 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Life Gives You BC, Make Q-functions: Extracting Q-values from Behavior Cloning for On-Robot Reinforcement Learning
May 06, 2026Behavior Cloning (BC) has emerged as a highly effective paradigm for robot learning. However, BC lacks a self-guided mechanism for online improvement after demonstrations have been collected. Existing offline-to-online learning methods often cause policies to replace previously learned good actions due to a distribution mismatch between offline data and online learning. In this work, we propose Q2RL, Q-Estimation and Q-Gating from BC for Reinforcement Learning, an algorithm for efficient offline-to-online learning. Our method consists of two parts: (1) Q-Estimation extracts a Q-function from a BC policy using a few interaction steps with the environment, followed by online RL with (2) Q-Gating, which switches between BC and RL policy actions based on their respective Q-values to collect samples for RL policy training. Across manipulation tasks from D4RL and robomimic benchmarks, Q2RL outperforms SOTA offline-to-online learning baselines on success rate and time to convergence. Q2RL is efficient enough to be applied in an on-robot RL setting, learning robust policies for contact-rich and high precision manipulation tasks such as pipe assembly and kitting, in 1-2 hours of online interaction, achieving success rates of up to 100% and up to 3.75x improvement against the original BC policy. Code and video are available at https://pages.rai-inst.com/q2rl_website/
SOLE-R1: Video-Language Reasoning as the Sole Reward for On-Robot Reinforcement Learning
Mar 30, 2026Vision-language models (VLMs) have shown impressive capabilities across diverse tasks, motivating efforts to leverage these models to supervise robot learning. However, when used as evaluators in reinforcement learning (RL), today's strongest models often fail under partial observability and distribution shift, enabling policies to exploit perceptual errors rather than solve the task. To address this limitation, we introduce SOLE-R1 (Self-Observing LEarner), a video-language reasoning model explicitly designed to serve as the sole reward signal for online RL. Given only raw video observations and a natural-language goal, SOLE-R1 performs per-timestep spatiotemporal chain-of-thought (CoT) reasoning and produces dense estimates of task progress that can be used directly as rewards. To train SOLE-R1, we develop a large-scale video trajectory and reasoning synthesis pipeline that generates temporally grounded CoT traces aligned with continuous progress supervision. This data is combined with foundational spatial and multi-frame temporal reasoning, and used to train the model with a hybrid framework that couples supervised fine-tuning with RL from verifiable rewards. Across four different simulation environments and a real-robot setting, SOLE-R1 enables zero-shot online RL from random initialization: robots learn previously unseen manipulation tasks without ground-truth rewards, success indicators, demonstrations, or task-specific tuning. SOLE-R1 succeeds on 24 unseen tasks and substantially outperforms strong vision-language rewarders, including GPT-5 and Gemini-3-Pro, while exhibiting markedly greater robustness to reward hacking.
Equivariant Diffusion Policy
Jul 01, 2024



Recent work has shown diffusion models are an effective approach to learning the multimodal distributions arising from demonstration data in behavior cloning. However, a drawback of this approach is the need to learn a denoising function, which is significantly more complex than learning an explicit policy. In this work, we propose Equivariant Diffusion Policy, a novel diffusion policy learning method that leverages domain symmetries to obtain better sample efficiency and generalization in the denoising function. We theoretically analyze the $\mathrm{SO}(2)$ symmetry of full 6-DoF control and characterize when a diffusion model is $\mathrm{SO}(2)$-equivariant. We furthermore evaluate the method empirically on a set of 12 simulation tasks in MimicGen, and show that it obtains a success rate that is, on average, 21.9% higher than the baseline Diffusion Policy. We also evaluate the method on a real-world system to show that effective policies can be learned with relatively few training samples, whereas the baseline Diffusion Policy cannot.
ADAMANT: A Pipeline for Adaptable Manipulation Tasks
Sep 14, 2022
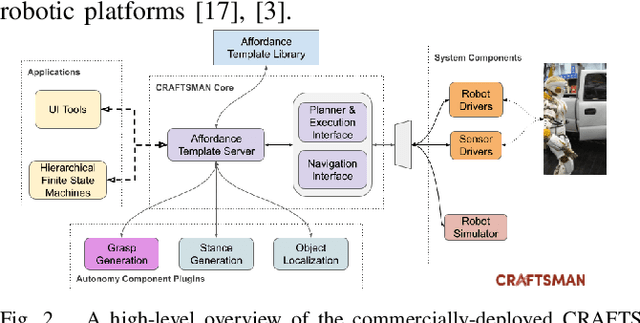

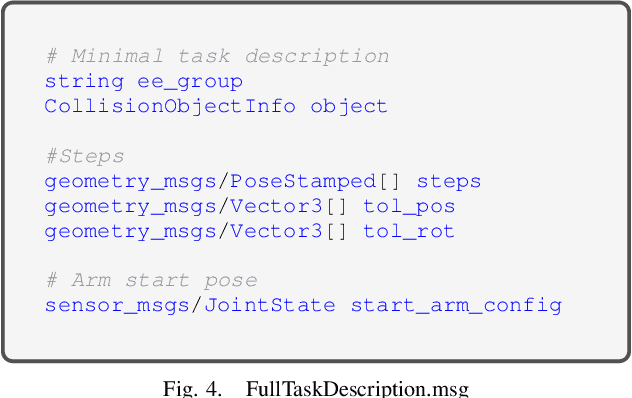
This paper presents ADAMANT, a set of software modules that provides grasp planning capabilities to an existing robot planning and control software framework. Our presented work allows a user to adapt a manipulation task to be used under widely different scenarios with minimal user input, thus reducing the operator's cognitive load. The developed tools include (1) plugin-based components that make it easy to extend default capabilities and to use third-party grasp libraries, (2) An object-centric way to define task constraints, (3) A user-friendly Rviz interface to use the grasp planner utilities, and (4) Interactive tools to use perception data to program a task. We tested our framework on a wide variety of robot simulations.
Deploying the NASA Valkyrie Humanoid for IED Response: An Initial Approach and Evaluation Summary
Oct 02, 2019



As part of a feasibility study, this paper shows the NASA Valkyrie humanoid robot performing an end-to-end improvised explosive device (IED) response task. To demonstrate and evaluate robot capabilities, sub-tasks highlight different locomotion, manipulation, and perception requirements: traversing uneven terrain, passing through a narrow passageway, opening a car door, retrieving a suspected IED, and securing the IED in a total containment vessel (TCV). For each sub-task, a description of the technical approach and the hidden challenges that were overcome during development are presented. The discussion of results, which explicitly includes existing limitations, is aimed at motivating continued research and development to enable practical deployment of humanoid robots for IED response. For instance, the data shows that operator pauses contribute to 50\% of the total completion time, which implies that further work is needed on user interfaces for increasing task completion efficiency.