 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Grid Data: Exploring Graph Neural Networks for Earth Observation
Nov 05, 2024



Earth Observation (EO) data analysis has been significantly revolutionized by deep learning (DL), with applications typically limited to grid-like data structures. Graph Neural Networks (GNNs) emerge as an important innovation, propelling DL into the non-Euclidean domain. Naturally, GNNs can effectively tackle the challenges posed by diverse modalities, multiple sensors, and the heterogeneous nature of EO data. To introduce GNNs in the related domains, our review begins by offering fundamental knowledge on GNNs. Then, we summarize the generic problems in EO, to which GNNs can offer potential solutions. Following this, we explore a broad spectrum of GNNs' applications to scientific problems in Earth systems, covering areas such as weather and climate analysis, disaster management, air quality monitoring, agriculture, land cover classification, hydrological process modeling, and urban modeling. The rationale behind adopting GNNs in these fields is explained, alongside methodologies for organizing graphs and designing favorable architectures for various tasks. Furthermore, we highlight methodological challenges of implementing GNNs in these domains and possible solutions that could guide future research. While acknowledging that GNNs are not a universal solution, we conclude the paper by comparing them with other popular architectures like transformers and analyzing their potential synergies.
Segment Using Just One Example
Aug 14, 2024



Semantic segmentation is an important topic in computer vision with many relevant application in Earth observation. While supervised methods exist, the constraints of limited annotated data has encouraged development of unsupervised approaches. However, existing unsupervised methods resemble clustering and cannot be directly mapped to explicit target classes. In this paper, we deal with single shot semantic segmentation, where one example for the target class is provided, which is used to segment the target class from query/test images. Our approach exploits recently popular Segment Anything (SAM), a promptable foundation model. We specifically design several techniques to automatically generate prompts from the only example/key image in such a way that the segmentation is successfully achieved on a stitch or concatenation of the example/key and query/test images. Proposed technique does not involve any training phase and just requires one example image to grasp the concept. Furthermore, no text-based prompt is required for the proposed method. We evaluated the proposed techniques on building and car classes.
Specialized Change Detection using Segment Anything
Aug 13, 2024Change detection (CD) is a fundamental task in Earth observation. While most change detection methods detect all changes, there is a growing need for specialized methods targeting specific changes relevant to particular applications while discarding the other changes. For instance, urban management might prioritize detecting the disappearance of buildings due to natural disasters or other reasons. Furthermore, while most supervised change detection methods require large-scale training datasets, in many applications only one or two training examples might be available instead of large datasets. Addressing such needs, we propose a focused CD approach using the Segment Anything Model (SAM), a versatile vision foundation model. Our method leverages a binary mask of the object of interest in pre-change images to detect their disappearance in post-change images. By using SAM's robust segmentation capabilities, we create prompts from the pre-change mask, use those prompts to segment the post-change image, and identify missing objects. This unsupervised approach demonstrated for building disappearance detection, is adaptable to various domains requiring specialized CD. Our contributions include defining a novel CD problem, proposing a method using SAM, and demonstrating its effectiveness. The proposed method also has benefits related to privacy preservation.
Cluster-Segregate-Perturb (CSP): A Model-agnostic Explainability Pipeline for Spatiotemporal Land Surface Forecasting Models
Aug 12, 2024Satellite images have become increasingly valuable for modelling regional climate change effects. Earth surface forecasting represents one such task that integrates satellite images with meteorological data to capture the joint evolution of regional climate change effects. However, understanding the complex relationship between specific meteorological variables and land surface evolution poses a significant challenge. In light of this challenge, our paper introduces a pipeline that integrates principles from both perturbation-based explainability techniques like LIME and global marginal explainability techniques like PDP, besides addressing the constraints of using such techniques when applying them to high-dimensional spatiotemporal deep models. The proposed pipeline simplifies the undertaking of diverse investigative analyses, such as marginal sensitivity analysis, marginal correlation analysis, lag analysis, etc., on complex land surface forecasting models In this study we utilised Convolutional Long Short-Term Memory (ConvLSTM) as the surface forecasting model and did analyses on the Normalized Difference Vegetation Index (NDVI) of the surface forecasts, since meteorological variables like temperature, pressure, and precipitation significantly influence it. The study area encompasses various regions in Europe. Our analyses show that precipitation exhibits the highest sensitivity in the study area, followed by temperature and pressure. Pressure has little to no direct effect on NDVI. Additionally, interesting nonlinear correlations between meteorological variables and NDVI have been uncovered.
Confidence Estimation in Unsupervised Deep Change Vector Analysis
May 16, 2024Unsupervised transfer learning-based change detection methods exploit the feature extraction capability of pre-trained networks to distinguish changed pixels from the unchanged ones. However, their performance may vary significantly depending on several geographical and model-related aspects. In many applications, it is of utmost importance to provide trustworthy or confident results, even if over a subset of pixels. The core challenge in this problem is to identify changed pixels and confident pixels in an unsupervised manner. To address this, we propose a two-network model - one tasked with mere change detection and the other with confidence estimation. While the change detection network can be used in conjunction with popular transfer learning-based change detection methods such as Deep Change Vector Analysis, the confidence estimation network operates similarly to a randomized smoothing model. By ingesting ensembles of inputs perturbed by noise, it creates a distribution over the output and assigns confidence to each pixel's outcome. We tested the proposed method on three different Earth observation sensors: optical, Synthetic Aperture Radar, and hyperspectral sensors.
Evolution of urban areas and land surface temperature
Jan 05, 2024With the global population on the rise, our cities have been expanding to accommodate the growing number of people. The expansion of cities generally leads to the engulfment of peripheral areas. However, such expansion of urban areas is likely to cause increment in areas with increased land surface temperature (LST). By considering each summer as a data point, we form LST multi-year time-series and cluster it to obtain spatio-temporal pattern. We observe several interesting phenomena from these patterns, e.g., some clusters show reasonable similarity to the built-up area, whereas the locations with high temporal variation are seen more in the peripheral areas. Furthermore, the LST center of mass shifts over the years for cities with development activities tilted towards a direction. We conduct the above-mentioned studies for three different cities in three different continents.
Exploring Geometric Deep Learning For Precipitation Nowcasting
Sep 11, 2023



Precipitation nowcasting (up to a few hours) remains a challenge due to the highly complex local interactions that need to be captured accurately. Convolutional Neural Networks rely on convolutional kernels convolving with grid data and the extracted features are trapped by limited receptive field, typically expressed in excessively smooth output compared to ground truth. Thus they lack the capacity to model complex spatial relationships among the grids. Geometric deep learning aims to generalize neural network models to non-Euclidean domains. Such models are more flexible in defining nodes and edges and can effectively capture dynamic spatial relationship among geographical grids. Motivated by this, we explore a geometric deep learning-based temporal Graph Convolutional Network (GCN) for precipitation nowcasting. The adjacency matrix that simulates the interactions among grid cells is learned automatically by minimizing the L1 loss between prediction and ground truth pixel value during the training procedure. Then, the spatial relationship is refined by GCN layers while the temporal information is extracted by 1D convolution with various kernel lengths. The neighboring information is fed as auxiliary input layers to improve the final result. We test the model on sequences of radar reflectivity maps over the Trento/Italy area. The results show that GCNs improves the effectiveness of modeling the local details of the cloud profile as well as the prediction accuracy by achieving decreased error measures.
Deep Unsupervised Learning for 3D ALS Point Clouds Change Detection
May 05, 2023



Change detection from traditional optical images has limited capability to model the changes in the height or shape of objects. Change detection using 3D point cloud aerial LiDAR survey data can fill this gap by providing critical depth information. While most existing machine learning based 3D point cloud change detection methods are supervised, they severely depend on the availability of annotated training data, which is in practice a critical point. To circumnavigate this dependence, we propose an unsupervised 3D point cloud change detection method mainly based on self-supervised learning using deep clustering and contrastive learning. The proposed method also relies on an adaptation of deep change vector analysis to 3D point cloud via nearest point comparison. Experiments conducted on a publicly available real dataset show that the proposed method obtains higher performance in comparison to the traditional unsupervised methods, with a gain of about 9% in mean accuracy (to reach more than 85%). Thus, it appears to be a relevant choice in scenario where prior knowledge (labels) is not ensured.
Spatial Context Awareness for Unsupervised Change Detection in Optical Satellite Images
Oct 05, 2021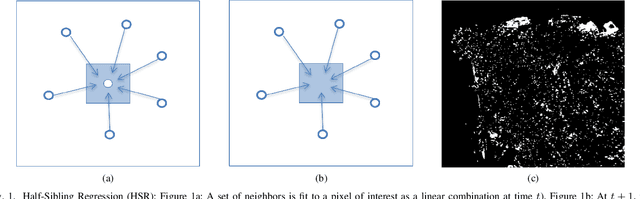


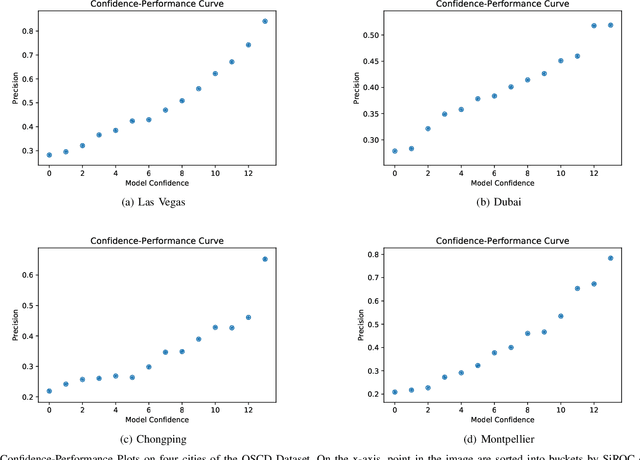
Detecting changes on the ground in multitemporal Earth observation data is one of the key problems in remote sensing. In this paper, we introduce Sibling Regression for Optical Change detection (SiROC), an unsupervised method for change detection in optical satellite images with medium and high resolution. SiROC is a spatial context-based method that models a pixel as a linear combination of its distant neighbors. It uses this model to analyze differences in the pixel and its spatial context-based predictions in subsequent time periods for change detection. We combine this spatial context-based change detection with ensembling over mutually exclusive neighborhoods and transitioning from pixel to object-level changes with morphological operations. SiROC achieves competitive performance for change detection with medium-resolution Sentinel-2 and high-resolution Planetscope imagery on four datasets. Besides accurate predictions without the need for training, SiROC also provides a well-calibrated uncertainty of its predictions. This makes the method especially useful in conjunction with deep-learning based methods for applications such as pseudo-labeling.
Reiterative Domain Aware Multi-target Adaptation
Aug 26, 2021
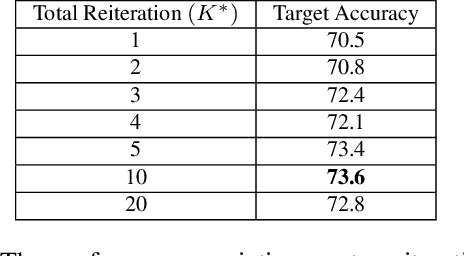
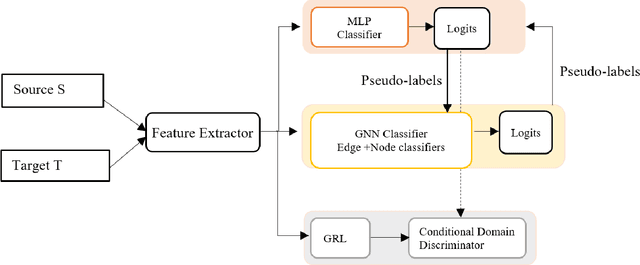
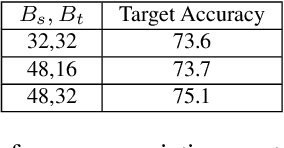
Most domain adaptation methods focus on single-source-single-target adaptation setting. Multi-target domain adaptation is a powerful extension in which a single classifier is learned for multiple unlabeled target domains. To build a multi-target classifier, it is crucial to effectively aggregate features from the labeled source and different unlabeled target domains. Towards this, recently introduced Domain-aware Curriculum Graph Co-Teaching (D-CGCT) exploits dual classifier head, one of which is based on the graph neural network. D-CGCT uses a sequential adaptation strategy that adapts one domain at a time starting from the target domains that are more similar to the source, assuming that the network finds it easier to adapt to such target domains. However, we argue that there is no easier domain or difficult domain in absolute sense and each domain can have samples showing different characteristics. Following this cue, we propose Reiterative D-CGCT (RD-CGCT) that obtains better adaptation performance by reiterating multiple times over each target domain, while keeping the total number of iterations as same. RD-CGCT further improves the adaptation performance by considering more source samples than training samples in the training minibatch. Proposed RD-CGCT significantly improves the performance over D-CGCT for Office-Home and Office31 datasets.