 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Model Calibration in Simulation of Itaconic Acid Production
Apr 24, 2026In this study, deep learning is used to estimate kinetic parameters for modeling itaconic acid production based on real batch experiments conducted at different agitation speeds and reactor scales. Two deep learning strategies, namely direct deep learning (DDL) and generative conditional flow matching (CFM) are compared and benchmarked against nonlinear regression as a reference method. Compared with DDL, CFM consistently yields more accurate results. The concentration profiles predicted by CFM closely match those obtained from nonlinear regression, whereas DDL results in larger deviations. Similar behavior is observed in the scale-up experiments, where the CFM model again generalizes better and is more robust than the direct approach. These findings demonstrate that CFM can reliably predict system behavior across different operating conditions and scales, offering a flexible and data-efficient framework for parameter estimation in dynamic bioprocess models.
Automated Batch Distillation Process Simulation for a Large Hybrid Dataset for Deep Anomaly Detection
Apr 14, 2026Anomaly detection (AD) in chemical processes based on deep learning offers significant opportunities but requires large, diverse, and well-annotated training datasets that are rarely available from industrial operations. In a recent work, we introduced a large, fully annotated experimental dataset for batch distillation under normal and anomalous operating conditions. In the present study, we augment this dataset with a corresponding simulation dataset, creating a novel hybrid dataset. The simulation data is generated in an automated workflow with a novel Python-based process simulator that employs a tailored index-reduction strategy for the underlying differential-algebraic equations. Leveraging the rich metadata and structured anomaly annotations of the experimental database, experimental records are automatically translated into simulation scenarios. After calibration to a single reference experiment, the dynamics of the other experiments are well predicted. This enabled the fully automated, consistent generation of time-series data for a large number of experimental runs, covering both normal operation and a wide range of actuator- and control-related anomalies. The resulting hybrid dataset is released openly. From a process simulation perspective, this work demonstrates the automated, consistent simulation of large-scale experimental campaigns, using batch distillation as an example. From a data-driven AD perspective, the hybrid dataset provides a unique basis for simulation-to-experiment style transfer, the generation of pseudo-experimental data, and future research on deep AD methods in chemical process monitoring.
A Quantum Optimization Case Study for a Transport Robot Scheduling Problem
Sep 20, 2023We present a comprehensive case study comparing the performance of D-Waves' quantum-classical hybrid framework, Fujitsu's quantum-inspired digital annealer, and Gurobi's state-of-the-art classical solver in solving a transport robot scheduling problem. This problem originates from an industrially relevant real-world scenario. We provide three different models for our problem following different design philosophies. In our benchmark, we focus on the solution quality and end-to-end runtime of different model and solver combinations. We find promising results for the digital annealer and some opportunities for the hybrid quantum annealer in direct comparison with Gurobi. Our study provides insights into the workflow for solving an application-oriented optimization problem with different strategies, and can be useful for evaluating the strengths and weaknesses of different approaches.
Deep Anomaly Detection on Tennessee Eastman Process Data
Mar 10, 2023This paper provides the first comprehensive evaluation and analysis of modern (deep-learning) unsupervised anomaly detection methods for chemical process data. We focus on the Tennessee Eastman process dataset, which has been a standard litmus test to benchmark anomaly detection methods for nearly three decades. Our extensive study will facilitate choosing appropriate anomaly detection methods in industrial applications.
Calibrated Simplex Mapping Classification
Mar 04, 2021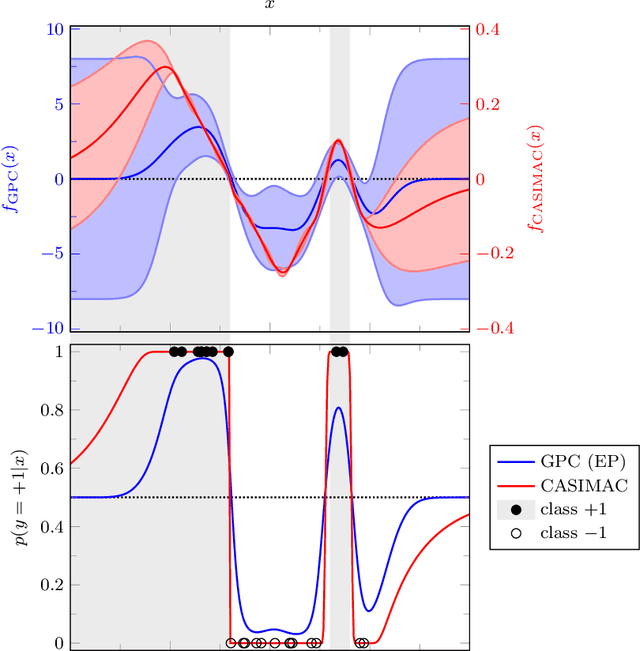

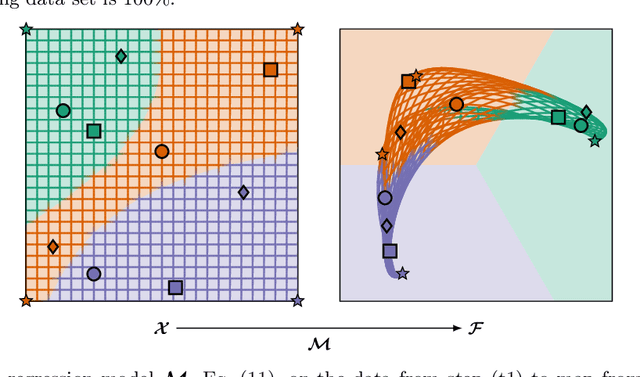
We propose a novel supervised multi-class/single-label classifier that maps training data onto a linearly separable latent space with a simplex-like geometry. This approach allows us to transform the classification problem into a well-defined regression problem. For its solution we can choose suitable distance metrics in feature space and regression models predicting latent space coordinates. A benchmark on various artificial and real-world data sets is used to demonstrate the calibration qualities and prediction performance of our classifier.
Adaptive Sampling of Pareto Frontiers with Binary Constraints Using Regression and Classification
Aug 27, 2020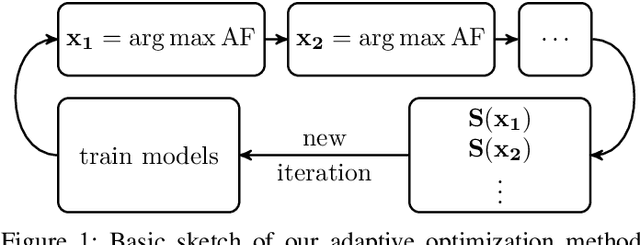
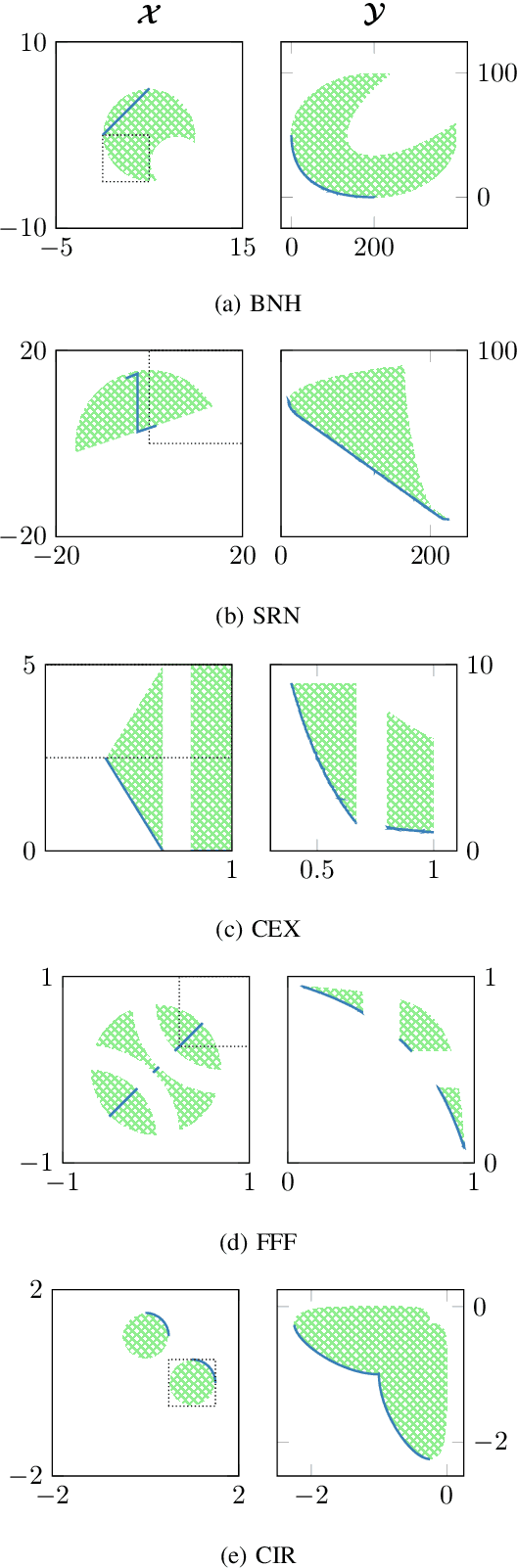
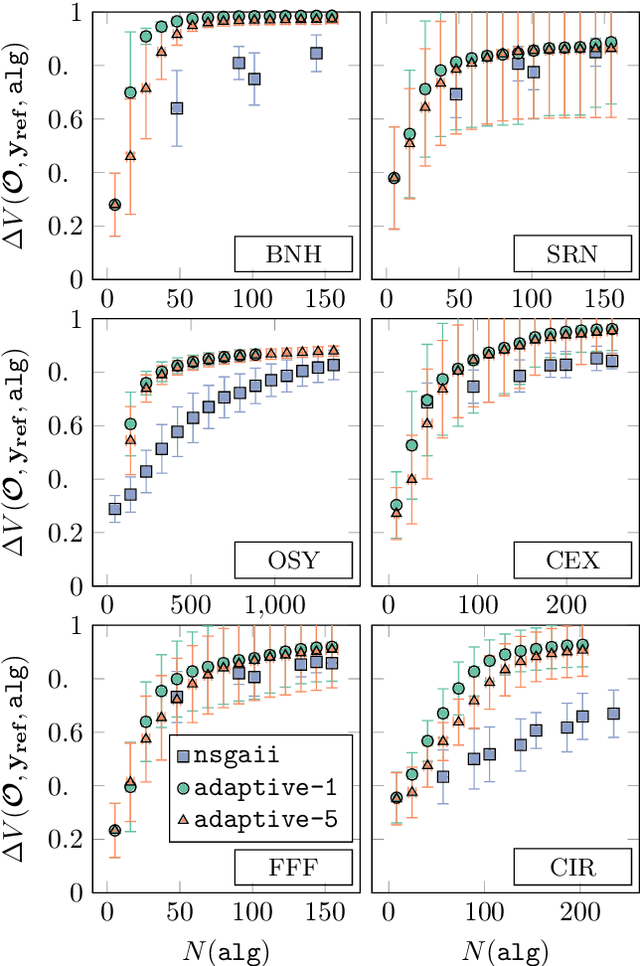
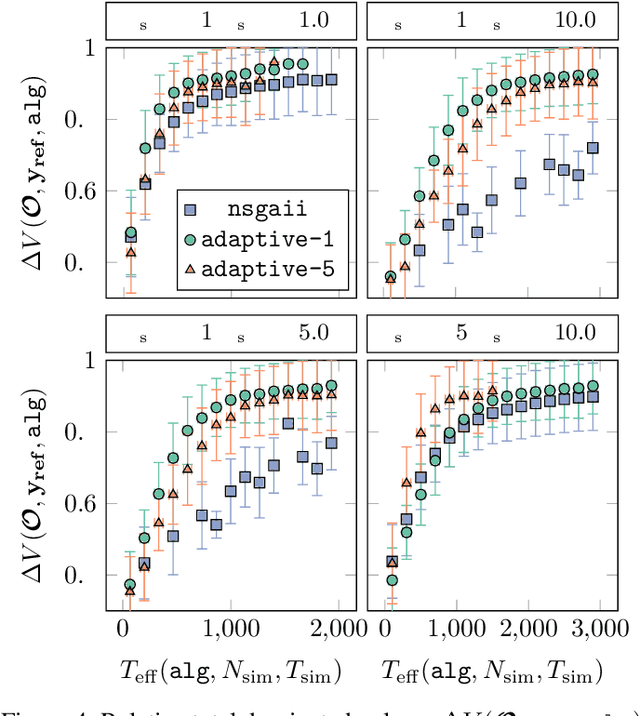
We present a novel adaptive optimization algorithm for black-box multi-objective optimization problems with binary constraints on the foundation of Bayes optimization. Our method is based on probabilistic regression and classification models, which act as a surrogate for the optimization goals and allow us to suggest multiple design points at once in each iteration. The proposed acquisition function is intuitively understandable and can be tuned to the demands of the problems at hand. We also present a novel ellipsoid truncation method to speed up the expected hypervolume calculation in a straightforward way for regression models with a normal probability density. We benchmark our approach with an evolutionary algorithm on multiple test problems.
CupNet -- Pruning a network for geometric data
May 11, 2020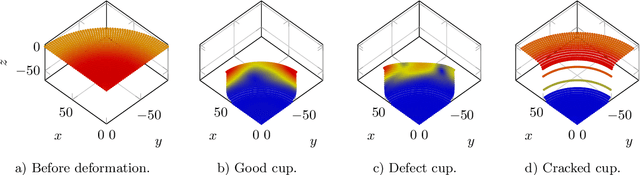
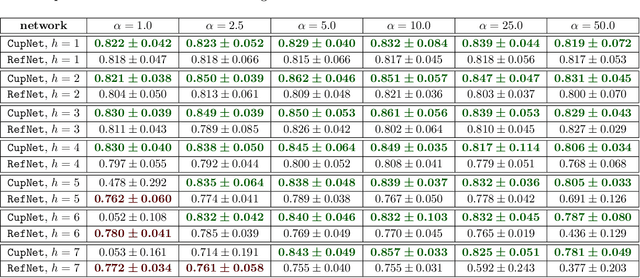
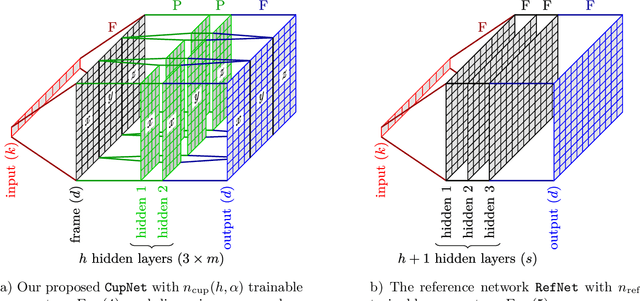
Using data from a simulated cup drawing process, we demonstrate how the inherent geometrical structure of cup meshes can be used to effectively prune an artificial neural network in a straightforward way.
Machine Learning in Thermodynamics: Prediction of Activity Coefficients by Matrix Completion
Jan 29, 2020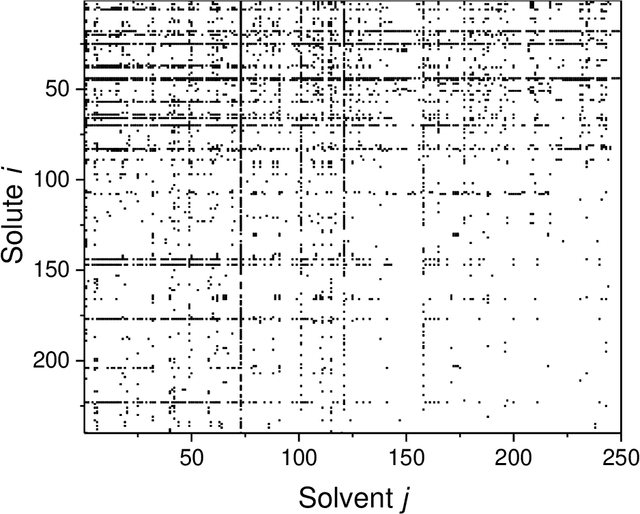
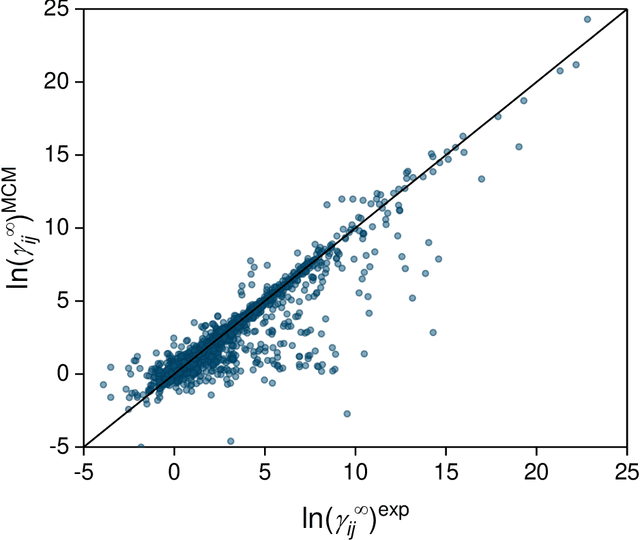
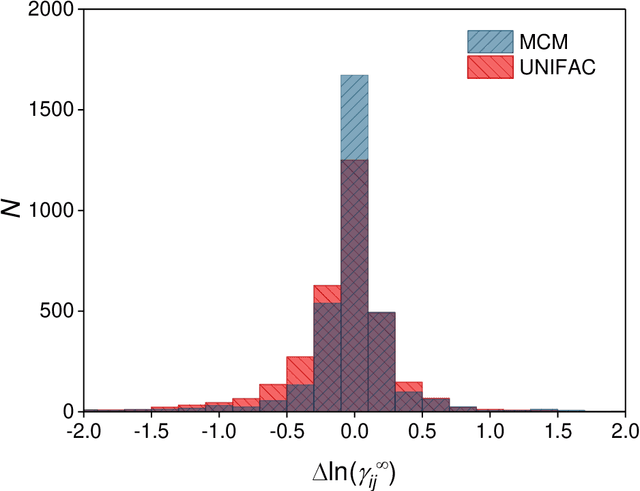
Activity coefficients, which are a measure of the non-ideality of liquid mixtures, are a key property in chemical engineering with relevance to modeling chemical and phase equilibria as well as transport processes. Although experimental data on thousands of binary mixtures are available, prediction methods are needed to calculate the activity coefficients in many relevant mixtures that have not been explored to-date. In this report, we propose a probabilistic matrix factorization model for predicting the activity coefficients in arbitrary binary mixtures. Although no physical descriptors for the considered components were used, our method outperforms the state-of-the-art method that has been refined over three decades while requiring much less training effort. This opens perspectives to novel methods for predicting physico-chemical properties of binary mixtures with the potential to revolutionize modeling and simulation in chemical engineering.
* Published version: J. Phys. Chem. Lett. 11 (2020) 981-985; https://pubs.acs.org/doi/full/10.1021/acs.jpclett.9b03657
The Good, the Bad and the Ugly: Augmenting a black-box model with expert knowledge
Jul 24, 2019
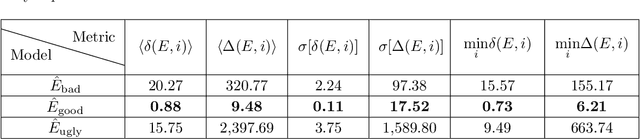
We address a non-unique parameter fitting problem in the context of material science. In particular, we propose to resolve ambiguities in parameter space by augmenting a black-box artificial neural network (ANN) model with two different levels of expert knowledge and benchmark them against a pure black-box model.
Optimized data exploration applied to the simulation of a chemical process
Feb 18, 2019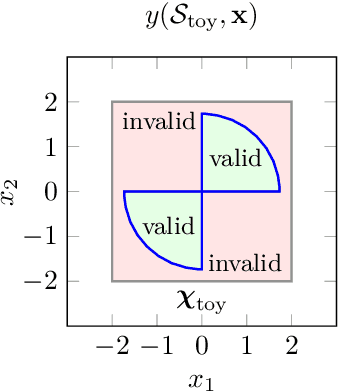
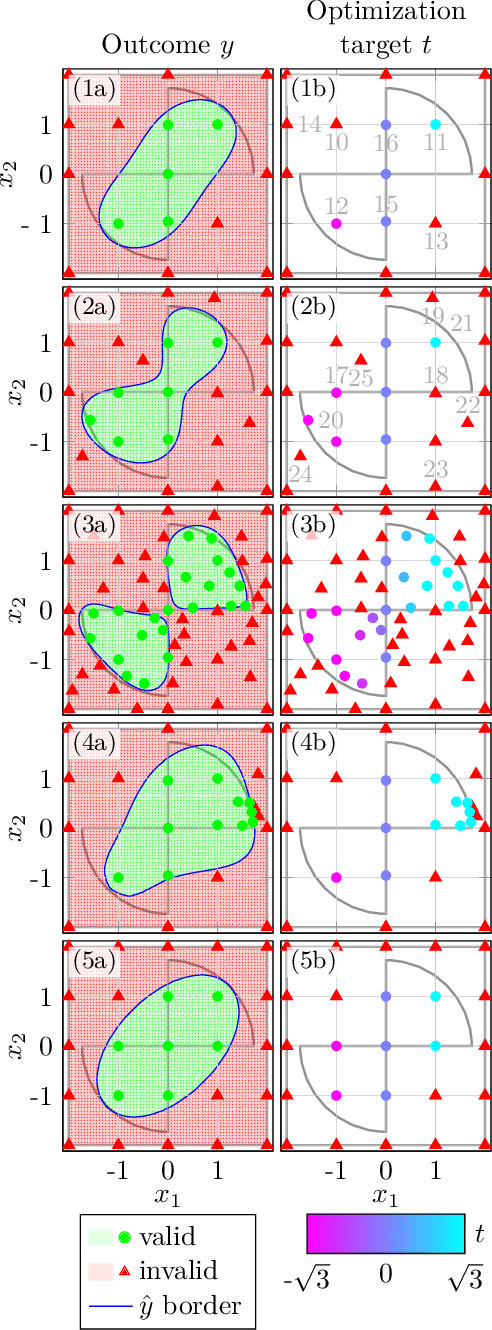
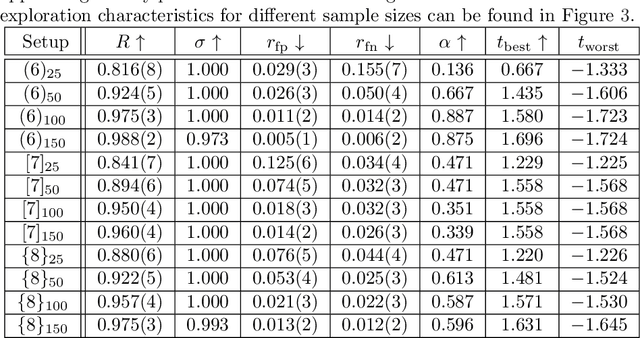
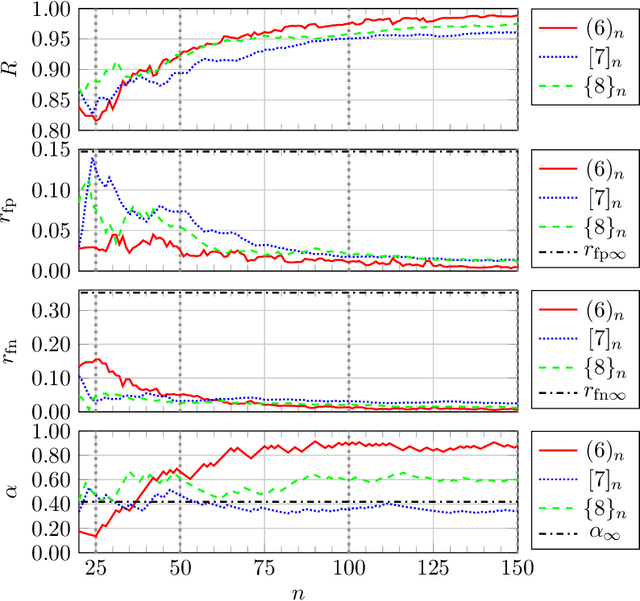
In complex simulation environments, certain parameter space regions may result in non-convergent or unphysical outcomes. All parameters can therefore be labeled with a binary class describing whether or not they lead to valid results. In general, it can be very difficult to determine feasible parameter regions, especially without previous knowledge. We propose a novel algorithm to explore such an unknown parameter space and improve its feasibility classification in an iterative way. Moreover, we include an additional optimization target in the algorithm to guide the exploration towards regions of interest and to improve the classification therein. In our method we make use of well-established concepts from the field of machine learning like kernel support vector machines and kernel ridge regression. From a comparison with a Kriging-based exploration approach based on recently published results we can show the advantages of our algorithm in a binary feasibility classification scenario with a discrete feasibility constraint violation. In this context, we also propose an improvement of the Kriging-based exploration approach. We apply our novel method to a fully realistic, industrially relevant chemical process simulation to demonstrate its practical usability and find a comparably good approximation of the data space topology from relatively few data points.
* 45 pages, 6 figures