 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Theoretical Understanding of the Robustness of Variational Autoencoders
Jul 14, 2020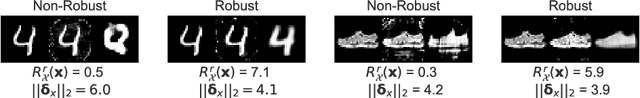

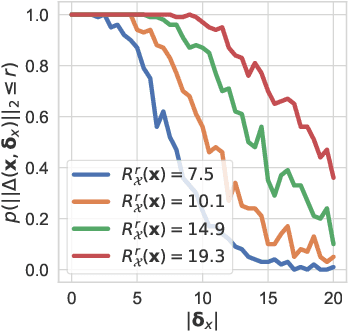
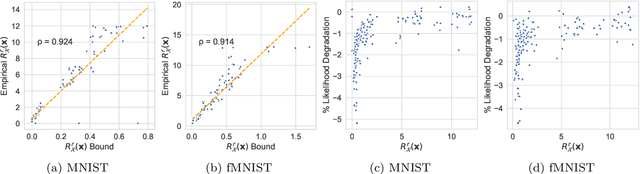
We make inroads into understanding the robustness of Variational Autoencoders (VAEs) to adversarial attacks and other input perturbations. While previous work has developed algorithmic approaches to attacking and defending VAEs, there remains a lack of formalization for what it means for a VAE to be robust. To address this, we develop a novel criterion for robustness in probabilistic models: $r$-robustness. We then use this to construct the first theoretical results for the robustness of VAEs, deriving margins in the input space for which we can provide guarantees about the resulting reconstruction. Informally, we are able to define a region within which any perturbation will produce a reconstruction that is similar to the original reconstruction. To support our analysis, we show that VAEs trained using disentangling methods not only score well under our robustness metrics, but that the reasons for this can be interpreted through our theoretical results.
Relaxed-Responsibility Hierarchical Discrete VAEs
Jul 14, 2020
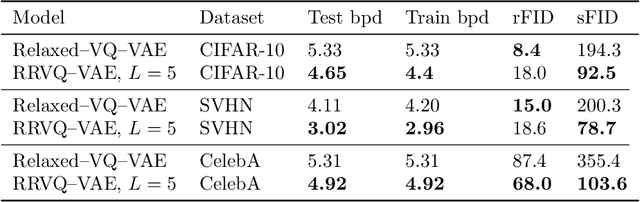
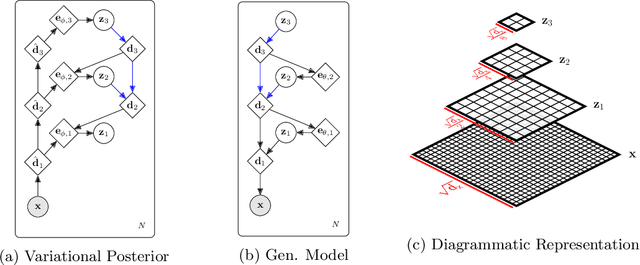

Successfully training Variational Autoencoders (VAEs) with a hierarchy of discrete latent variables remains an area of active research. Leveraging insights from classical methods of inference we introduce $\textit{Relaxed-Responsibility Vector-Quantisation}$, a novel way to parameterise discrete latent variables, a refinement of relaxed Vector-Quantisation. This enables a novel approach to hierarchical discrete variational autoencoder with numerous layers of latent variables that we train end-to-end. Unlike discrete VAEs with a single layer of latent variables, we can produce realistic-looking samples by ancestral sampling: it is not essential to train a second generative model over the learnt latent representations to then sample from and then decode. Further, we observe different layers of our model become associated with different aspects of the data.
On Optimism in Model-Based Reinforcement Learning
Jun 21, 2020
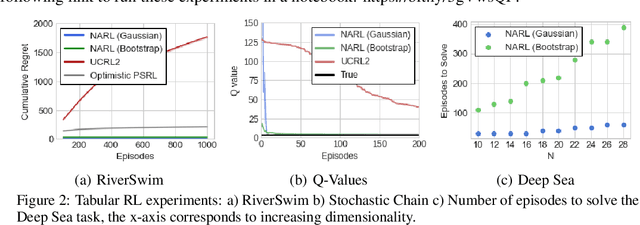
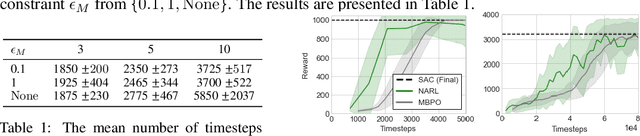
The principle of optimism in the face of uncertainty is prevalent throughout sequential decision making problems such as multi-armed bandits and reinforcement learning (RL), often coming with strong theoretical guarantees. However, it remains a challenge to scale these approaches to the deep RL paradigm, which has achieved a great deal of attention in recent years. In this paper, we introduce a tractable approach to optimism via noise augmented Markov Decision Processes (MDPs), which we show can obtain a competitive regret bound: $\tilde{\mathcal{O}}( |\mathcal{S}|H\sqrt{|\mathcal{S}||\mathcal{A}| T } )$ when augmenting using Gaussian noise, where $T$ is the total number of environment steps. This tractability allows us to apply our approach to the deep RL setting, where we rigorously evaluate the key factors for success of optimistic model-based RL algorithms, bridging the gap between theory and practice.
Deep Learning for Portfolio Optimisation
May 27, 2020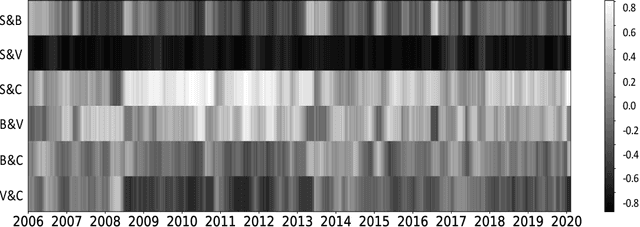
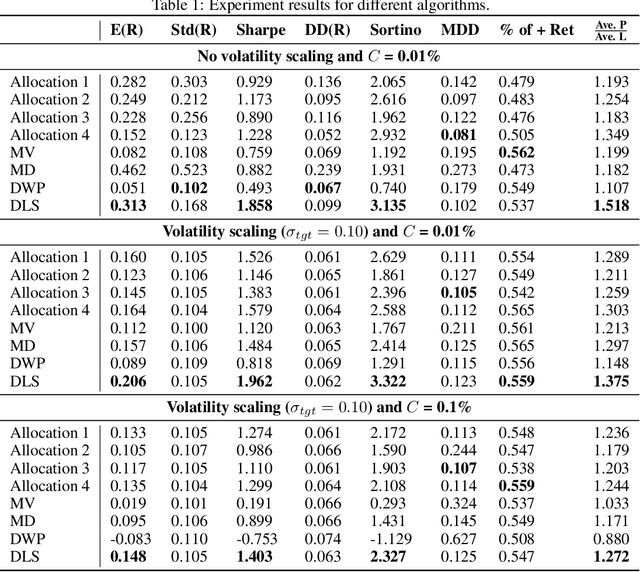
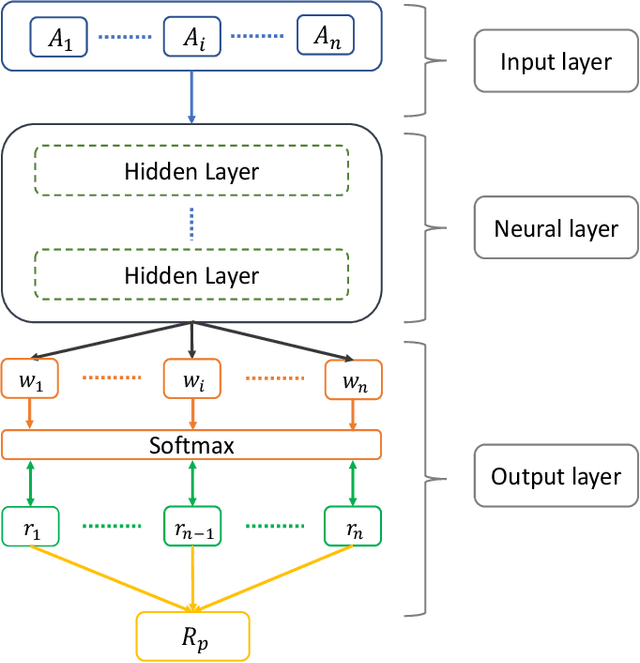
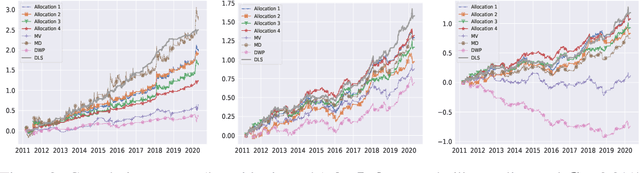
We adopt deep learning models to directly optimise the portfolio Sharpe ratio. The framework we present circumvents the requirements for forecasting expected returns and allows us to directly optimise portfolio weights by updating model parameters. Instead of selecting individual assets, we trade Exchange-Traded Funds (ETFs) of market indices to form a portfolio. Indices of different asset classes show robust correlations and trading them substantially reduces the spectrum of available assets to choose from. We compare our method with a wide range of algorithms with results showing that our model obtains the best performance over the testing period, from 2011 to the end of April 2020, including the financial instabilities of the first quarter of 2020. A sensitivity analysis is included to understand the relevance of input features and we further study the performance of our approach under different cost rates and different risk levels via volatility scaling.
VIGN: Variational Integrator Graph Networks
Apr 28, 2020
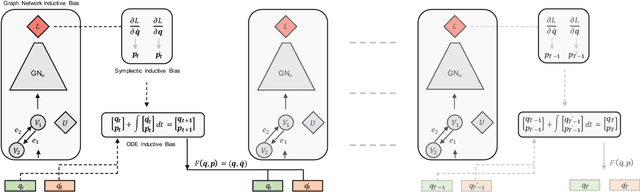
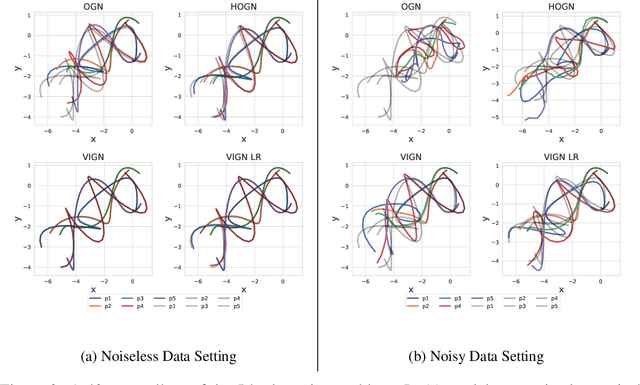
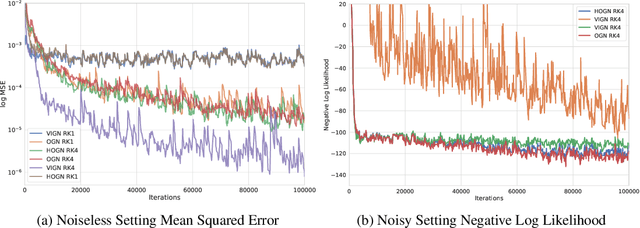
Rich, physically-informed inductive biases play an imperative role in accurately modelling the time dynamics of physical systems. In this paper, we introduce Variational Integrator Graph Networks (VIGNs), the first approach to combine a Variational Integrator (VI) inductive bias with a Graph Network (GN) and demonstrate an order of magnitude improvement in performance, both in terms of data-efficient learning and predictive accuracy, over existing methods. We show that this improvement arises because VIs induce coupled learning of generalized position and momentum updates which can be formulated as a Partitioned Runge-Kutta (PRK) method. We empirically establish that VIGN outperforms numerous methods in learning from existing datasets with noise.
Mixture Density Conditional Generative Adversarial Network Models (MD-CGAN)
Apr 08, 2020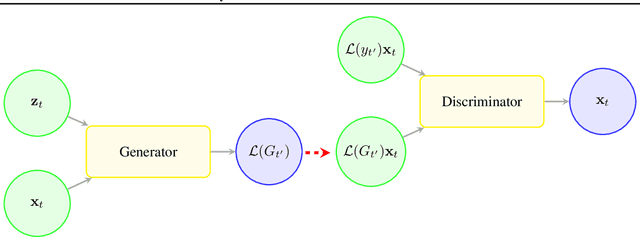
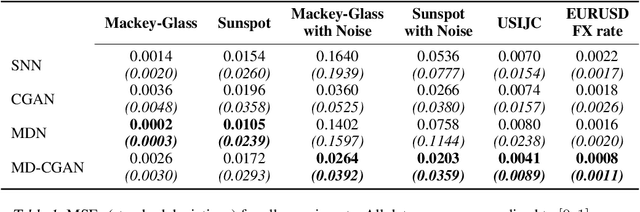
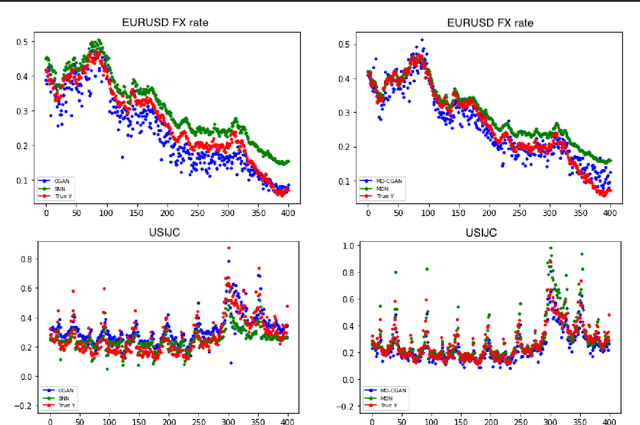
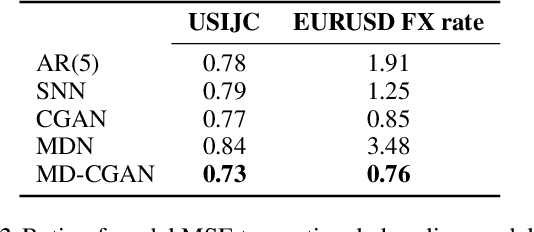
Generative Adversarial Networks (GANs) have gained significant attention in recent years, with particularly impressive applications highlighted in computer vision. In this work, we present a Mixture Density Conditional Generative Adversarial Model (MD-CGAN), where the generator is a Gaussian mixture model, with a focus on time series forecasting. Compared to examples in vision, there have been more limited applications of GAN models to time series. We show that our model is capable of estimating a probabilistic posterior distribution over forecasts and that, in comparison to a set of benchmark methods, the MD-CGAN model performs well, particularly in situations where noise is a significant in the time series. Further, by using a Gaussian mixture model that allows for a flexible number of mixture coefficients, the MD-CGAN offers posterior distributions that are non-Gaussian.
Iterate Averaging Helps: An Alternative Perspective in Deep Learning
Mar 02, 2020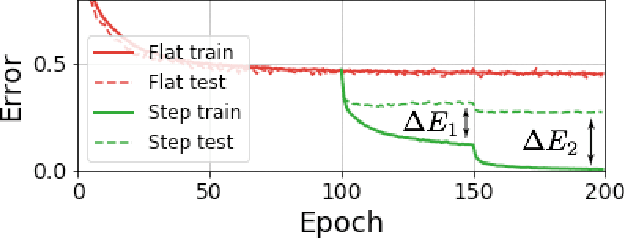

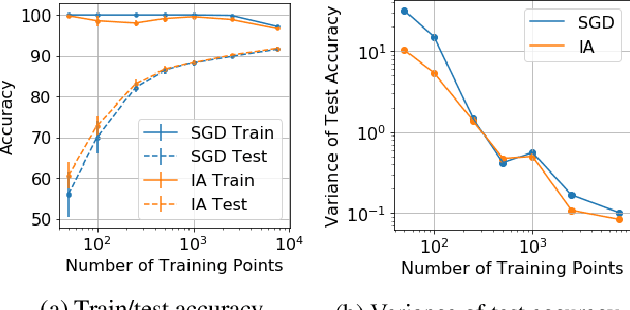
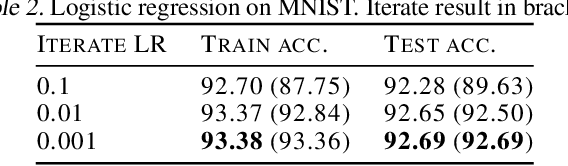
Iterate averaging has a rich history in optimisation, but has only very recently been popularised in deep learning. We investigate its effects in a deep learning context, and argue that previous explanations on its efficacy, which place a high importance on the local geometry (flatness vs sharpness) of final solutions, are not necessarily relevant. We instead argue that the robustness of iterate averaging towards the typically very high estimation noise in deep learning and the various regularisation effects averaging exert, are the key reasons for the performance gain, indeed this effect is made even more prominent due to the over-parameterisation of modern networks. Inspired by this, we propose Gadam, which combines Adam with iterate averaging to address one of key problems of adaptive optimisers that they often generalise worse. Without compromising adaptivity and with minimal additional computational burden, we show that Gadam (and its variant GadamX) achieve a generalisation performance that is consistently superior to tuned SGD and is even on par or better compared to SGD with iterate averaging on various image classification (CIFAR 10/100 and ImageNet 32$\times$32) and language tasks (PTB).
Learning Bijective Feature Maps for Linear ICA
Feb 19, 2020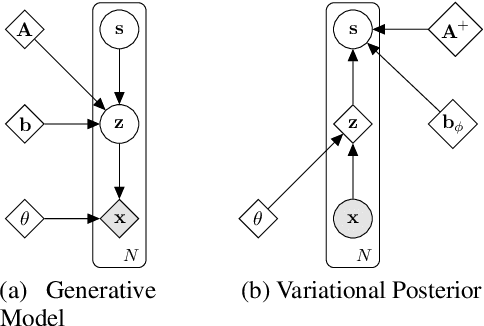
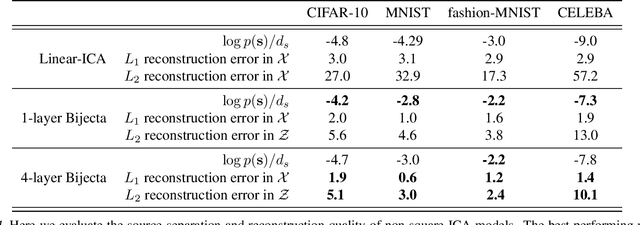

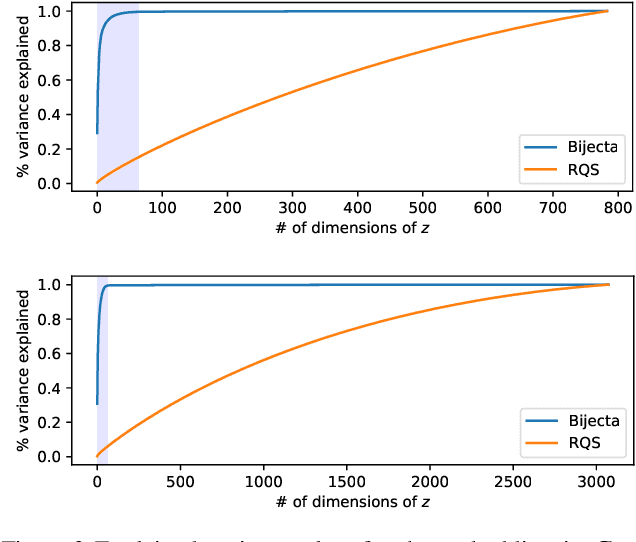
Separating high-dimensional data like images into independent latent factors remains an open research problem. Here we develop a method that jointly learns a linear independent component analysis (ICA) model with non-linear bijective feature maps. By combining these two methods, ICA can learn interpretable latent structure for images. For non-square ICA, where we assume the number of sources is less than the dimensionality of data, we achieve better unsupervised latent factor discovery than flow-based models and linear ICA. This performance scales to large image datasets such as CelebA.
HumBug Zooniverse: a crowd-sourced acoustic mosquito dataset
Feb 14, 2020
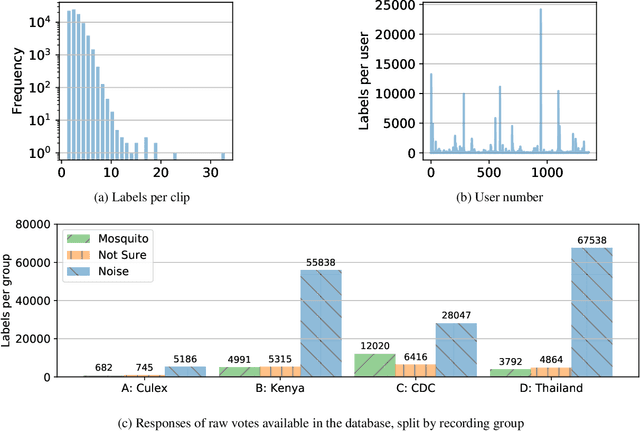
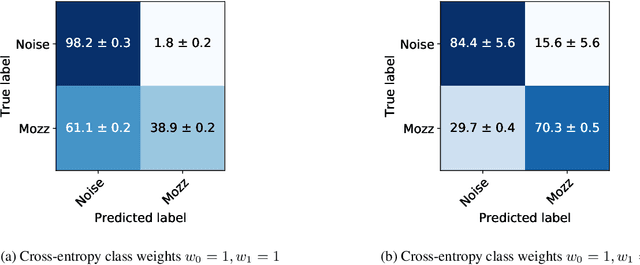
Mosquitoes are the only known vector of malaria, which leads to hundreds of thousands of deaths each year. Understanding the number and location of potential mosquito vectors is of paramount importance to aid the reduction of malaria transmission cases. In recent years, deep learning has become widely used for bioacoustic classification tasks. In order to enable further research applications in this field, we release a new dataset of mosquito audio recordings. With over a thousand contributors, we obtained 195,434 labels of two second duration, of which approximately 10 percent signify mosquito events. We present an example use of the dataset, in which we train a convolutional neural network on log-Mel features, showcasing the information content of the labels. We hope this will become a vital resource for those researching all aspects of malaria, and add to the existing audio datasets for bioacoustic detection and signal processing.
Ready Policy One: World Building Through Active Learning
Feb 07, 2020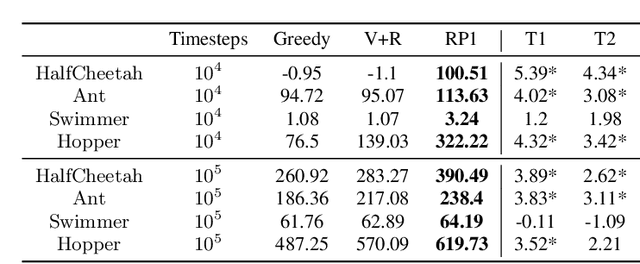
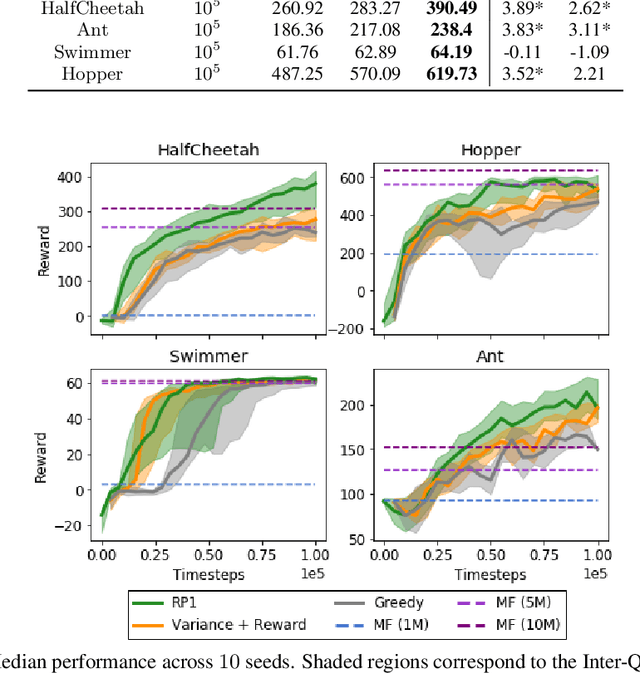
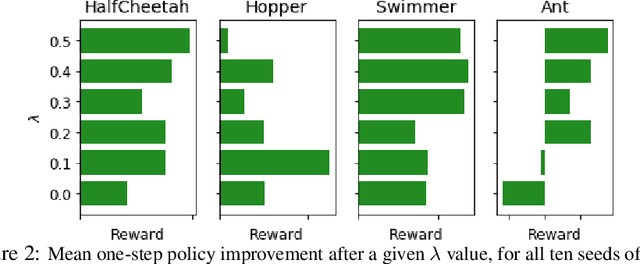

Model-Based Reinforcement Learning (MBRL) offers a promising direction for sample efficient learning, often achieving state of the art results for continuous control tasks. However, many existing MBRL methods rely on combining greedy policies with exploration heuristics, and even those which utilize principled exploration bonuses construct dual objectives in an ad hoc fashion. In this paper we introduce Ready Policy One (RP1), a framework that views MBRL as an active learning problem, where we aim to improve the world model in the fewest samples possible. RP1 achieves this by utilizing a hybrid objective function, which crucially adapts during optimization, allowing the algorithm to trade off reward v.s. exploration at different stages of learning. In addition, we introduce a principled mechanism to terminate sample collection once we have a rich enough trajectory batch to improve the model. We rigorously evaluate our method on a variety of continuous control tasks, and demonstrate statistically significant gains over existing approaches.