 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Stochastic Gradient MCMC
Jul 19, 2021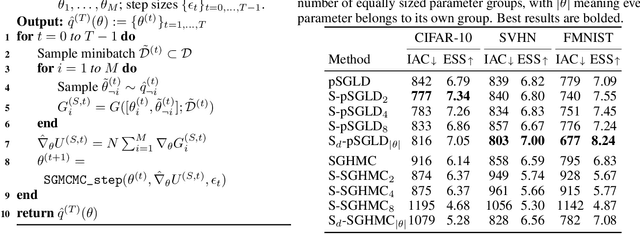
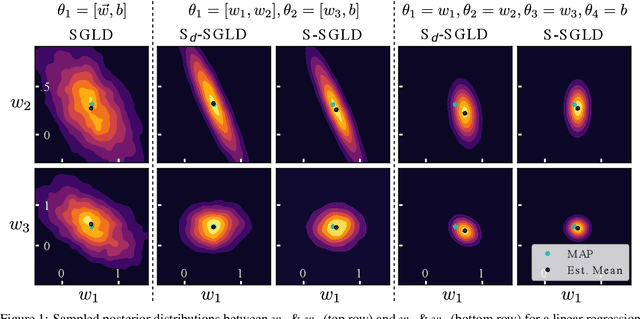

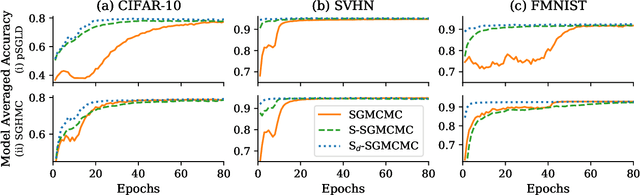
Stochastic gradient Markov chain Monte Carlo (SGMCMC) is considered the gold standard for Bayesian inference in large-scale models, such as Bayesian neural networks. Since practitioners face speed versus accuracy tradeoffs in these models, variational inference (VI) is often the preferable option. Unfortunately, VI makes strong assumptions on both the factorization and functional form of the posterior. In this work, we propose a new non-parametric variational approximation that makes no assumptions about the approximate posterior's functional form and allows practitioners to specify the exact dependencies the algorithm should respect or break. The approach relies on a new Langevin-type algorithm that operates on a modified energy function, where parts of the latent variables are averaged over samples from earlier iterations of the Markov chain. This way, statistical dependencies can be broken in a controlled way, allowing the chain to mix faster. This scheme can be further modified in a ''dropout'' manner, leading to even more scalability. By implementing the scheme on a ResNet-20 architecture, we obtain better predictive likelihoods and larger effective sample sizes than full SGMCMC.
Neural Transformation Learning for Deep Anomaly Detection Beyond Images
Mar 31, 2021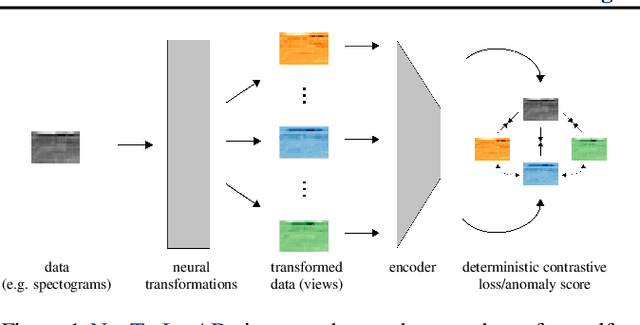

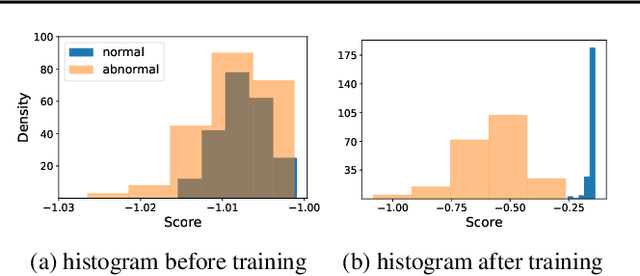
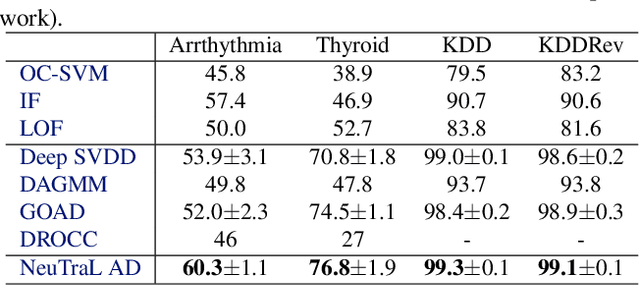
Data transformations (e.g. rotations, reflections, and cropping) play an important role in self-supervised learning. Typically, images are transformed into different views, and neural networks trained on tasks involving these views produce useful feature representations for downstream tasks, including anomaly detection. However, for anomaly detection beyond image data, it is often unclear which transformations to use. Here we present a simple end-to-end procedure for anomaly detection with learnable transformations. The key idea is to embed the transformed data into a semantic space such that the transformed data still resemble their untransformed form, while different transformations are easily distinguishable. Extensive experiments on time series demonstrate that we significantly outperform existing methods on the one-vs.-rest setting but also on the more challenging n-vs.-rest anomaly-detection task. On tabular datasets from the medical and cyber-security domains, our method learns domain-specific transformations and detects anomalies more accurately than previous work.
Variational Beam Search for Online Learning with Distribution Shifts
Dec 15, 2020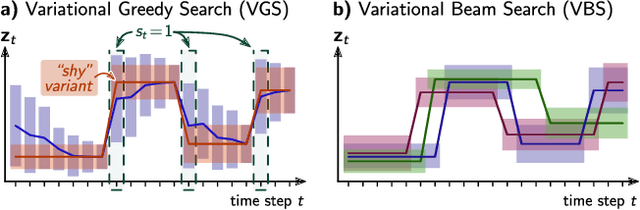
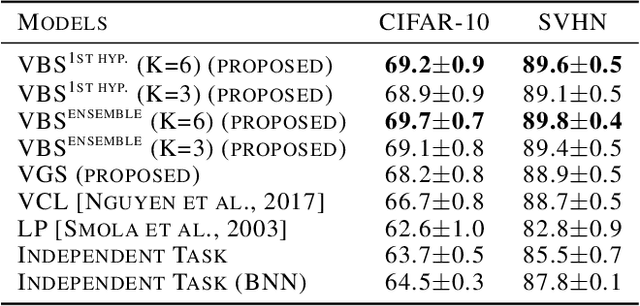
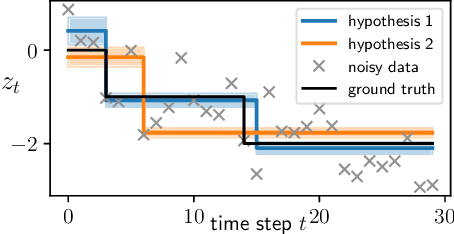
We consider the problem of online learning in the presence of sudden distribution shifts as frequently encountered in applications such as autonomous navigation. Distribution shifts require constant performance monitoring and re-training. They may also be hard to detect and can lead to a slow but steady degradation in model performance. To address this problem we propose a new Bayesian meta-algorithm that can both (i) make inferences about subtle distribution shifts based on minimal sequential observations and (ii) accordingly adapt a model in an online fashion. The approach uses beam search over multiple change point hypotheses to perform inference on a hierarchical sequential latent variable modeling framework. Our proposed approach is model-agnostic, applicable to both supervised and unsupervised learning, and yields significant improvements over state-of-the-art Bayesian online learning approaches.
Scalable Gaussian Process Variational Autoencoders
Nov 12, 2020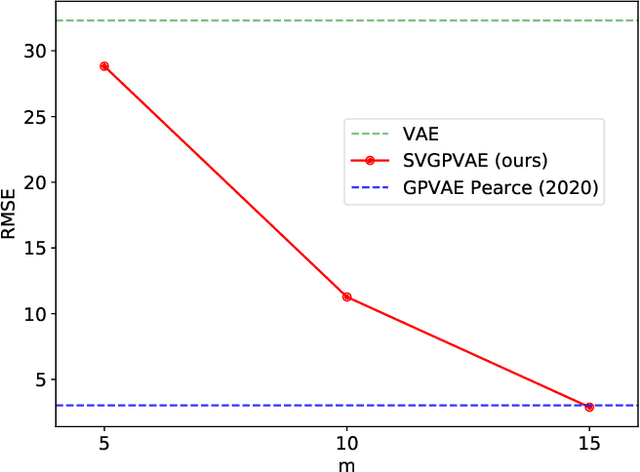

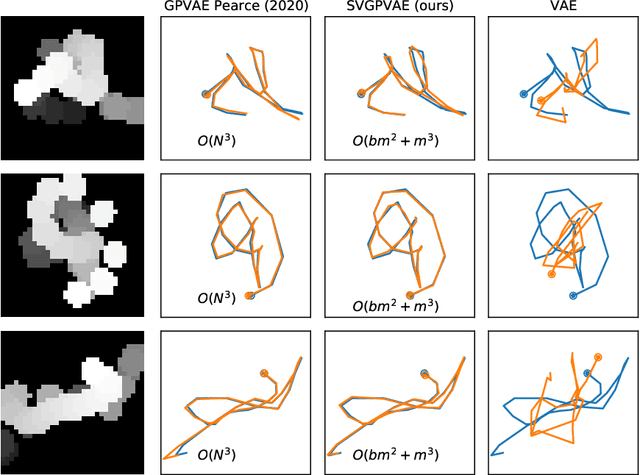
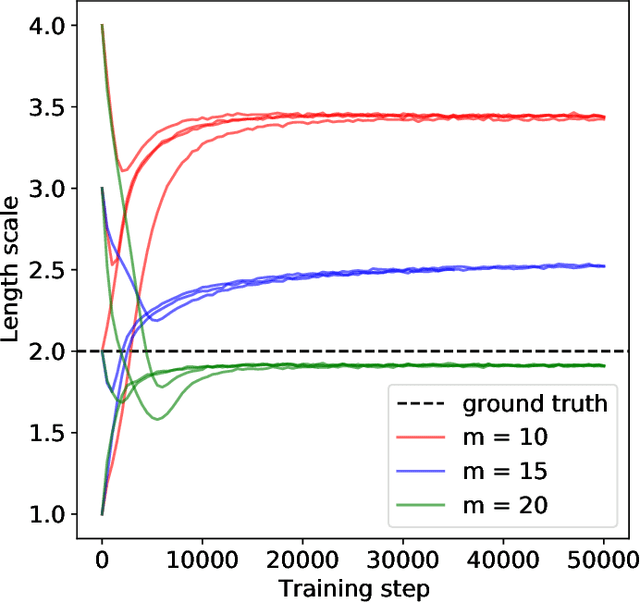
Conventional variational autoencoders fail in modeling correlations between data points due to their use of factorized priors. Amortized Gaussian process inference through GP-VAEs has led to significant improvements in this regard, but is still inhibited by the intrinsic complexity of exact GP inference. We improve the scalability of these methods through principled sparse inference approaches. We propose a new scalable GP-VAE model that outperforms existing approaches in terms of runtime and memory footprint, is easy to implement, and allows for joint end-to-end optimization of all components.
User-Dependent Neural Sequence Models for Continuous-Time Event Data
Nov 06, 2020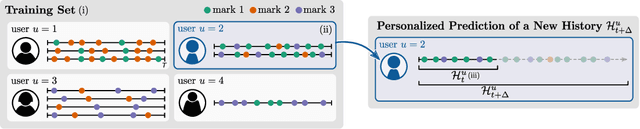
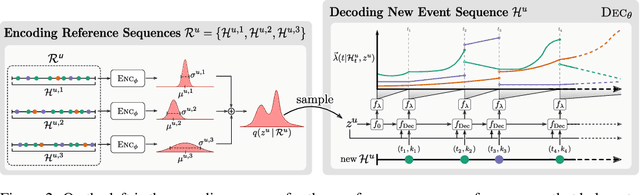

Continuous-time event data are common in applications such as individual behavior data, financial transactions, and medical health records. Modeling such data can be very challenging, in particular for applications with many different types of events, since it requires a model to predict the event types as well as the time of occurrence. Recurrent neural networks that parameterize time-varying intensity functions are the current state-of-the-art for predictive modeling with such data. These models typically assume that all event sequences come from the same data distribution. However, in many applications event sequences are generated by different sources, or users, and their characteristics can be very different. In this paper, we extend the broad class of neural marked point process models to mixtures of latent embeddings, where each mixture component models the characteristic traits of a given user. Our approach relies on augmenting these models with a latent variable that encodes user characteristics, represented by a mixture model over user behavior that is trained via amortized variational inference. We evaluate our methods on four large real-world datasets and demonstrate systematic improvements from our approach over existing work for a variety of predictive metrics such as log-likelihood, next event ranking, and source-of-sequence identification.
Variational Dynamic Mixtures
Oct 20, 2020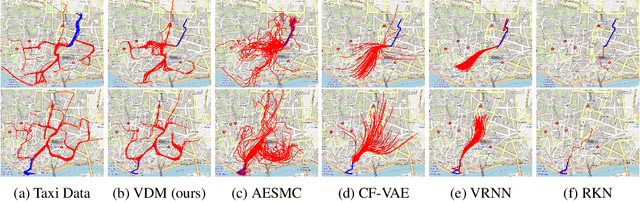
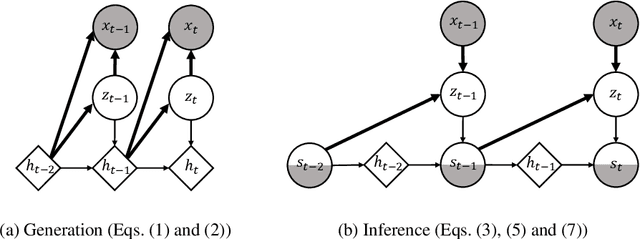


Deep probabilistic time series forecasting models have become an integral part of machine learning. While several powerful generative models have been proposed, we provide evidence that their associated inference models are oftentimes too limited and cause the generative model to predict mode-averaged dynamics. Modeaveraging is problematic since many real-world sequences are highly multi-modal, and their averaged dynamics are unphysical (e.g., predicted taxi trajectories might run through buildings on the street map). To better capture multi-modality, we develop variational dynamic mixtures (VDM): a new variational family to infer sequential latent variables. The VDM approximate posterior at each time step is a mixture density network, whose parameters come from propagating multiple samples through a recurrent architecture. This results in an expressive multi-modal posterior approximation. In an empirical study, we show that VDM outperforms competing approaches on highly multi-modal datasets from different domains.
Hierarchical Autoregressive Modeling for Neural Video Compression
Oct 19, 2020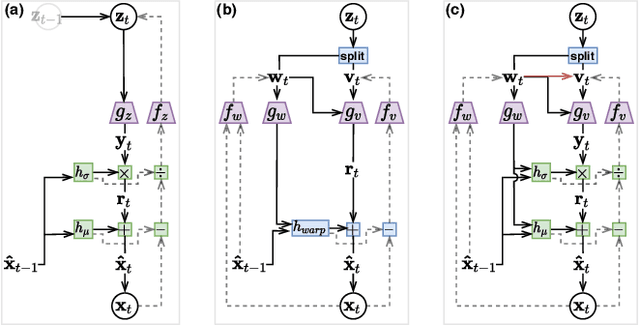


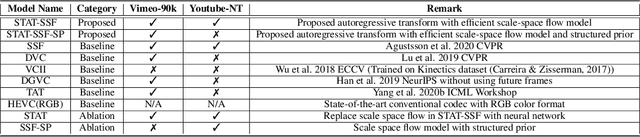
Recent work by Marino et al. (2020) showed improved performance in sequential density estimation by combining masked autoregressive flows with hierarchical latent variable models. We draw a connection between such autoregressive generative models and the task of lossy video compression. Specifically, we view recent neural video compression methods (Lu et al., 2019; Yang et al., 2020b; Agustssonet al., 2020) as instances of a generalized stochastic temporal autoregressive trans-form, and propose avenues for enhancement based on this insight. Comprehensive evaluations on large-scale video data show improved rate-distortion performance over both state-of-the-art neural and conventional video compression methods.
Improving Sequential Latent Variable Models with Autoregressive Flows
Oct 07, 2020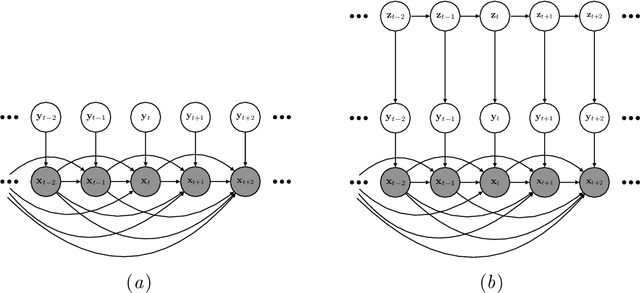
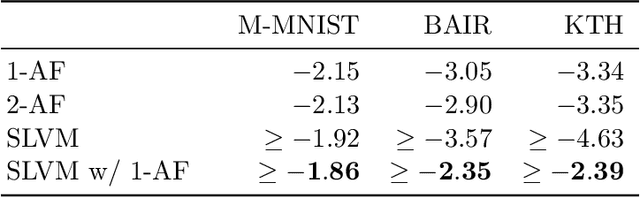


We propose an approach for improving sequence modeling based on autoregressive normalizing flows. Each autoregressive transform, acting across time, serves as a moving frame of reference, removing temporal correlations, and simplifying the modeling of higher-level dynamics. This technique provides a simple, general-purpose method for improving sequence modeling, with connections to existing and classical techniques. We demonstrate the proposed approach both with standalone flow-based models and as a component within sequential latent variable models. Results are presented on three benchmark video datasets, where autoregressive flow-based dynamics improve log-likelihood performance over baseline models. Finally, we illustrate the decorrelation and improved generalization properties of using flow-based dynamics.
Generative Modeling for Atmospheric Convection
Jul 03, 2020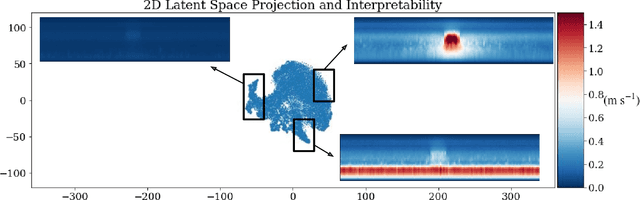
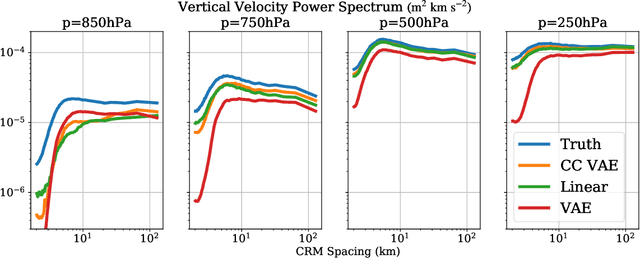
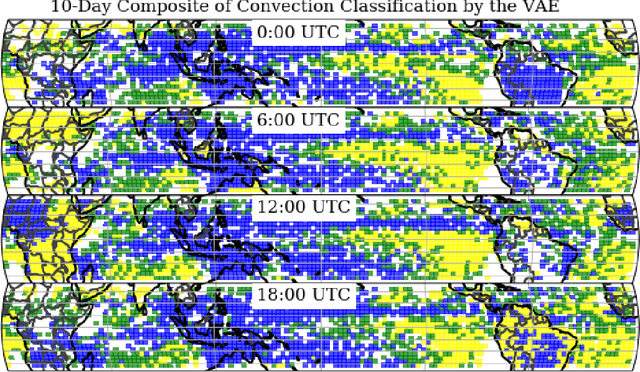
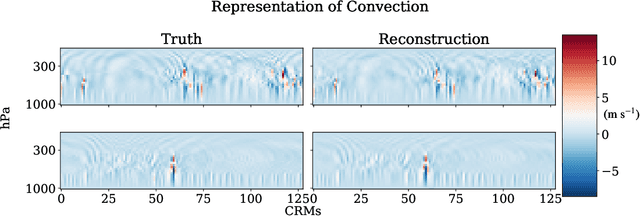
To improve climate modeling, we need a better understanding of multi-scale atmospheric dynamics--the relationship between large scale environment and small-scale storm formation, morphology and propagation--as well as superior stochastic parameterization of convective organization. We analyze raw output from ~6 million instances of explicitly simulated convection spanning all global geographic regimes of convection in the tropics, focusing on the vertical velocities extracted every 15 minutes from ~4 hundred thousands separate instances of a storm-permitting moist turbulence model embedded within a multi-scale global model of the atmosphere. Generative modeling techniques applied on high-resolution climate data for representation learning hold the potential to drive next-generation parameterization and breakthroughs in understanding of convection and storm development. To that end, we design and implement a specialized Variational Autoencoder (VAE) to perform structural replication, dimensionality reduction and clustering on these cloud-resolving vertical velocity outputs. Our VAE reproduces the structure of disparate classes of convection, successfully capturing both their magnitude and variances. This VAE thus provides a novel way to perform unsupervised grouping of convective organization in multi-scale simulations of the atmosphere in a physically sensible manner. The success of our VAE in structural emulation, learning physical meaning in convective transitions and anomalous vertical velocity field detection may help set the stage for developing generative models for stochastic parameterization that might one day replace explicit convection calculations.
Improving Inference for Neural Image Compression
Jun 09, 2020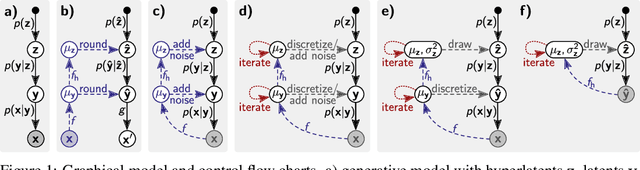


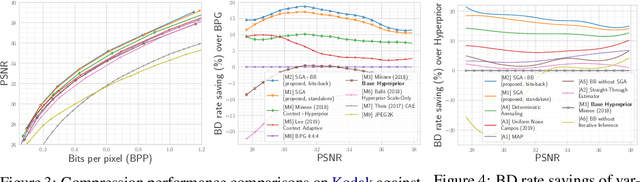
We consider the problem of lossy image compression with deep latent variable models. State-of-the-art methods build on hierarchical variational autoencoders (VAEs) and learn inference networks to predict a compressible latent representation of each data point. Drawing on the variational inference perspective on compression, we identify three approximation gaps which limit performance in the conventional approach: (i) an amortization gap, (ii) a discretization gap, and (iii) a marginalization gap. We propose improvements to each of these three shortcomings based on ideas related to iterative inference, stochastic annealing for discrete optimization, and bits-back coding, resulting in the first application of bits-back coding to lossy compression. In our experiments, which include extensive baseline comparisons and ablation studies, we achieve new state-of-the-art performance on lossy image compression using an established VAE architecture, by changing only the inference method.