 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Centric AI Governance: Addressing the Limitations of Model-Focused Policies
Sep 25, 2024



Current regulations on powerful AI capabilities are narrowly focused on "foundation" or "frontier" models. However, these terms are vague and inconsistently defined, leading to an unstable foundation for governance efforts. Critically, policy debates often fail to consider the data used with these models, despite the clear link between data and model performance. Even (relatively) "small" models that fall outside the typical definitions of foundation and frontier models can achieve equivalent outcomes when exposed to sufficiently specific datasets. In this work, we illustrate the importance of considering dataset size and content as essential factors in assessing the risks posed by models both today and in the future. More broadly, we emphasize the risk posed by over-regulating reactively and provide a path towards careful, quantitative evaluation of capabilities that can lead to a simplified regulatory environment.
Hyperbolic Learning with Multimodal Large Language Models
Aug 09, 2024Hyperbolic embeddings have demonstrated their effectiveness in capturing measures of uncertainty and hierarchical relationships across various deep-learning tasks, including image segmentation and active learning. However, their application in modern vision-language models (VLMs) has been limited. A notable exception is MERU, which leverages the hierarchical properties of hyperbolic space in the CLIP ViT-large model, consisting of hundreds of millions parameters. In our work, we address the challenges of scaling multi-modal hyperbolic models by orders of magnitude in terms of parameters (billions) and training complexity using the BLIP-2 architecture. Although hyperbolic embeddings offer potential insights into uncertainty not present in Euclidean embeddings, our analysis reveals that scaling these models is particularly difficult. We propose a novel training strategy for a hyperbolic version of BLIP-2, which allows to achieve comparable performance to its Euclidean counterpart, while maintaining stability throughout the training process and showing a meaningful indication of uncertainty with each embedding.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
ALOHa: A New Measure for Hallucination in Captioning Models
Apr 03, 2024



Despite recent advances in multimodal pre-training for visual description, state-of-the-art models still produce captions containing errors, such as hallucinating objects not present in a scene. The existing prominent metric for object hallucination, CHAIR, is limited to a fixed set of MS COCO objects and synonyms. In this work, we propose a modernized open-vocabulary metric, ALOHa, which leverages large language models (LLMs) to measure object hallucinations. Specifically, we use an LLM to extract groundable objects from a candidate caption, measure their semantic similarity to reference objects from captions and object detections, and use Hungarian matching to produce a final hallucination score. We show that ALOHa correctly identifies 13.6% more hallucinated objects than CHAIR on HAT, a new gold-standard subset of MS COCO Captions annotated for hallucinations, and 30.8% more on nocaps, where objects extend beyond MS COCO categories. Our code is available at https://davidmchan.github.io/aloha/.
CLAIR: Evaluating Image Captions with Large Language Models
Oct 19, 2023



The evaluation of machine-generated image captions poses an interesting yet persistent challenge. Effective evaluation measures must consider numerous dimensions of similarity, including semantic relevance, visual structure, object interactions, caption diversity, and specificity. Existing highly-engineered measures attempt to capture specific aspects, but fall short in providing a holistic score that aligns closely with human judgments. Here, we propose CLAIR, a novel method that leverages the zero-shot language modeling capabilities of large language models (LLMs) to evaluate candidate captions. In our evaluations, CLAIR demonstrates a stronger correlation with human judgments of caption quality compared to existing measures. Notably, on Flickr8K-Expert, CLAIR achieves relative correlation improvements over SPICE of 39.6% and over image-augmented methods such as RefCLIP-S of 18.3%. Moreover, CLAIR provides noisily interpretable results by allowing the language model to identify the underlying reasoning behind its assigned score. Code is available at https://davidmchan.github.io/clair/
Simple Token-Level Confidence Improves Caption Correctness
May 11, 2023



The ability to judge whether a caption correctly describes an image is a critical part of vision-language understanding. However, state-of-the-art models often misinterpret the correctness of fine-grained details, leading to errors in outputs such as hallucinating objects in generated captions or poor compositional reasoning. In this work, we explore Token-Level Confidence, or TLC, as a simple yet surprisingly effective method to assess caption correctness. Specifically, we fine-tune a vision-language model on image captioning, input an image and proposed caption to the model, and aggregate either algebraic or learned token confidences over words or sequences to estimate image-caption consistency. Compared to sequence-level scores from pretrained models, TLC with algebraic confidence measures achieves a relative improvement in accuracy by 10% on verb understanding in SVO-Probes and outperforms prior state-of-the-art in image and group scores for compositional reasoning in Winoground by a relative 37% and 9%, respectively. When training data are available, a learned confidence estimator provides further improved performance, reducing object hallucination rates in MS COCO Captions by a relative 30% over the original model and setting a new state-of-the-art.
Prior Knowledge-Guided Attention in Self-Supervised Vision Transformers
Sep 07, 2022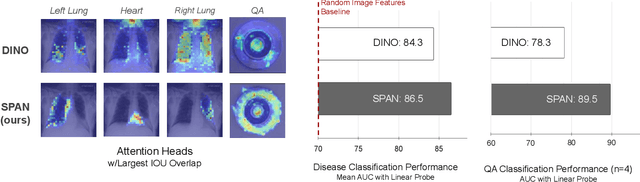
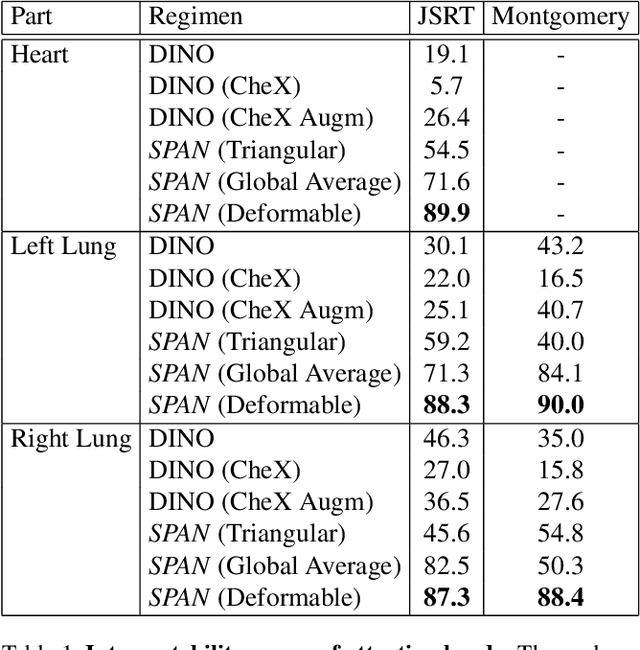
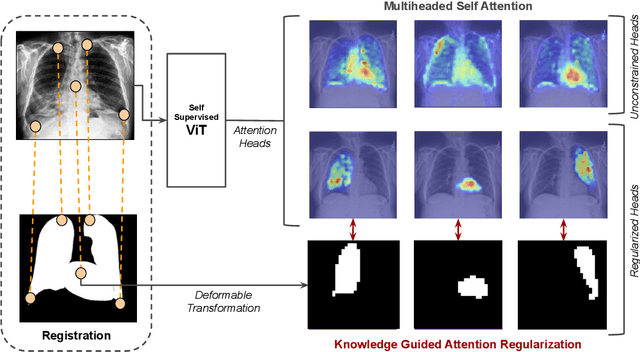

Recent trends in self-supervised representation learning have focused on removing inductive biases from training pipelines. However, inductive biases can be useful in settings when limited data are available or provide additional insight into the underlying data distribution. We present spatial prior attention (SPAN), a framework that takes advantage of consistent spatial and semantic structure in unlabeled image datasets to guide Vision Transformer attention. SPAN operates by regularizing attention masks from separate transformer heads to follow various priors over semantic regions. These priors can be derived from data statistics or a single labeled sample provided by a domain expert. We study SPAN through several detailed real-world scenarios, including medical image analysis and visual quality assurance. We find that the resulting attention masks are more interpretable than those derived from domain-agnostic pretraining. SPAN produces a 58.7 mAP improvement for lung and heart segmentation. We also find that our method yields a 2.2 mAUC improvement compared to domain-agnostic pretraining when transferring the pretrained model to a downstream chest disease classification task. Lastly, we show that SPAN pretraining leads to higher downstream classification performance in low-data regimes compared to domain-agnostic pretraining.
Reliable Visual Question Answering: Abstain Rather Than Answer Incorrectly
Apr 28, 2022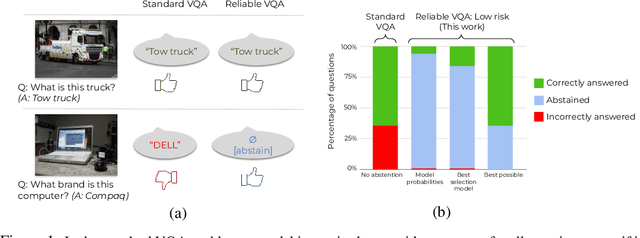
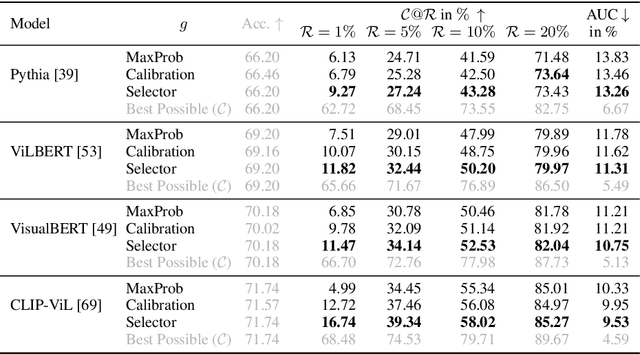


Machine learning has advanced dramatically, narrowing the accuracy gap to humans in multimodal tasks like visual question answering (VQA). However, while humans can say "I don't know" when they are uncertain (i.e., abstain from answering a question), such ability has been largely neglected in multimodal research, despite the importance of this problem to the usage of VQA in real settings. In this work, we promote a problem formulation for reliable VQA, where we prefer abstention over providing an incorrect answer. We first enable abstention capabilities for several VQA models, and analyze both their coverage, the portion of questions answered, and risk, the error on that portion. For that we explore several abstention approaches. We find that although the best performing models achieve over 71% accuracy on the VQA v2 dataset, introducing the option to abstain by directly using a model's softmax scores limits them to answering less than 8% of the questions to achieve a low risk of error (i.e., 1%). This motivates us to utilize a multimodal selection function to directly estimate the correctness of the predicted answers, which we show can triple the coverage from, for example, 5.0% to 16.7% at 1% risk. While it is important to analyze both coverage and risk, these metrics have a trade-off which makes comparing VQA models challenging. To address this, we also propose an Effective Reliability metric for VQA that places a larger cost on incorrect answers compared to abstentions. This new problem formulation, metric, and analysis for VQA provide the groundwork for building effective and reliable VQA models that have the self-awareness to abstain if and only if they don't know the answer.
On Guiding Visual Attention with Language Specification
Feb 17, 2022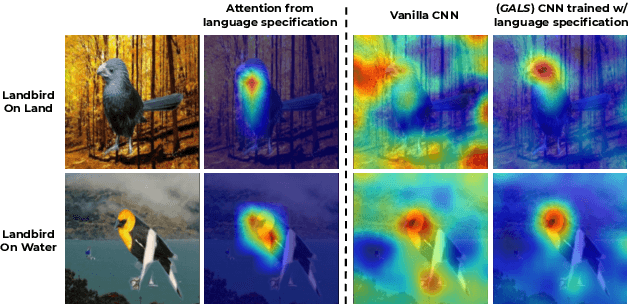

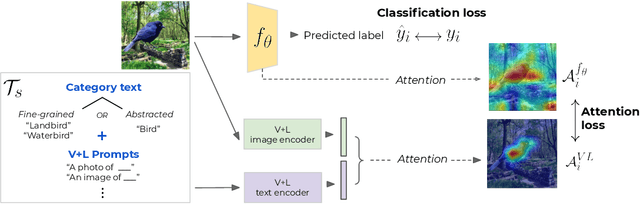
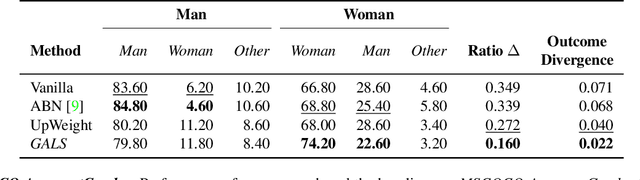
While real world challenges typically define visual categories with language words or phrases, most visual classification methods define categories with numerical indices. However, the language specification of the classes provides an especially useful prior for biased and noisy datasets, where it can help disambiguate what features are task-relevant. Recently, large-scale multimodal models have been shown to recognize a wide variety of high-level concepts from a language specification even without additional image training data, but they are often unable to distinguish classes for more fine-grained tasks. CNNs, in contrast, can extract subtle image features that are required for fine-grained discrimination, but will overfit to any bias or noise in datasets. Our insight is to use high-level language specification as advice for constraining the classification evidence to task-relevant features, instead of distractors. To do this, we ground task-relevant words or phrases with attention maps from a pretrained large-scale model. We then use this grounding to supervise a classifier's spatial attention away from distracting context. We show that supervising spatial attention in this way improves performance on classification tasks with biased and noisy data, including about 3-15% worst-group accuracy improvements and 41-45% relative improvements on fairness metrics.
Remembering for the Right Reasons: Explanations Reduce Catastrophic Forgetting
Oct 04, 2020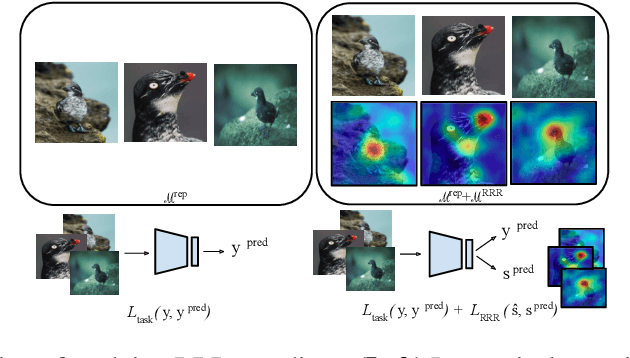

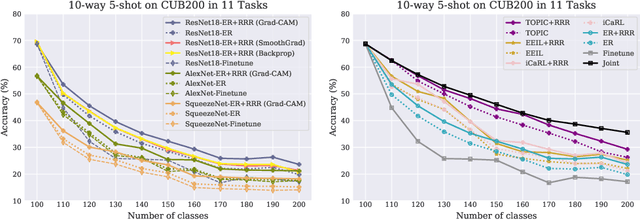

The goal of continual learning (CL) is to learn a sequence of tasks without suffering from the phenomenon of catastrophic forgetting. Previous work has shown that leveraging memory in the form of a replay buffer can reduce performance degradation on prior tasks. We hypothesize that forgetting can be further reduced when the model is encouraged to remember the \textit{evidence} for previously made decisions. As a first step towards exploring this hypothesis, we propose a simple novel training paradigm, called Remembering for the Right Reasons (RRR), that additionally stores visual model explanations for each example in the buffer and ensures the model has "the right reasons" for its predictions by encouraging its explanations to remain consistent with those used to make decisions at training time. Without this constraint, there is a drift in explanations and increase in forgetting as conventional continual learning algorithms learn new tasks. We demonstrate how RRR can be easily added to any memory or regularization-based approach and results in reduced forgetting, and more importantly, improved model explanations. We have evaluated our approach in the standard and few-shot settings and observed a consistent improvement across various CL approaches using different architectures and techniques to generate model explanations and demonstrated our approach showing a promising connection between explainability and continual learning. Our code is available at https://github.com/SaynaEbrahimi/Remembering-for-the-Right-Reasons.