on iteratively regenerating pseudo-labels (PLs) from a trained model and using them to train a new model, recent state-of-the-art methods perform `continuous training' where PLs are generated using a very recent version of the model being trained. Nevertheless, these approaches still rely on bootstrapping the ST using an initial supervised learning phase where the model is trained on labeled data alone. We believe this has the potential for over-fitting to the labeled dataset in low resource settings and that ST from the start of training should reduce over-fitting. In this paper we show how we can do this by dynamically controlling the evolution of PLs during the training process in ASR. To the best of our knowledge, this is the first study that shows the feasibility of generating PLs from the very start of the training. We are able to achieve this using two techniques that avoid instabilities which lead to degenerate models that do not generalize. Firstly, we control the evolution of PLs through a curriculum that uses the online changes in PLs to control the membership of the cache of PLs and improve generalization. Secondly, we find that by sampling transcriptions from the predictive distribution, rather than only using the best transcription, we can stabilize training further. With these techniques, our ST models match prior works without an external language model.
Position Prediction as an Effective Pretraining Strategy
Jul 15, 2022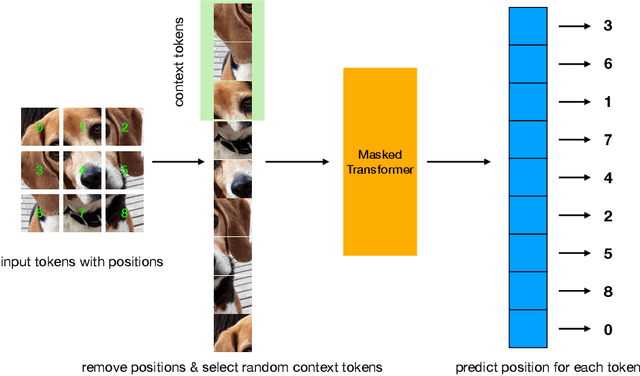


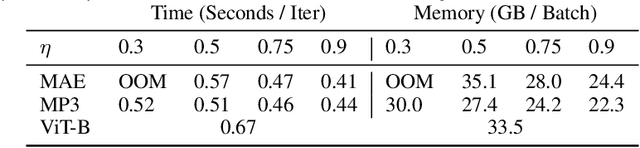
Transformers have gained increasing popularity in a wide range of applications, including Natural Language Processing (NLP), Computer Vision and Speech Recognition, because of their powerful representational capacity. However, harnessing this representational capacity effectively requires a large amount of data, strong regularization, or both, to mitigate overfitting. Recently, the power of the Transformer has been unlocked by self-supervised pretraining strategies based on masked autoencoders which rely on reconstructing masked inputs, directly, or contrastively from unmasked content. This pretraining strategy which has been used in BERT models in NLP, Wav2Vec models in Speech and, recently, in MAE models in Vision, forces the model to learn about relationships between the content in different parts of the input using autoencoding related objectives. In this paper, we propose a novel, but surprisingly simple alternative to content reconstruction~-- that of predicting locations from content, without providing positional information for it. Doing so requires the Transformer to understand the positional relationships between different parts of the input, from their content alone. This amounts to an efficient implementation where the pretext task is a classification problem among all possible positions for each input token. We experiment on both Vision and Speech benchmarks, where our approach brings improvements over strong supervised training baselines and is comparable to modern unsupervised/self-supervised pretraining methods. Our method also enables Transformers trained without position embeddings to outperform ones trained with full position information.
Flashlight: Enabling Innovation in Tools for Machine Learning
Jan 29, 2022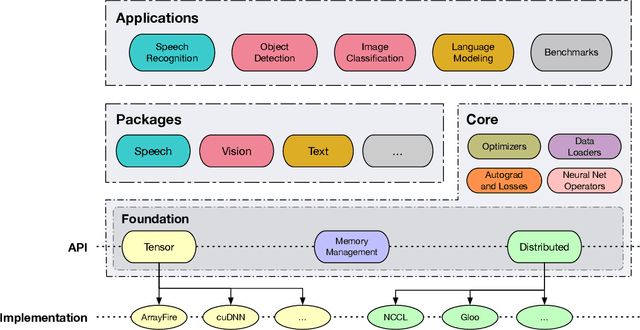
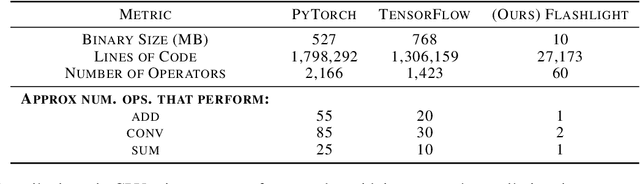
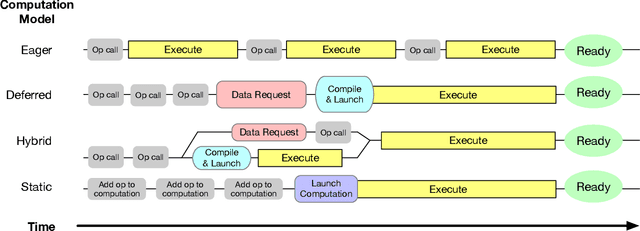
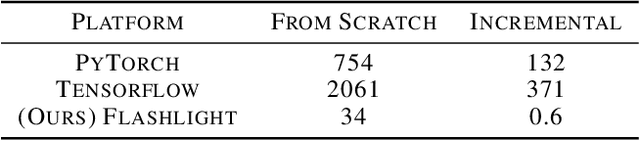
As the computational requirements for machine learning systems and the size and complexity of machine learning frameworks increases, essential framework innovation has become challenging. While computational needs have driven recent compiler, networking, and hardware advancements, utilization of those advancements by machine learning tools is occurring at a slower pace. This is in part due to the difficulties involved in prototyping new computational paradigms with existing frameworks. Large frameworks prioritize machine learning researchers and practitioners as end users and pay comparatively little attention to systems researchers who can push frameworks forward -- we argue that both are equally important stakeholders. We introduce Flashlight, an open-source library built to spur innovation in machine learning tools and systems by prioritizing open, modular, customizable internals and state-of-the-art, research-ready models and training setups across a variety of domains. Flashlight allows systems researchers to rapidly prototype and experiment with novel ideas in machine learning computation and has low overhead, competing with and often outperforming other popular machine learning frameworks. We see Flashlight as a tool enabling research that can benefit widely used libraries downstream and bring machine learning and systems researchers closer together.
Pseudo-Labeling for Massively Multilingual Speech Recognition
Oct 30, 2021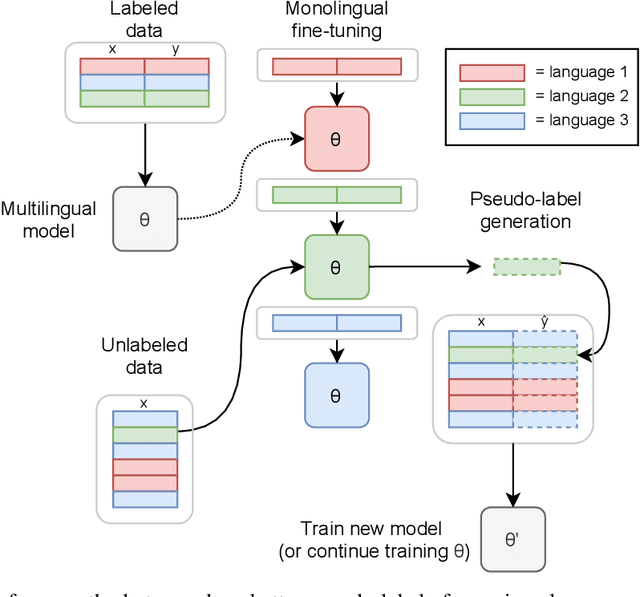
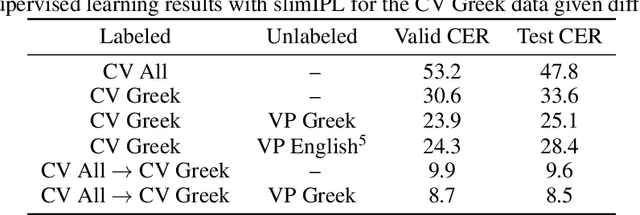
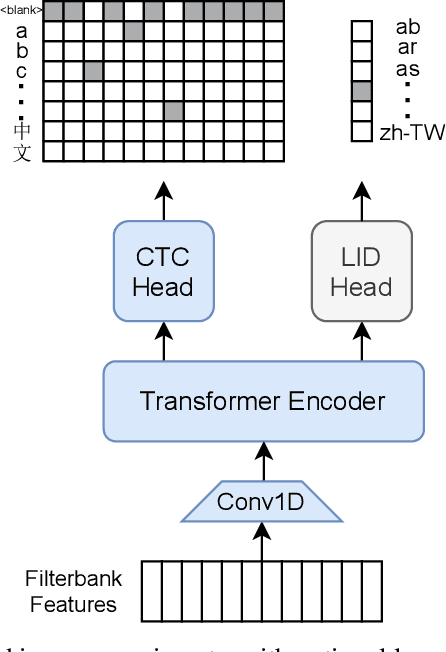
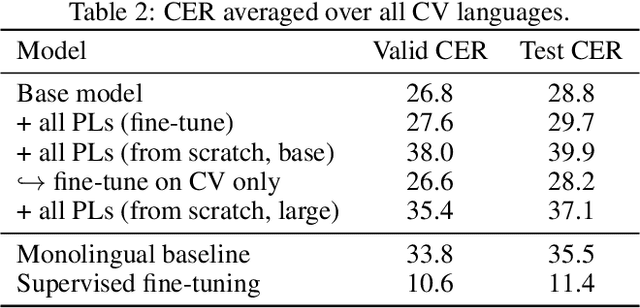
Semi-supervised learning through pseudo-labeling has become a staple of state-of-the-art monolingual speech recognition systems. In this work, we extend pseudo-labeling to massively multilingual speech recognition with 60 languages. We propose a simple pseudo-labeling recipe that works well even with low-resource languages: train a supervised multilingual model, fine-tune it with semi-supervised learning on a target language, generate pseudo-labels for that language, and train a final model using pseudo-labels for all languages, either from scratch or by fine-tuning. Experiments on the labeled Common Voice and unlabeled VoxPopuli datasets show that our recipe can yield a model with better performance for many languages that also transfers well to LibriSpeech.
Word Order Does Not Matter For Speech Recognition
Oct 18, 2021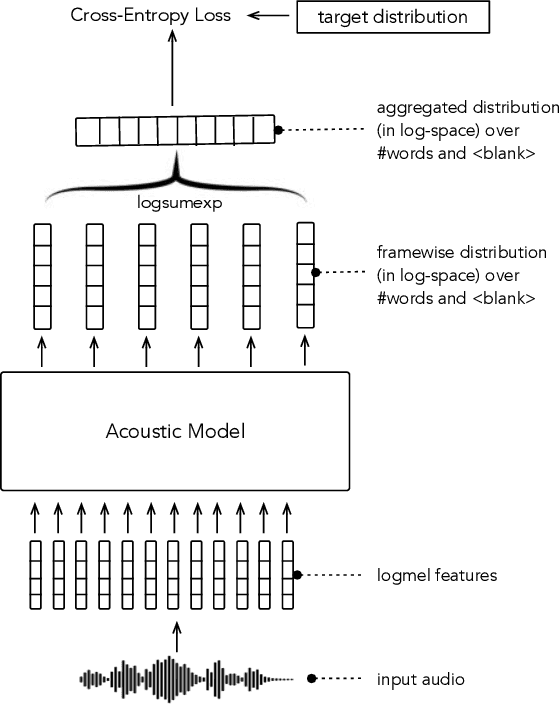
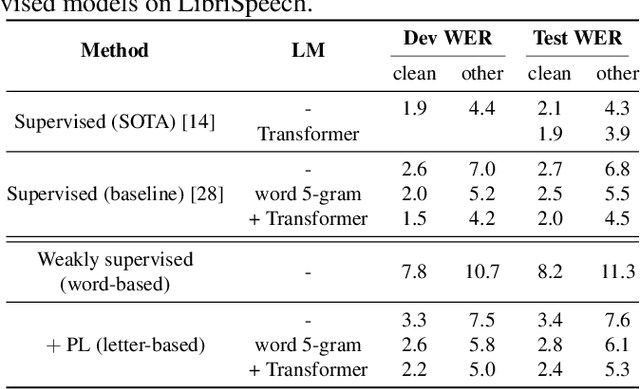
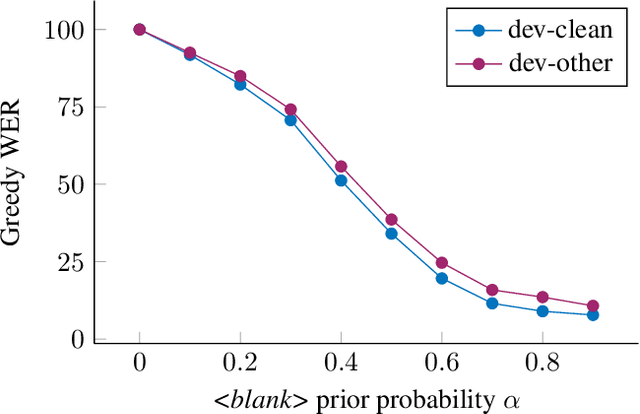

In this paper, we study training of automatic speech recognition system in a weakly supervised setting where the order of words in transcript labels of the audio training data is not known. We train a word-level acoustic model which aggregates the distribution of all output frames using LogSumExp operation and uses a cross-entropy loss to match with the ground-truth words distribution. Using the pseudo-labels generated from this model on the training set, we then train a letter-based acoustic model using Connectionist Temporal Classification loss. Our system achieves 2.3%/4.6% on test-clean/test-other subsets of LibriSpeech, which closely matches with the supervised baseline's performance.
Kaizen: Continuously improving teacher using Exponential Moving Average for semi-supervised speech recognition
Jun 14, 2021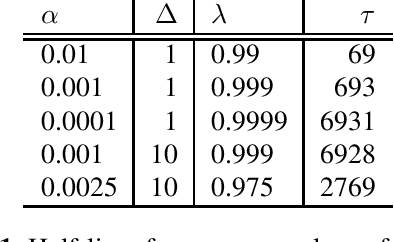
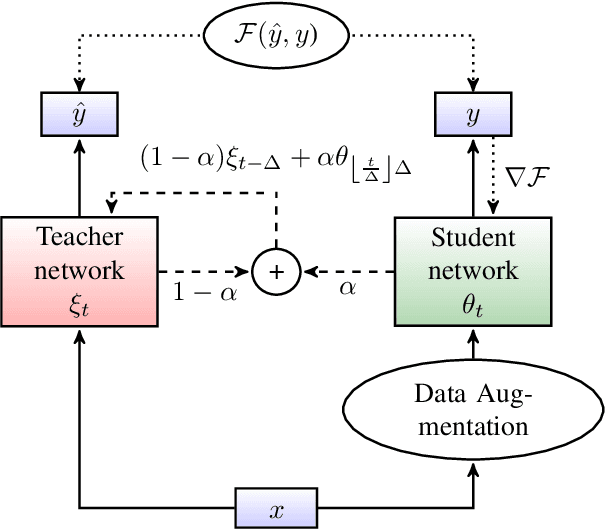
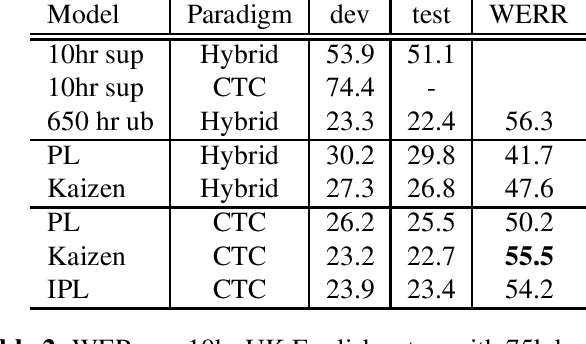
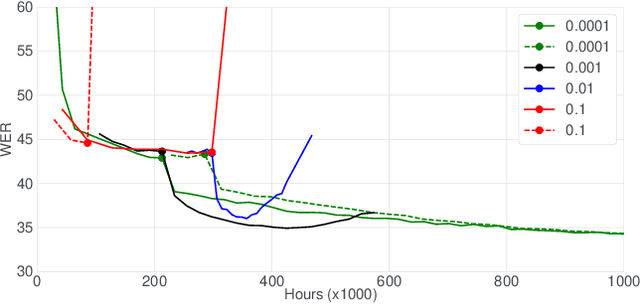
In this paper, we introduce the Kaizen framework that uses a continuously improving teacher to generate pseudo-labels for semi-supervised training. The proposed approach uses a teacher model which is updated as the exponential moving average of the student model parameters. This can be seen as a continuous version of the iterative pseudo-labeling approach for semi-supervised training. It is applicable for different training criteria, and in this paper we demonstrate it for frame-level hybrid hidden Markov model - deep neural network (HMM-DNN) models and sequence-level connectionist temporal classification (CTC) based models. The proposed approach shows more than 10% word error rate (WER) reduction over standard teacher-student training and more than 50\% relative WER reduction over 10 hour supervised baseline when using large scale realistic unsupervised public videos in UK English and Italian languages.
CAPE: Encoding Relative Positions with Continuous Augmented Positional Embeddings
Jun 06, 2021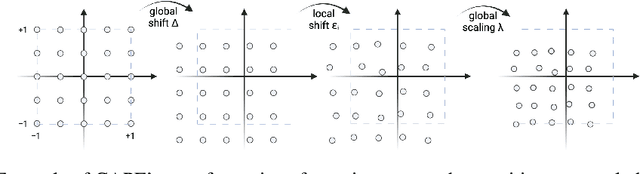
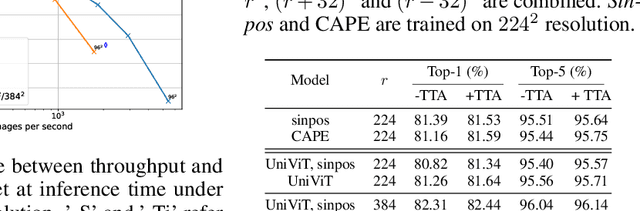
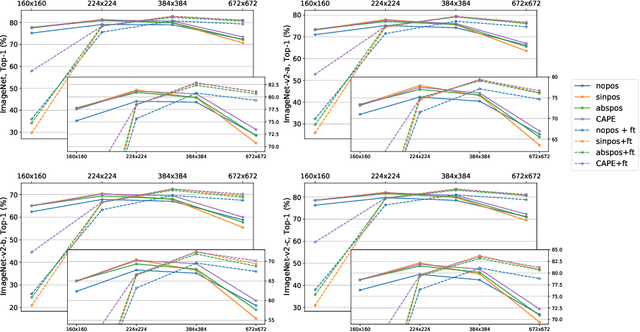
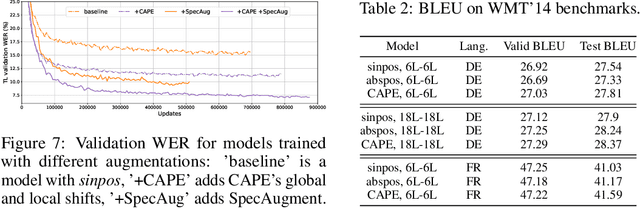
Without positional information, attention-based transformer neural networks are permutation-invariant. Absolute or relative positional embeddings are the most popular ways to feed transformer models positional information. Absolute positional embeddings are simple to implement, but suffer from generalization issues when evaluating on sequences of different length than those seen at training time. Relative positions are more robust to length change, but are more complex to implement and yield inferior model throughput. In this paper, we propose an augmentation-based approach (CAPE) for absolute positional embeddings, which keeps the advantages of both absolute (simplicity and speed) and relative position embeddings (better generalization). In addition, our empirical evaluation on state-of-the-art models in machine translation, image and speech recognition demonstrates that CAPE leads to better generalization performance as well as increased stability with respect to training hyper-parameters.
Robust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-Training
Apr 02, 2021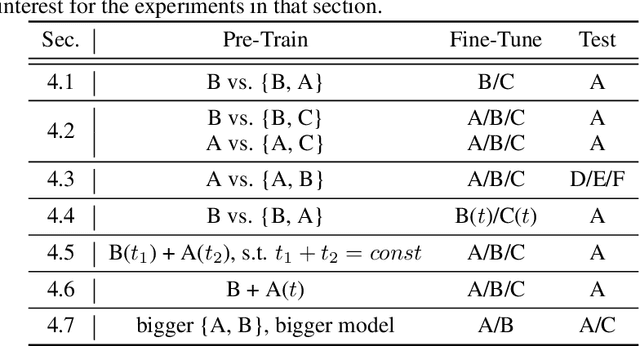
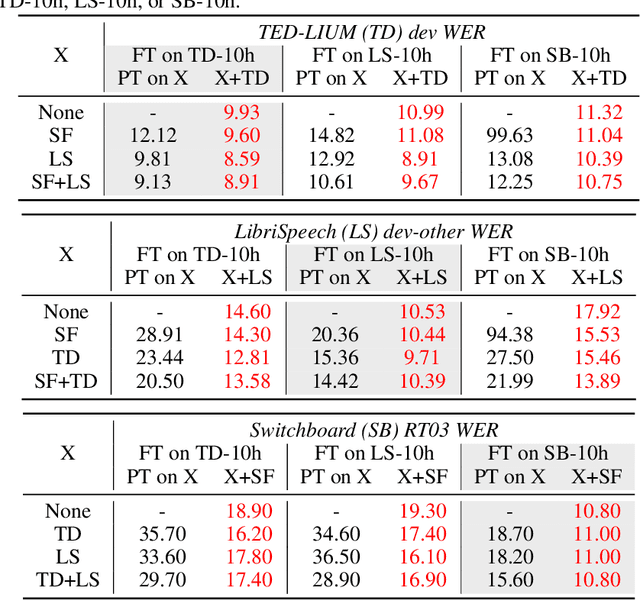
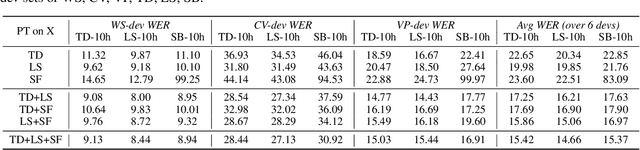
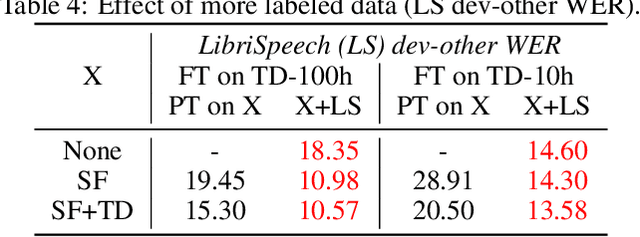
Self-supervised learning of speech representations has been a very active research area but most work is focused on a single domain such as read audio books for which there exist large quantities of labeled and unlabeled data. In this paper, we explore more general setups where the domain of the unlabeled data for pre-training data differs from the domain of the labeled data for fine-tuning, which in turn may differ from the test data domain. Our experiments show that using target domain data during pre-training leads to large performance improvements across a variety of setups. On a large-scale competitive setup, we show that pre-training on unlabeled in-domain data reduces the gap between models trained on in-domain and out-of-domain labeled data by 66%-73%. This has obvious practical implications since it is much easier to obtain unlabeled target domain data than labeled data. Moreover, we find that pre-training on multiple domains improves generalization performance on domains not seen during training. Code and models will be made available at https://github.com/pytorch/fairseq.
Joint Masked CPC and CTC Training for ASR
Oct 30, 2020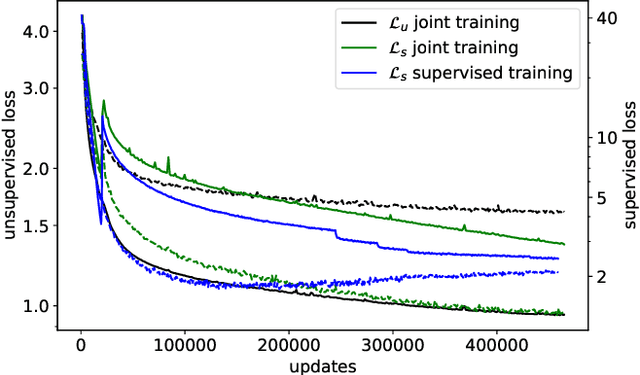
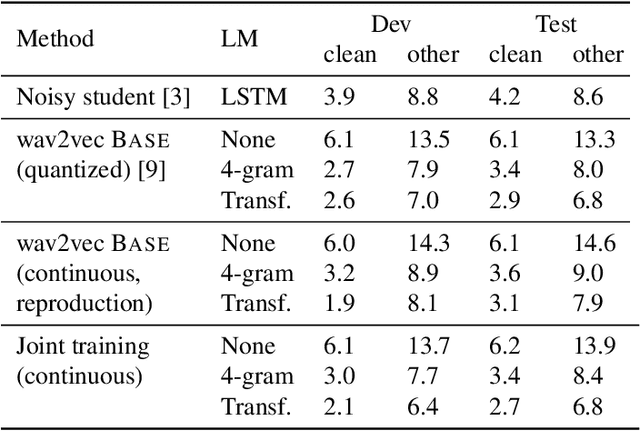
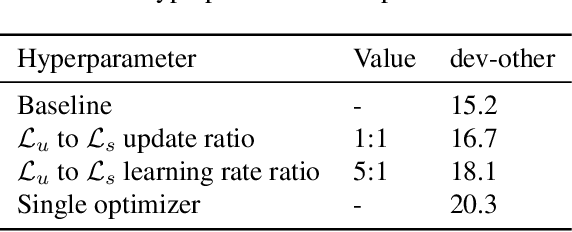
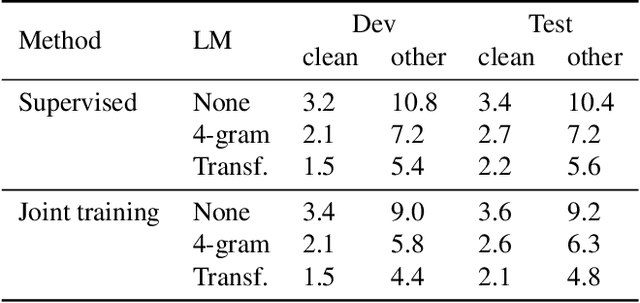
Self-supervised learning (SSL) has shown promise in learning representations of audio that are useful for automatic speech recognition (ASR). But, training SSL models like wav2vec~2.0 requires a two-stage pipeline. In this paper we demonstrate a single-stage training of ASR models that can utilize both unlabeled and labeled data. During training, we alternately minimize two losses: an unsupervised masked Contrastive Predictive Coding (CPC) loss and the supervised audio-to-text alignment loss Connectionist Temporal Classification (CTC). We show that this joint training method directly optimizes performance for the downstream ASR task using unsupervised data while achieving similar word error rates to wav2vec~2.0 on the Librispeech 100-hour dataset. Finally, we postulate that solving the contrastive task is a regularization for the supervised CTC loss.