 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientific Discovery by Generating Counterfactuals using Image Translation
Jul 10, 2020
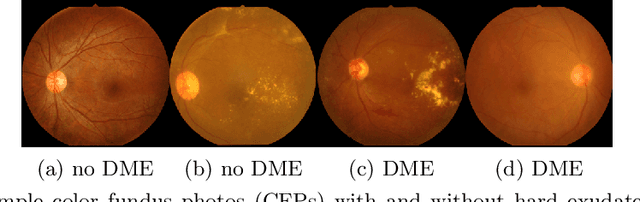
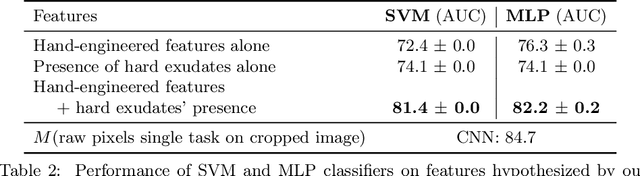
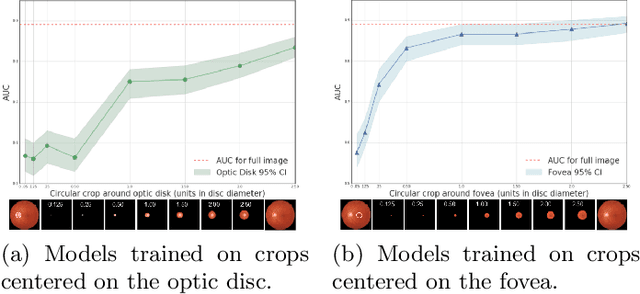
Model explanation techniques play a critical role in understanding the source of a model's performance and making its decisions transparent. Here we investigate if explanation techniques can also be used as a mechanism for scientific discovery. We make three contributions: first, we propose a framework to convert predictions from explanation techniques to a mechanism of discovery. Second, we show how generative models in combination with black-box predictors can be used to generate hypotheses (without human priors) that can be critically examined. Third, with these techniques we study classification models for retinal images predicting Diabetic Macular Edema (DME), where recent work showed that a CNN trained on these images is likely learning novel features in the image. We demonstrate that the proposed framework is able to explain the underlying scientific mechanism, thus bridging the gap between the model's performance and human understanding.
* Accepted at MICCAI 2020. This version combines camera-ready and supplement
Scaling Symbolic Methods using Gradients for Neural Model Explanation
Jun 29, 2020
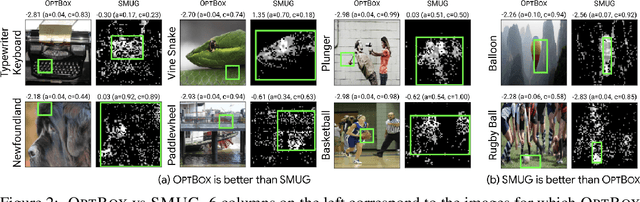
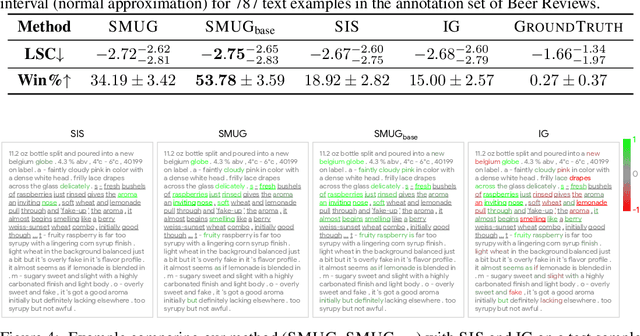

Symbolic techniques based on Satisfiability Modulo Theory (SMT) solvers have been proposed for analyzing and verifying neural network properties, but their usage has been fairly limited owing to their poor scalability with larger networks. In this work, we propose a technique for combining gradient-based methods with symbolic techniques to scale such analyses and demonstrate its application for model explanation. In particular, we apply this technique to identify minimal regions in an input that are most relevant for a neural network's prediction. Our approach uses gradient information (based on Integrated Gradients) to focus on a subset of neurons in the first layer, which allows our technique to scale to large networks. The corresponding SMT constraints encode the minimal input mask discovery problem such that after masking the input, the activations of the selected neurons are still above a threshold. After solving for the minimal masks, our approach scores the mask regions to generate a relative ordering of the features within the mask. This produces a saliency map which explains "where a model is looking" when making a prediction. We evaluate our technique on three datasets - MNIST, ImageNet, and Beer Reviews, and demonstrate both quantitatively and qualitatively that the regions generated by our approach are sparser and achieve higher saliency scores compared to the gradient-based methods alone.
Attribution in Scale and Space
Apr 08, 2020
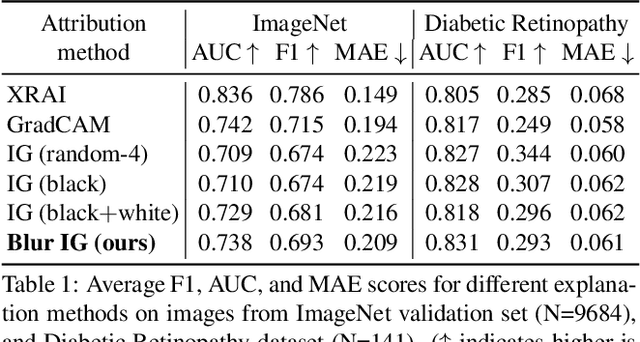
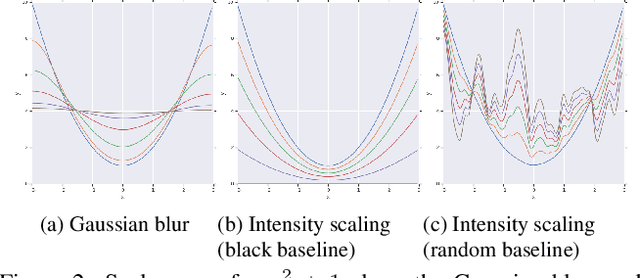
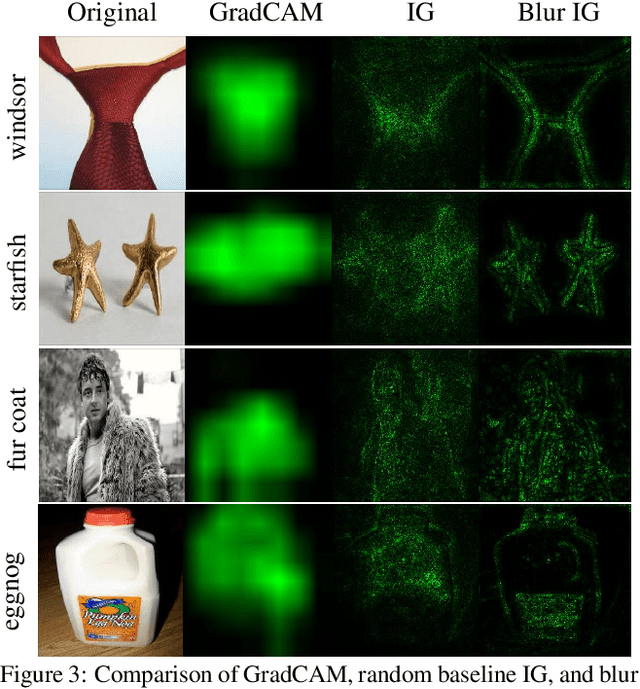
We study the attribution problem [28] for deep networks applied to perception tasks. For vision tasks, attribution techniques attribute the prediction of a network to the pixels of the input image. We propose a new technique called \emph{Blur Integrated Gradients}. This technique has several advantages over other methods. First, it can tell at what scale a network recognizes an object. It produces scores in the scale/frequency dimension, that we find captures interesting phenomena. Second, it satisfies the scale-space axioms [14], which imply that it employs perturbations that are free of artifact. We therefore produce explanations that are cleaner and consistent with the operation of deep networks. Third, it eliminates the need for a 'baseline' parameter for Integrated Gradients [31] for perception tasks. This is desirable because the choice of baseline has a significant effect on the explanations. We compare the proposed technique against previous techniques and demonstrate application on three tasks: ImageNet object recognition, Diabetic Retinopathy prediction, and AudioSet audio event identification.
It's easy to fool yourself: Case studies on identifying bias and confounding in bio-medical datasets
Dec 12, 2019
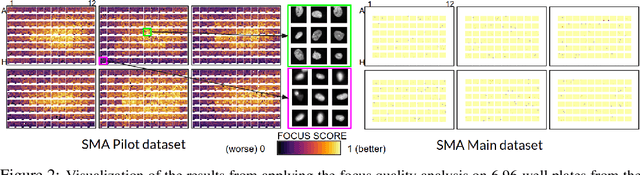
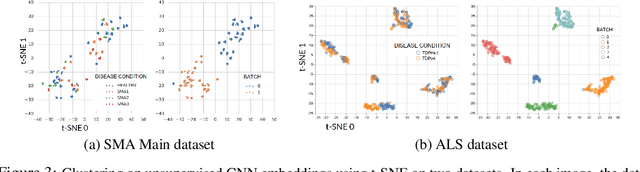
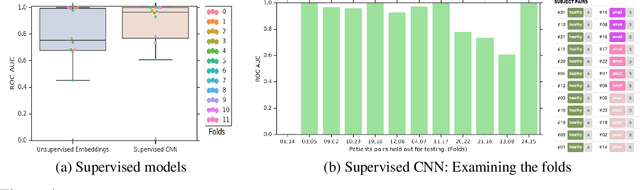
Confounding variables are a well known source of nuisance in biomedical studies. They present an even greater challenge when we combine them with black-box machine learning techniques that operate on raw data. This work presents two case studies. In one, we discovered biases arising from systematic errors in the data generation process. In the other, we found a spurious source of signal unrelated to the prediction task at hand. In both cases, our prediction models performed well but under careful examination hidden confounders and biases were revealed. These are cautionary tales on the limits of using machine learning techniques on raw data from scientific experiments.
Predicting optical coherence tomography-derived diabetic macular edema grades from fundus photographs using deep learning
Oct 18, 2018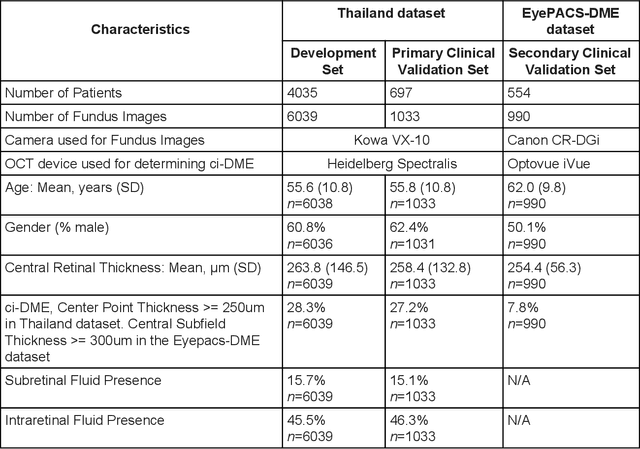
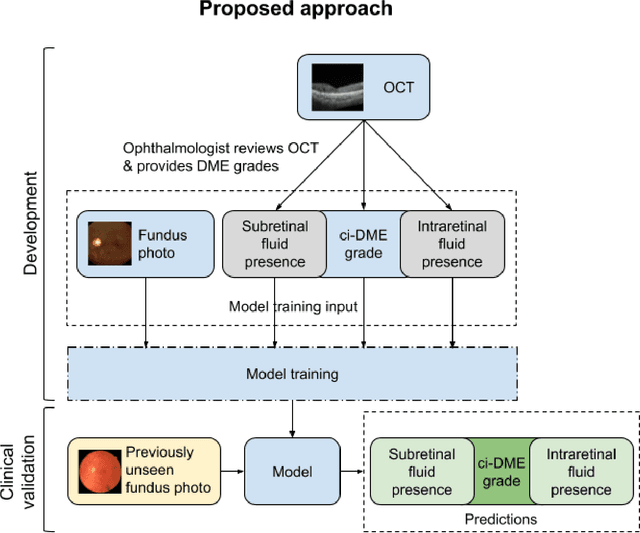
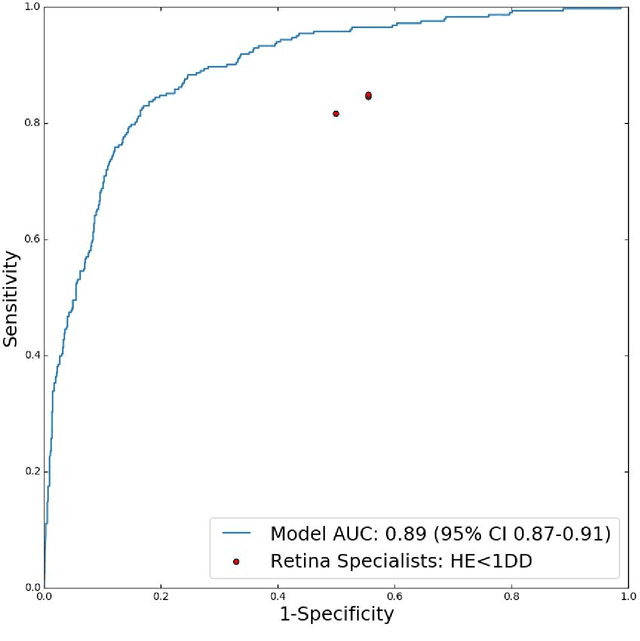
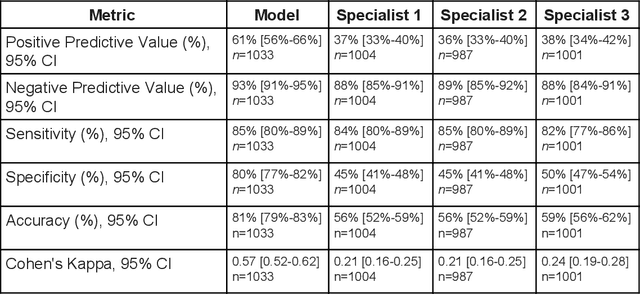
Diabetic eye disease is one of the fastest growing causes of preventable blindness. With the advent of anti-VEGF (vascular endothelial growth factor) therapies, it has become increasingly important to detect center-involved diabetic macular edema. However, center-involved diabetic macular edema is diagnosed using optical coherence tomography (OCT), which is not generally available at screening sites because of cost and workflow constraints. Instead, screening programs rely on the detection of hard exudates as a proxy for DME on color fundus photographs, often resulting in high false positive or false negative calls. To improve the accuracy of DME screening, we trained a deep learning model to use color fundus photographs to predict DME grades derived from OCT exams. Our "OCT-DME" model had an AUC of 0.89 (95% CI: 0.87-0.91), which corresponds to a sensitivity of 85% at a specificity of 80%. In comparison, three retinal specialists had similar sensitivities (82-85%), but only half the specificity (45-50%, p<0.001 for each comparison with model). The positive predictive value (PPV) of the OCT-DME model was 61% (95% CI: 56-66%), approximately double the 36-38% by the retina specialists. In addition, we used saliency and other techniques to examine how the model is making its prediction. The ability of deep learning algorithms to make clinically relevant predictions that generally require sophisticated 3D-imaging equipment from simple 2D images has broad relevance to many other applications in medical imaging.
Captioning Images with Diverse Objects
Jul 20, 2017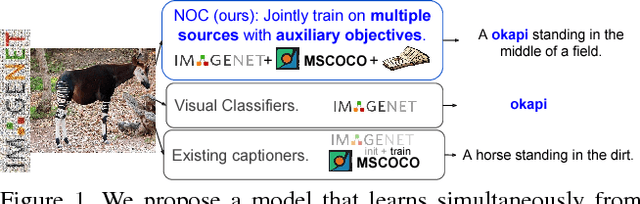

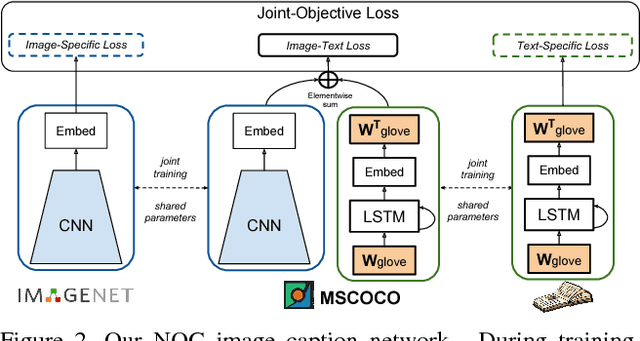
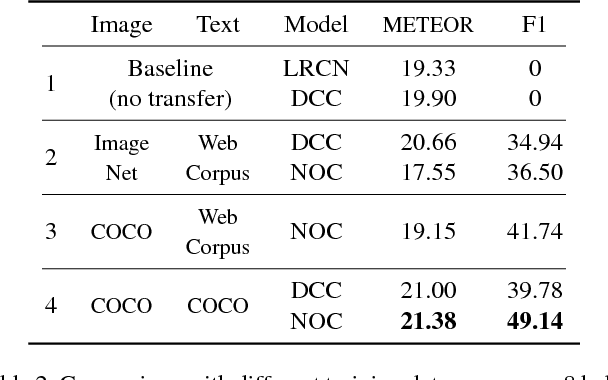
Recent captioning models are limited in their ability to scale and describe concepts unseen in paired image-text corpora. We propose the Novel Object Captioner (NOC), a deep visual semantic captioning model that can describe a large number of object categories not present in existing image-caption datasets. Our model takes advantage of external sources -- labeled images from object recognition datasets, and semantic knowledge extracted from unannotated text. We propose minimizing a joint objective which can learn from these diverse data sources and leverage distributional semantic embeddings, enabling the model to generalize and describe novel objects outside of image-caption datasets. We demonstrate that our model exploits semantic information to generate captions for hundreds of object categories in the ImageNet object recognition dataset that are not observed in MSCOCO image-caption training data, as well as many categories that are observed very rarely. Both automatic evaluations and human judgements show that our model considerably outperforms prior work in being able to describe many more categories of objects.
Detecting Cancer Metastases on Gigapixel Pathology Images
Mar 08, 2017
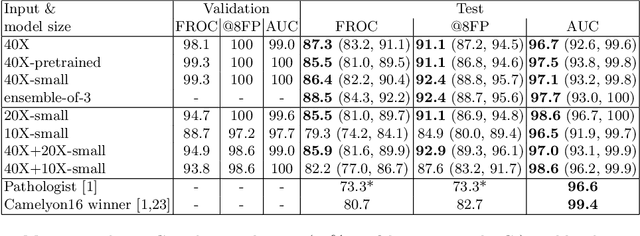
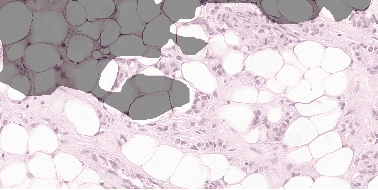
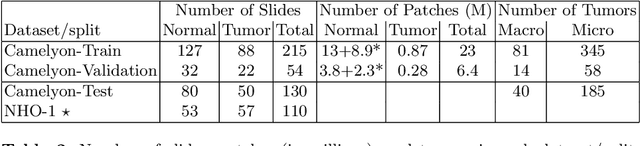
Each year, the treatment decisions for more than 230,000 breast cancer patients in the U.S. hinge on whether the cancer has metastasized away from the breast. Metastasis detection is currently performed by pathologists reviewing large expanses of biological tissues. This process is labor intensive and error-prone. We present a framework to automatically detect and localize tumors as small as 100 x 100 pixels in gigapixel microscopy images sized 100,000 x 100,000 pixels. Our method leverages a convolutional neural network (CNN) architecture and obtains state-of-the-art results on the Camelyon16 dataset in the challenging lesion-level tumor detection task. At 8 false positives per image, we detect 92.4% of the tumors, relative to 82.7% by the previous best automated approach. For comparison, a human pathologist attempting exhaustive search achieved 73.2% sensitivity. We achieve image-level AUC scores above 97% on both the Camelyon16 test set and an independent set of 110 slides. In addition, we discover that two slides in the Camelyon16 training set were erroneously labeled normal. Our approach could considerably reduce false negative rates in metastasis detection.
Improving LSTM-based Video Description with Linguistic Knowledge Mined from Text
Nov 29, 2016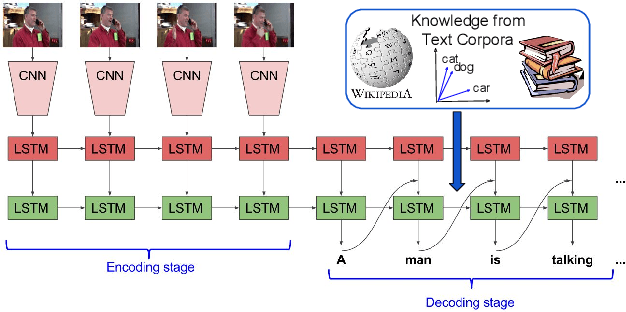
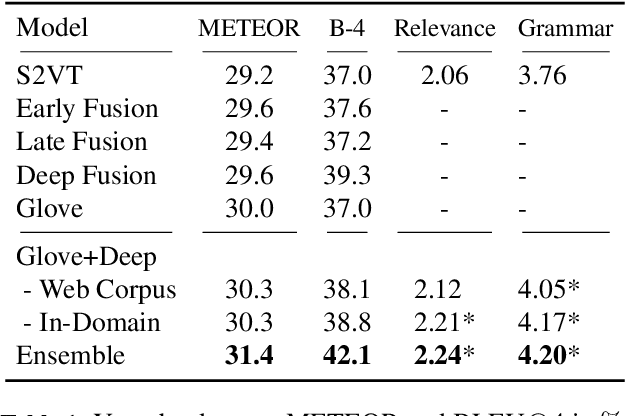
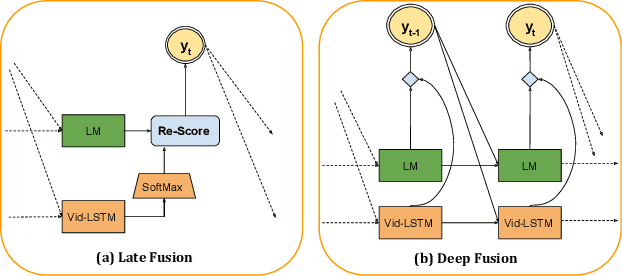
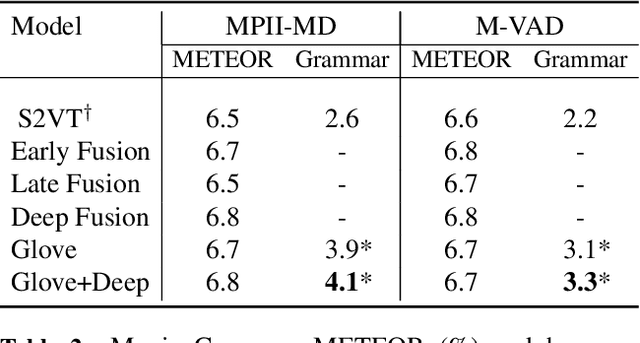
This paper investigates how linguistic knowledge mined from large text corpora can aid the generation of natural language descriptions of videos. Specifically, we integrate both a neural language model and distributional semantics trained on large text corpora into a recent LSTM-based architecture for video description. We evaluate our approach on a collection of Youtube videos as well as two large movie description datasets showing significant improvements in grammaticality while modestly improving descriptive quality.
* Accepted at EMNLP 2016. Project page: http://vsubhashini.github.io/language_fusion.html
Utilizing Large Scale Vision and Text Datasets for Image Segmentation from Referring Expressions
Aug 30, 2016
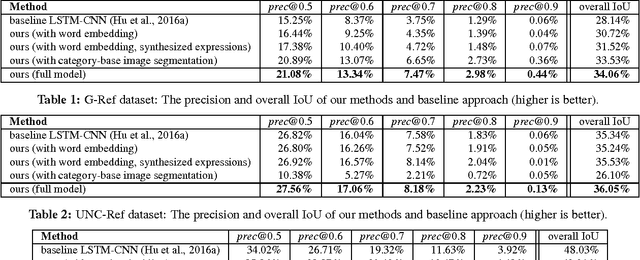
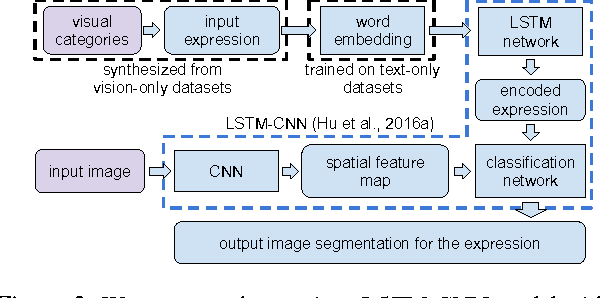
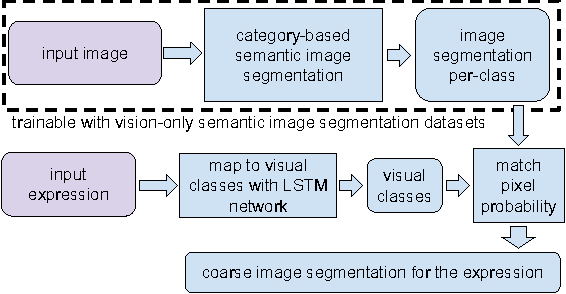
Image segmentation from referring expressions is a joint vision and language modeling task, where the input is an image and a textual expression describing a particular region in the image; and the goal is to localize and segment the specific image region based on the given expression. One major difficulty to train such language-based image segmentation systems is the lack of datasets with joint vision and text annotations. Although existing vision datasets such as MS COCO provide image captions, there are few datasets with region-level textual annotations for images, and these are often smaller in scale. In this paper, we explore how existing large scale vision-only and text-only datasets can be utilized to train models for image segmentation from referring expressions. We propose a method to address this problem, and show in experiments that our method can help this joint vision and language modeling task with vision-only and text-only data and outperforms previous results.
Long-term Recurrent Convolutional Networks for Visual Recognition and Description
May 31, 2016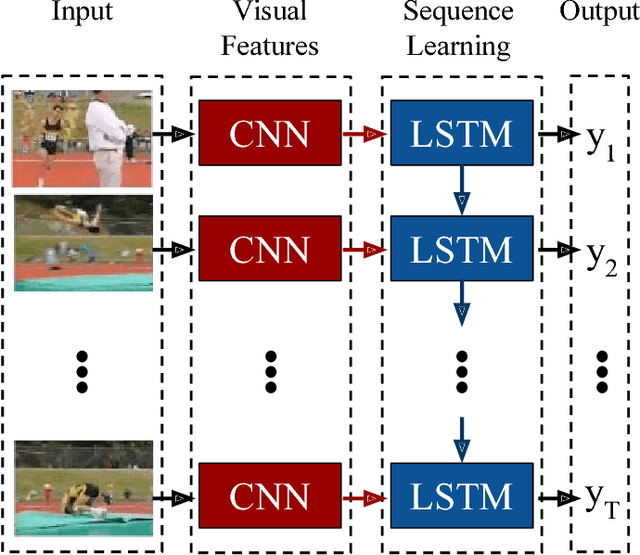

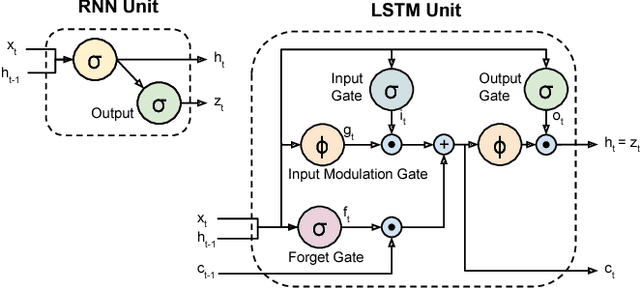
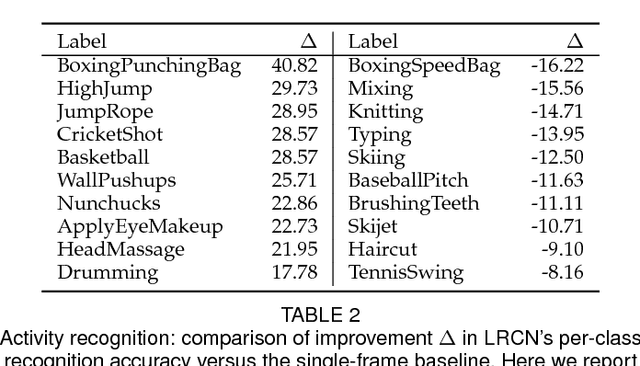
Models based on deep convolutional networks have dominated recent image interpretation tasks; we investigate whether models which are also recurrent, or "temporally deep", are effective for tasks involving sequences, visual and otherwise. We develop a novel recurrent convolutional architecture suitable for large-scale visual learning which is end-to-end trainable, and demonstrate the value of these models on benchmark video recognition tasks, image description and retrieval problems, and video narration challenges. In contrast to current models which assume a fixed spatio-temporal receptive field or simple temporal averaging for sequential processing, recurrent convolutional models are "doubly deep"' in that they can be compositional in spatial and temporal "layers". Such models may have advantages when target concepts are complex and/or training data are limited. Learning long-term dependencies is possible when nonlinearities are incorporated into the network state updates. Long-term RNN models are appealing in that they directly can map variable-length inputs (e.g., video frames) to variable length outputs (e.g., natural language text) and can model complex temporal dynamics; yet they can be optimized with backpropagation. Our recurrent long-term models are directly connected to modern visual convnet models and can be jointly trained to simultaneously learn temporal dynamics and convolutional perceptual representations. Our results show such models have distinct advantages over state-of-the-art models for recognition or generation which are separately defined and/or optimized.