 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Attention with Performers
Sep 30, 2020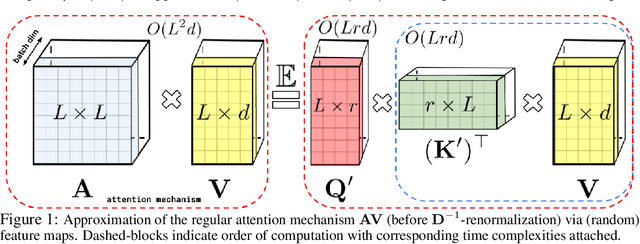
We introduce Performers, Transformer architectures which can estimate regular (softmax) full-rank-attention Transformers with provable accuracy, but using only linear (as opposed to quadratic) space and time complexity, without relying on any priors such as sparsity or low-rankness. To approximate softmax attention-kernels, Performers use a novel Fast Attention Via positive Orthogonal Random features approach (FAVOR+), which may be of independent interest for scalable kernel methods. FAVOR+ can be also used to efficiently model kernelizable attention mechanisms beyond softmax. This representational power is crucial to accurately compare softmax with other kernels for the first time on large-scale tasks, beyond the reach of regular Transformers, and investigate optimal attention-kernels. Performers are linear architectures fully compatible with regular Transformers and with strong theoretical guarantees: unbiased or nearly-unbiased estimation of the attention matrix, uniform convergence and low estimation variance. We tested Performers on a rich set of tasks stretching from pixel-prediction through text models to protein sequence modeling. We demonstrate competitive results with other examined efficient sparse and dense attention methods, showcasing effectiveness of the novel attention-learning paradigm leveraged by Performers.
Masked Language Modeling for Proteins via Linearly Scalable Long-Context Transformers
Jun 05, 2020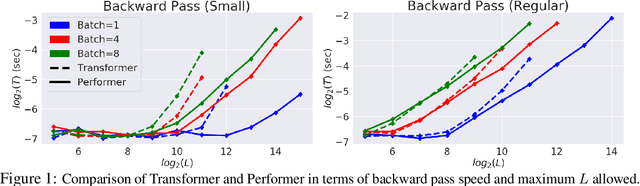
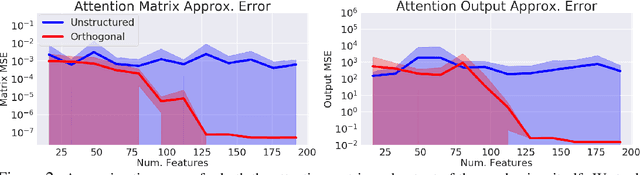
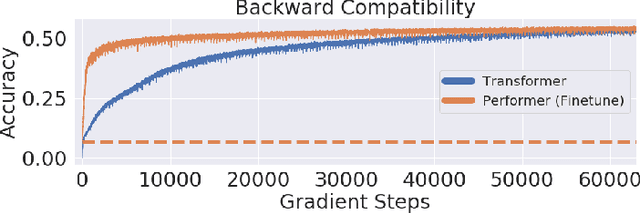
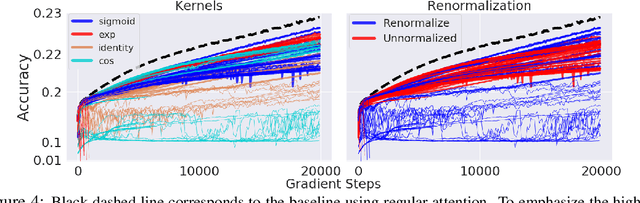
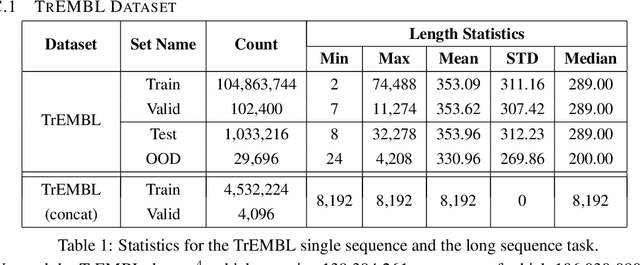
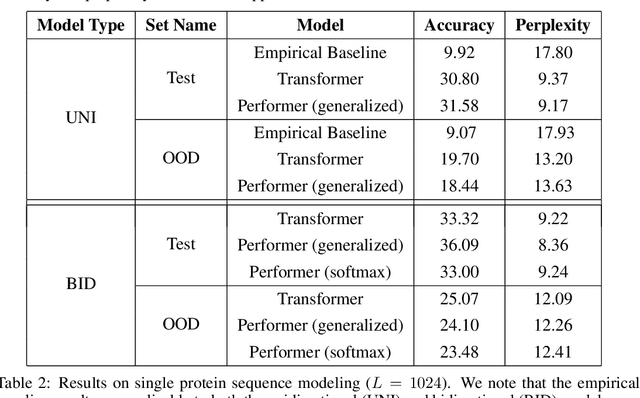
Transformer models have achieved state-of-the-art results across a diverse range of domains. However, concern over the cost of training the attention mechanism to learn complex dependencies between distant inputs continues to grow. In response, solutions that exploit the structure and sparsity of the learned attention matrix have blossomed. However, real-world applications that involve long sequences, such as biological sequence analysis, may fall short of meeting these assumptions, precluding exploration of these models. To address this challenge, we present a new Transformer architecture, Performer, based on Fast Attention Via Orthogonal Random features (FAVOR). Our mechanism scales linearly rather than quadratically in the number of tokens in the sequence, is characterized by sub-quadratic space complexity and does not incorporate any sparsity pattern priors. Furthermore, it provides strong theoretical guarantees: unbiased estimation of the attention matrix and uniform convergence. It is also backwards-compatible with pre-trained regular Transformers. We demonstrate its effectiveness on the challenging task of protein sequence modeling and provide detailed theoretical analysis.
Stochastic Flows and Geometric Optimization on the Orthogonal Group
Mar 30, 2020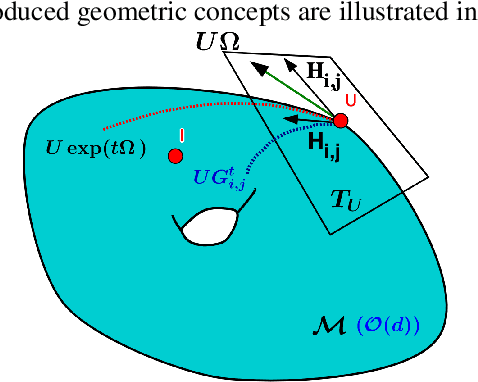
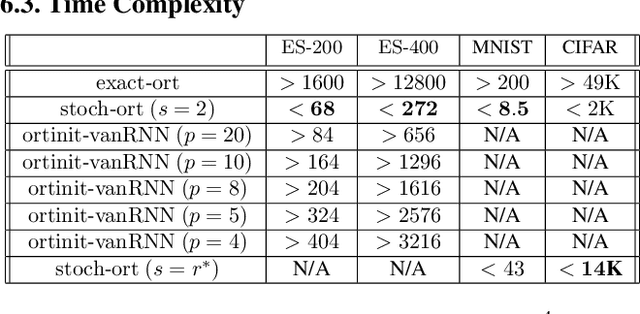


We present a new class of stochastic, geometrically-driven optimization algorithms on the orthogonal group $O(d)$ and naturally reductive homogeneous manifolds obtained from the action of the rotation group $SO(d)$. We theoretically and experimentally demonstrate that our methods can be applied in various fields of machine learning including deep, convolutional and recurrent neural networks, reinforcement learning, normalizing flows and metric learning. We show an intriguing connection between efficient stochastic optimization on the orthogonal group and graph theory (e.g. matching problem, partition functions over graphs, graph-coloring). We leverage the theory of Lie groups and provide theoretical results for the designed class of algorithms. We demonstrate broad applicability of our methods by showing strong performance on the seemingly unrelated tasks of learning world models to obtain stable policies for the most difficult $\mathrm{Humanoid}$ agent from $\mathrm{OpenAI}$ $\mathrm{Gym}$ and improving convolutional neural networks.
Reinforcement Learning with Chromatic Networks
Jul 10, 2019
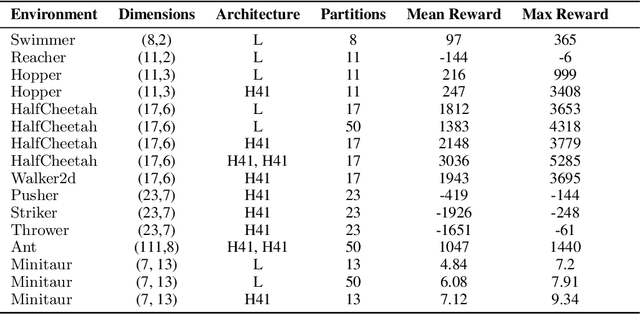
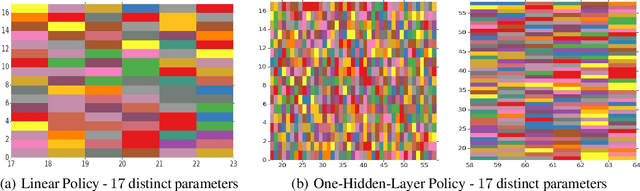
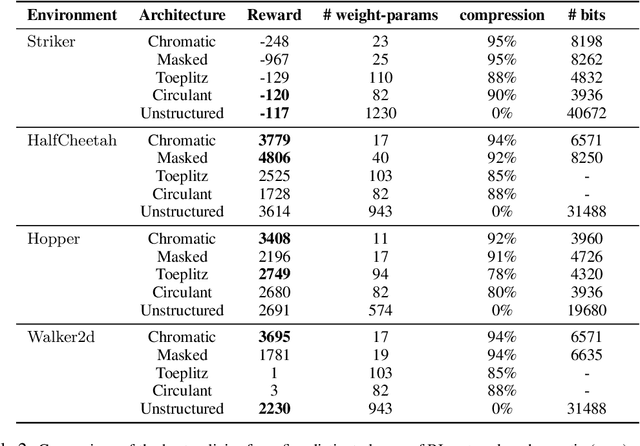
We present a new algorithm for finding compact neural networks encoding reinforcement learning (RL) policies. To do it, we leverage in the novel RL setting the theory of pointer networks and ENAS-type algorithms for combinatorial optimization of RL policies as well as recent evolution strategies (ES) optimization methods, and propose to define the combinatorial search space to be the the set of different edge-partitionings (colorings) into same-weight classes. For several RL tasks, we manage to learn colorings translating to effective policies parameterized by as few as 17 weight parameters, providing 6x compression over state-of-the-art compact policies based on Toeplitz matrices. We believe that our work is one of the first attempts to propose a rigorous approach to training structured neural network architectures for RL problems that are of interest especially in mobile robotics with limited storage and computational resources.
Matrix-Free Preconditioning in Online Learning
May 29, 2019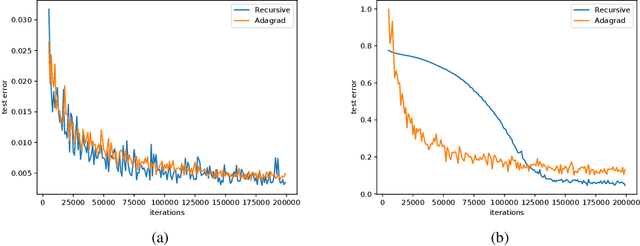
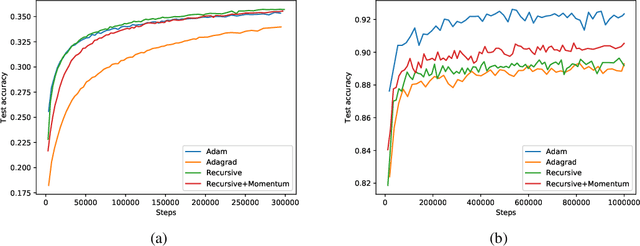
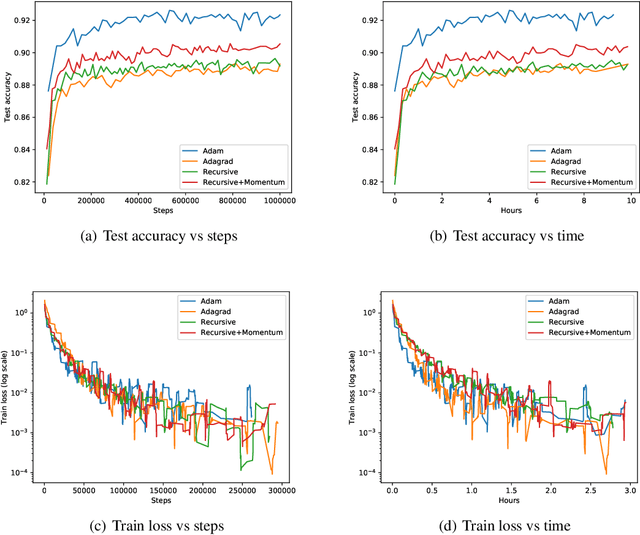
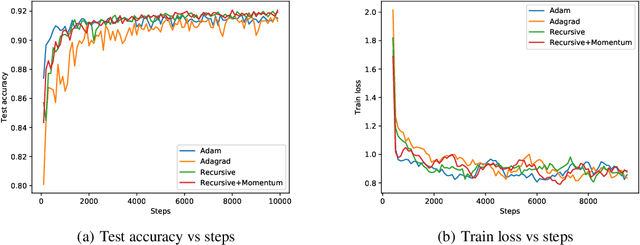
We provide an online convex optimization algorithm with regret that interpolates between the regret of an algorithm using an optimal preconditioning matrix and one using a diagonal preconditioning matrix. Our regret bound is never worse than that obtained by diagonal preconditioning, and in certain setting even surpasses that of algorithms with full-matrix preconditioning. Importantly, our algorithm runs in the same time and space complexity as online gradient descent. Along the way we incorporate new techniques that mildly streamline and improve logarithmic factors in prior regret analyses. We conclude by benchmarking our algorithm on synthetic data and deep learning tasks.
Orthogonal Estimation of Wasserstein Distances
Apr 05, 2019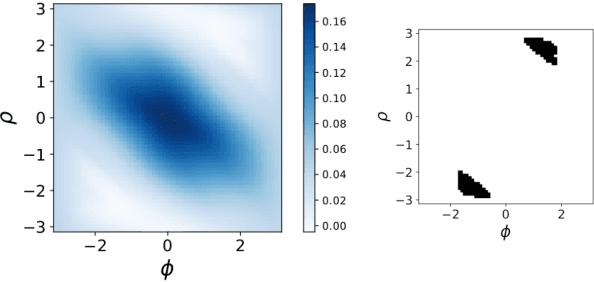
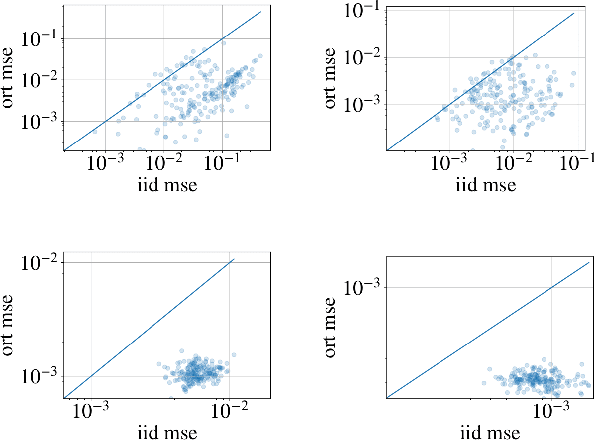
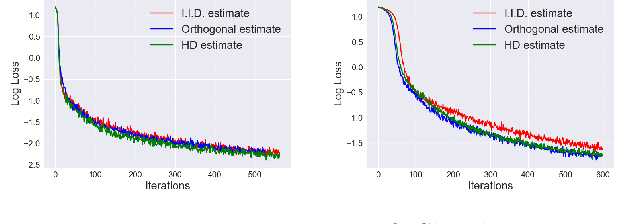
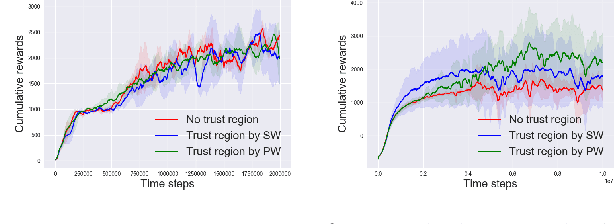
Wasserstein distances are increasingly used in a wide variety of applications in machine learning. Sliced Wasserstein distances form an important subclass which may be estimated efficiently through one-dimensional sorting operations. In this paper, we propose a new variant of sliced Wasserstein distance, study the use of orthogonal coupling in Monte Carlo estimation of Wasserstein distances and draw connections with stratified sampling, and evaluate our approaches experimentally in a range of large-scale experiments in generative modelling and reinforcement learning.
Linear Additive Markov Processes
Apr 05, 2017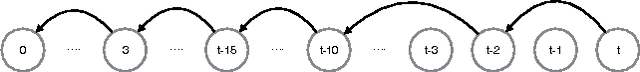

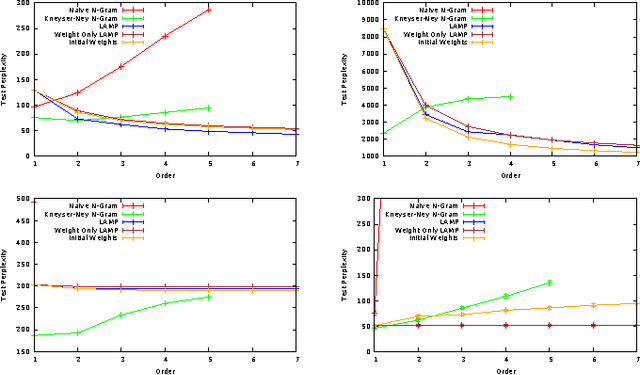

We introduce LAMP: the Linear Additive Markov Process. Transitions in LAMP may be influenced by states visited in the distant history of the process, but unlike higher-order Markov processes, LAMP retains an efficient parametrization. LAMP also allows the specific dependence on history to be learned efficiently from data. We characterize some theoretical properties of LAMP, including its steady-state and mixing time. We then give an algorithm based on alternating minimization to learn LAMP models from data. Finally, we perform a series of real-world experiments to show that LAMP is more powerful than first-order Markov processes, and even holds its own against deep sequential models (LSTMs) with a negligible increase in parameter complexity.
Structured adaptive and random spinners for fast machine learning computations
Nov 26, 2016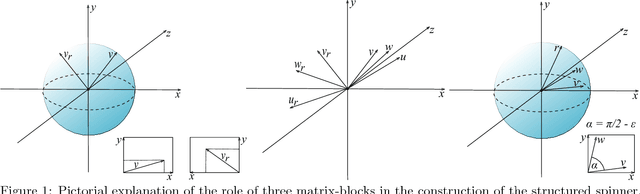
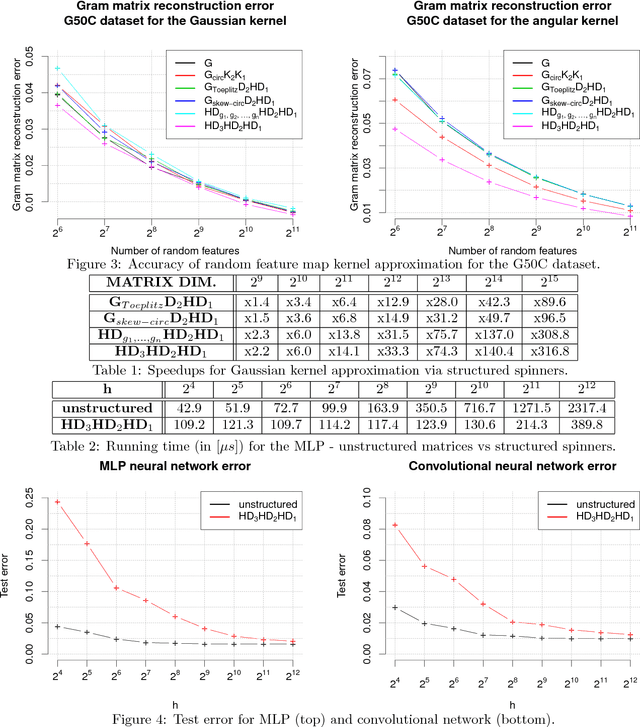
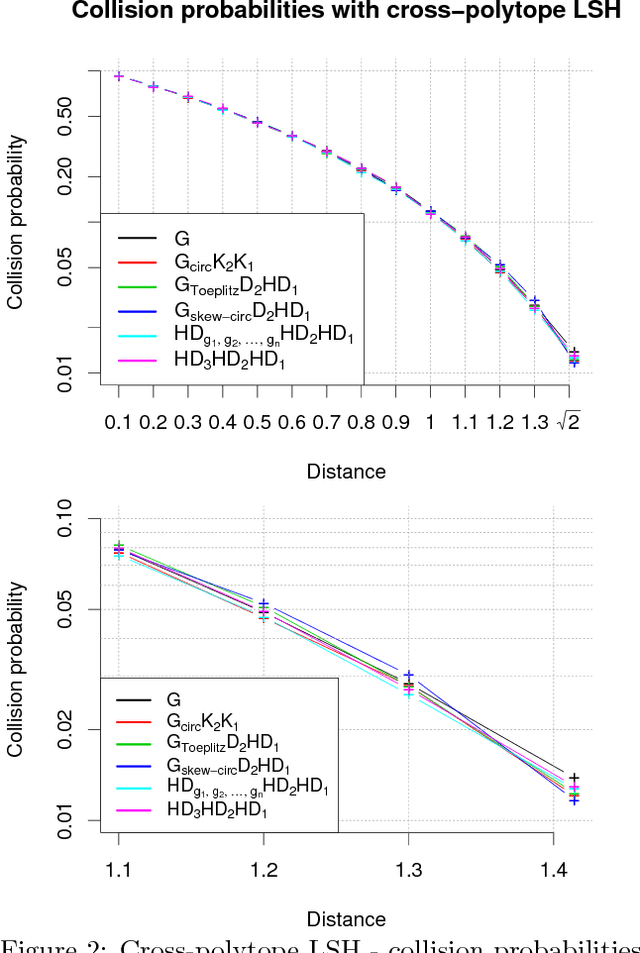
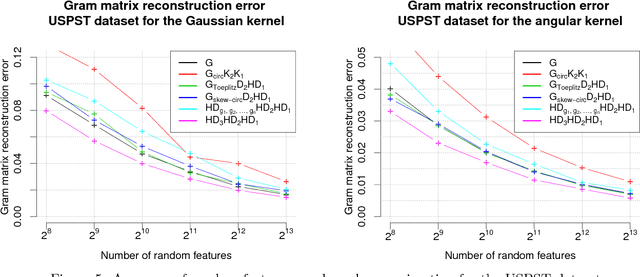
We consider an efficient computational framework for speeding up several machine learning algorithms with almost no loss of accuracy. The proposed framework relies on projections via structured matrices that we call Structured Spinners, which are formed as products of three structured matrix-blocks that incorporate rotations. The approach is highly generic, i.e. i) structured matrices under consideration can either be fully-randomized or learned, ii) our structured family contains as special cases all previously considered structured schemes, iii) the setting extends to the non-linear case where the projections are followed by non-linear functions, and iv) the method finds numerous applications including kernel approximations via random feature maps, dimensionality reduction algorithms, new fast cross-polytope LSH techniques, deep learning, convex optimization algorithms via Newton sketches, quantization with random projection trees, and more. The proposed framework comes with theoretical guarantees characterizing the capacity of the structured model in reference to its unstructured counterpart and is based on a general theoretical principle that we describe in the paper. As a consequence of our theoretical analysis, we provide the first theoretical guarantees for one of the most efficient existing LSH algorithms based on the HD3HD2HD1 structured matrix [Andoni et al., 2015]. The exhaustive experimental evaluation confirms the accuracy and efficiency of structured spinners for a variety of different applications.
TripleSpin - a generic compact paradigm for fast machine learning computations
Jun 06, 2016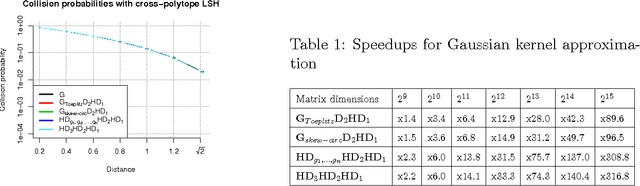
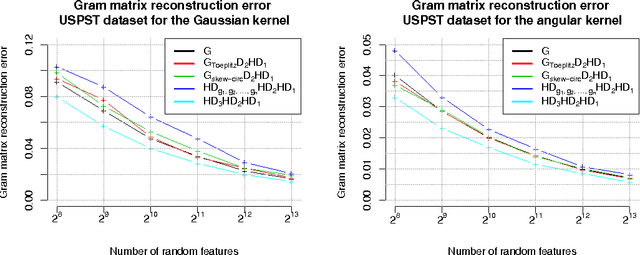
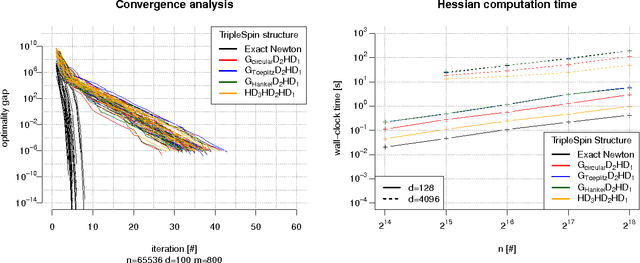
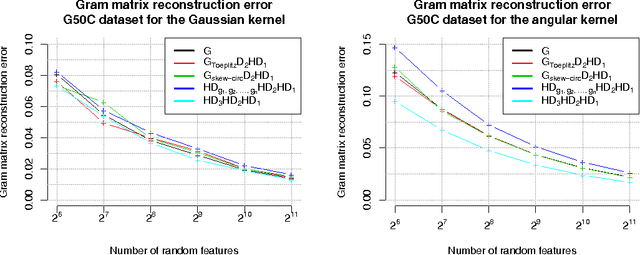
We present a generic compact computational framework relying on structured random matrices that can be applied to speed up several machine learning algorithms with almost no loss of accuracy. The applications include new fast LSH-based algorithms, efficient kernel computations via random feature maps, convex optimization algorithms, quantization techniques and many more. Certain models of the presented paradigm are even more compressible since they apply only bit matrices. This makes them suitable for deploying on mobile devices. All our findings come with strong theoretical guarantees. In particular, as a byproduct of the presented techniques and by using relatively new Berry-Esseen-type CLT for random vectors, we give the first theoretical guarantees for one of the most efficient existing LSH algorithms based on the $\textbf{HD}_{3}\textbf{HD}_{2}\textbf{HD}_{1}$ structured matrix ("Practical and Optimal LSH for Angular Distance"). These guarantees as well as theoretical results for other aforementioned applications follow from the same general theoretical principle that we present in the paper. Our structured family contains as special cases all previously considered structured schemes, including the recently introduced $P$-model. Experimental evaluation confirms the accuracy and efficiency of TripleSpin matrices.
Fastfood: Approximate Kernel Expansions in Loglinear Time
Aug 13, 2014
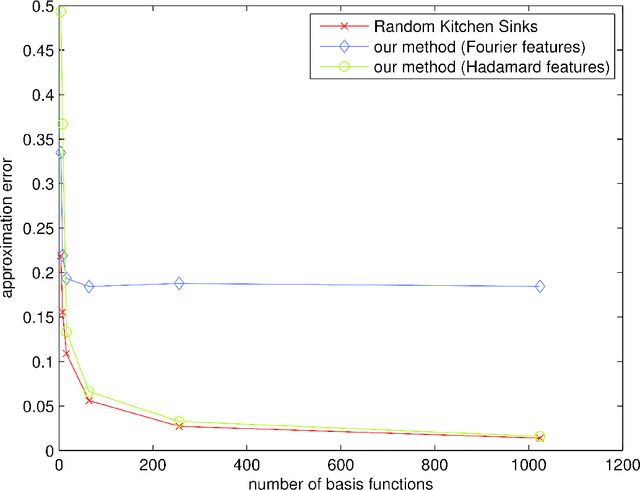
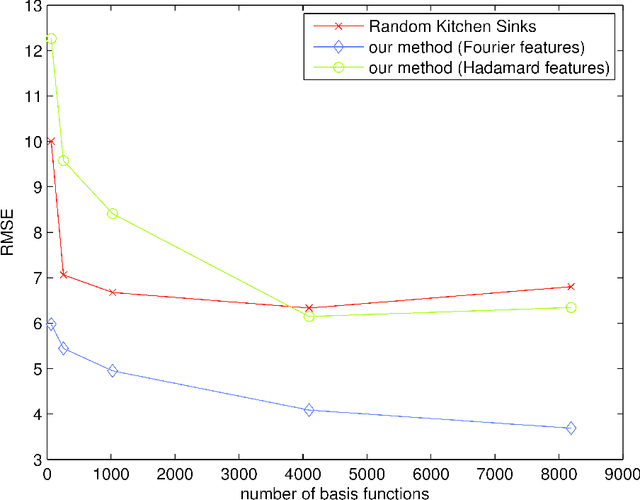
Despite their successes, what makes kernel methods difficult to use in many large scale problems is the fact that storing and computing the decision function is typically expensive, especially at prediction time. In this paper, we overcome this difficulty by proposing Fastfood, an approximation that accelerates such computation significantly. Key to Fastfood is the observation that Hadamard matrices, when combined with diagonal Gaussian matrices, exhibit properties similar to dense Gaussian random matrices. Yet unlike the latter, Hadamard and diagonal matrices are inexpensive to multiply and store. These two matrices can be used in lieu of Gaussian matrices in Random Kitchen Sinks proposed by Rahimi and Recht (2009) and thereby speeding up the computation for a large range of kernel functions. Specifically, Fastfood requires O(n log d) time and O(n) storage to compute n non-linear basis functions in d dimensions, a significant improvement from O(nd) computation and storage, without sacrificing accuracy. Our method applies to any translation invariant and any dot-product kernel, such as the popular RBF kernels and polynomial kernels. We prove that the approximation is unbiased and has low variance. Experiments show that we achieve similar accuracy to full kernel expansions and Random Kitchen Sinks while being 100x faster and using 1000x less memory. These improvements, especially in terms of memory usage, make kernel methods more practical for applications that have large training sets and/or require real-time prediction.