 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-fidelity Direct Contrast Synthesis from Magnetic Resonance Fingerprinting
Dec 21, 2022Magnetic Resonance Fingerprinting (MRF) is an efficient quantitative MRI technique that can extract important tissue and system parameters such as T1, T2, B0, and B1 from a single scan. This property also makes it attractive for retrospectively synthesizing contrast-weighted images. In general, contrast-weighted images like T1-weighted, T2-weighted, etc., can be synthesized directly from parameter maps through spin-dynamics simulation (i.e., Bloch or Extended Phase Graph models). However, these approaches often exhibit artifacts due to imperfections in the mapping, the sequence modeling, and the data acquisition. Here we propose a supervised learning-based method that directly synthesizes contrast-weighted images from the MRF data without going through the quantitative mapping and spin-dynamics simulation. To implement our direct contrast synthesis (DCS) method, we deploy a conditional Generative Adversarial Network (GAN) framework and propose a multi-branch U-Net as the generator. The input MRF data are used to directly synthesize T1-weighted, T2-weighted, and fluid-attenuated inversion recovery (FLAIR) images through supervised training on paired MRF and target spin echo-based contrast-weighted scans. In-vivo experiments demonstrate excellent image quality compared to simulation-based contrast synthesis and previous DCS methods, both visually as well as by quantitative metrics. We also demonstrate cases where our trained model is able to mitigate in-flow and spiral off-resonance artifacts that are typically seen in MRF reconstructions and thus more faithfully represent conventional spin echo-based contrast-weighted images.
Improving Unsupervised Video Object Segmentation with Motion-Appearance Synergy
Dec 17, 2022We present IMAS, a method that segments the primary objects in videos without manual annotation in training or inference. Previous methods in unsupervised video object segmentation (UVOS) have demonstrated the effectiveness of motion as either input or supervision for segmentation. However, motion signals may be uninformative or even misleading in cases such as deformable objects and objects with reflections, causing unsatisfactory segmentation. In contrast, IMAS achieves Improved UVOS with Motion-Appearance Synergy. Our method has two training stages: 1) a motion-supervised object discovery stage that deals with motion-appearance conflicts through a learnable residual pathway; 2) a refinement stage with both low- and high-level appearance supervision to correct model misconceptions learned from misleading motion cues. Additionally, we propose motion-semantic alignment as a model-agnostic annotation-free hyperparam tuning method. We demonstrate its effectiveness in tuning critical hyperparams previously tuned with human annotation or hand-crafted hyperparam-specific metrics. IMAS greatly improves the segmentation quality on several common UVOS benchmarks. For example, we surpass previous methods by 8.3% on DAVIS16 benchmark with only standard ResNet and convolutional heads. We intend to release our code for future research and applications.
Tracking the Dynamics of the Tear Film Lipid Layer
Dec 07, 2022Dry Eye Disease (DED) is one of the most common ocular diseases: over five percent of US adults suffer from DED. Tear film instability is a known factor for DED, and is thought to be regulated in large part by the thin lipid layer that covers and stabilizes the tear film. In order to aid eye related disease diagnosis, this work proposes a novel paradigm in using computer vision techniques to numerically analyze the tear film lipid layer (TFLL) spread. Eleven videos of the tear film lipid layer spread are collected with a micro-interferometer and a subset are annotated. A tracking algorithm relying on various pillar computer vision techniques is developed. Our method can be found at https://easytear-dev.github.io/.
Multi-Spectral Image Classification with Ultra-Lean Complex-Valued Models
Nov 21, 2022



Multi-spectral imagery is invaluable for remote sensing due to different spectral signatures exhibited by materials that often appear identical in greyscale and RGB imagery. Paired with modern deep learning methods, this modality has great potential utility in a variety of remote sensing applications, such as humanitarian assistance and disaster recovery efforts. State-of-the-art deep learning methods have greatly benefited from large-scale annotations like in ImageNet, but existing MSI image datasets lack annotations at a similar scale. As an alternative to transfer learning on such data with few annotations, we apply complex-valued co-domain symmetric models to classify real-valued MSI images. Our experiments on 8-band xView data show that our ultra-lean model trained on xView from scratch without data augmentations can outperform ResNet with data augmentation and modified transfer learning on xView. Our work is the first to demonstrate the value of complex-valued deep learning on real-valued MSI data.
CAST: Concurrent Recognition and Segmentation with Adaptive Segment Tokens
Oct 04, 2022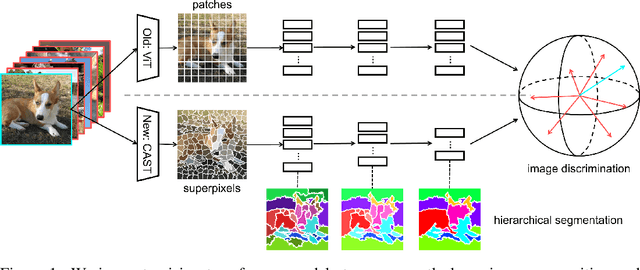
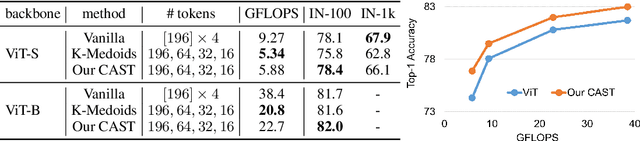
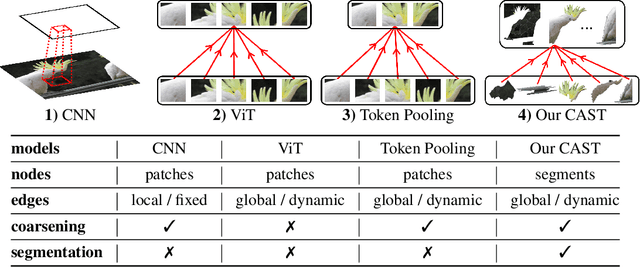

Recognizing an image and segmenting it into coherent regions are often treated as separate tasks. Human vision, however, has a general sense of segmentation hierarchy before recognition occurs. We are thus inspired to learn image recognition with hierarchical image segmentation based entirely on unlabeled images. Our insight is to learn fine-to-coarse features concurrently at superpixels, segments, and full image levels, enforcing consistency and goodness of feature induced segmentations while maximizing discrimination among image instances. Our model innovates vision transformers on three aspects. 1) We use adaptive segment tokens instead of fixed-shape patch tokens. 2) We create a token hierarchy by inserting graph pooling between transformer blocks, naturally producing consistent multi-scale segmentations while increasing the segment size and reducing the number of tokens. 3) We produce hierarchical image segmentation for free while training for recognition by maximizing image-wise discrimination. Our work delivers the first concurrent recognition and hierarchical segmentation model without any supervision. Validated on ImageNet and PASCAL VOC, it achieves better recognition and segmentation with higher computational efficiency.
Unsupervised Scene Sketch to Photo Synthesis
Sep 06, 2022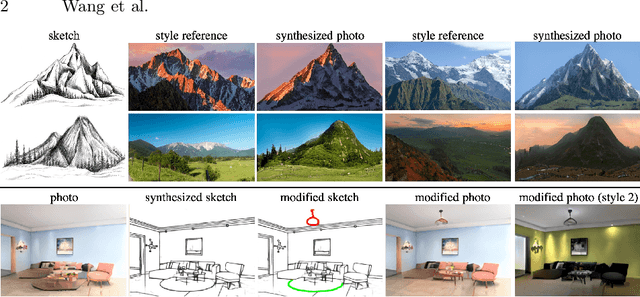
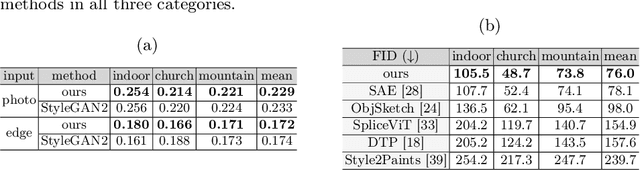
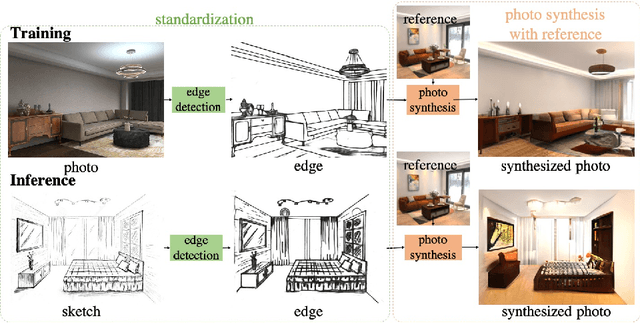

Sketches make an intuitive and powerful visual expression as they are fast executed freehand drawings. We present a method for synthesizing realistic photos from scene sketches. Without the need for sketch and photo pairs, our framework directly learns from readily available large-scale photo datasets in an unsupervised manner. To this end, we introduce a standardization module that provides pseudo sketch-photo pairs during training by converting photos and sketches to a standardized domain, i.e. the edge map. The reduced domain gap between sketch and photo also allows us to disentangle them into two components: holistic scene structures and low-level visual styles such as color and texture. Taking this advantage, we synthesize a photo-realistic image by combining the structure of a sketch and the visual style of a reference photo. Extensive experimental results on perceptual similarity metrics and human perceptual studies show the proposed method could generate realistic photos with high fidelity from scene sketches and outperform state-of-the-art photo synthesis baselines. We also demonstrate that our framework facilitates a controllable manipulation of photo synthesis by editing strokes of corresponding sketches, delivering more fine-grained details than previous approaches that rely on region-level editing.
Open Long-Tailed Recognition in a Dynamic World
Aug 17, 2022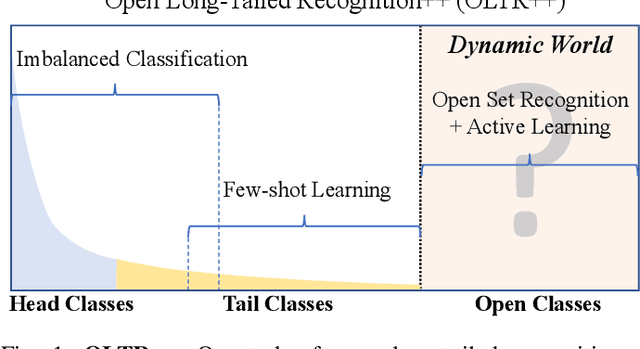
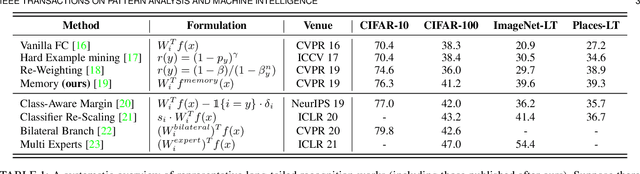
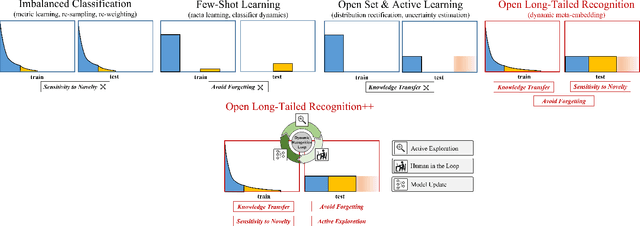

Real world data often exhibits a long-tailed and open-ended (with unseen classes) distribution. A practical recognition system must balance between majority (head) and minority (tail) classes, generalize across the distribution, and acknowledge novelty upon the instances of unseen classes (open classes). We define Open Long-Tailed Recognition++ (OLTR++) as learning from such naturally distributed data and optimizing for the classification accuracy over a balanced test set which includes both known and open classes. OLTR++ handles imbalanced classification, few-shot learning, open-set recognition, and active learning in one integrated algorithm, whereas existing classification approaches often focus only on one or two aspects and deliver poorly over the entire spectrum. The key challenges are: 1) how to share visual knowledge between head and tail classes, 2) how to reduce confusion between tail and open classes, and 3) how to actively explore open classes with learned knowledge. Our algorithm, OLTR++, maps images to a feature space such that visual concepts can relate to each other through a memory association mechanism and a learned metric (dynamic meta-embedding) that both respects the closed world classification of seen classes and acknowledges the novelty of open classes. Additionally, we propose an active learning scheme based on visual memory, which learns to recognize open classes in a data-efficient manner for future expansions. On three large-scale open long-tailed datasets we curated from ImageNet (object-centric), Places (scene-centric), and MS1M (face-centric) data, as well as three standard benchmarks (CIFAR-10-LT, CIFAR-100-LT, and iNaturalist-18), our approach, as a unified framework, consistently demonstrates competitive performance. Notably, our approach also shows strong potential for the active exploration of open classes and the fairness analysis of minority groups.
Unsupervised Hierarchical Semantic Segmentation with Multiview Cosegmentation and Clustering Transformers
Apr 25, 2022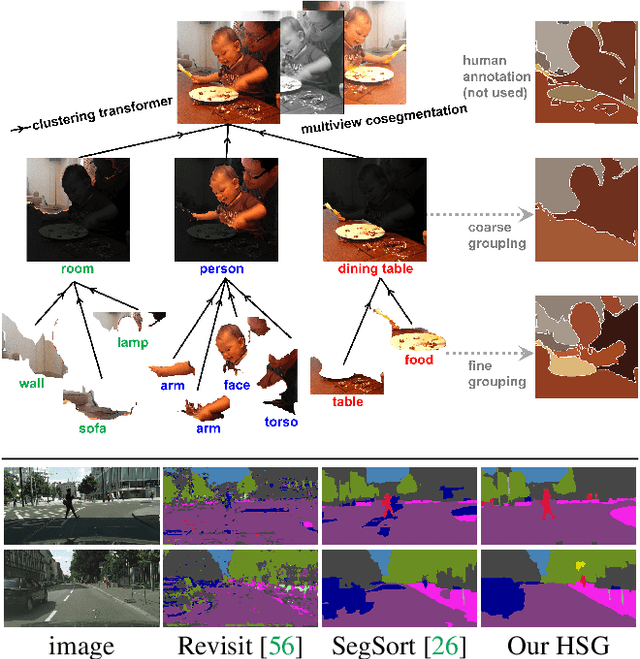
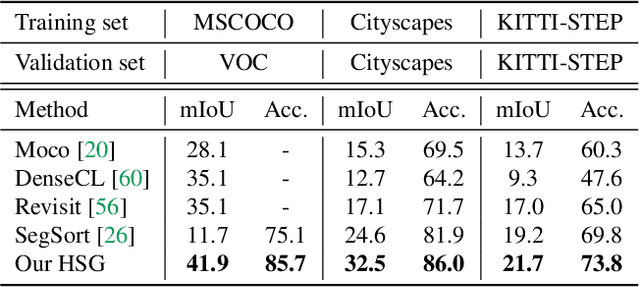
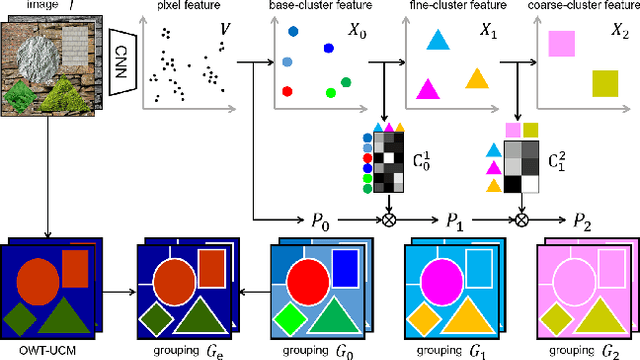
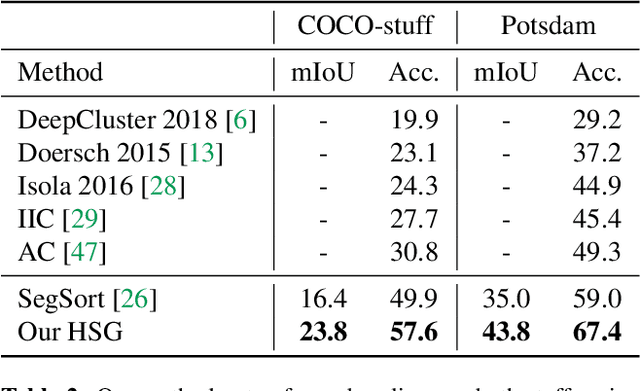
Unsupervised semantic segmentation aims to discover groupings within and across images that capture object and view-invariance of a category without external supervision. Grouping naturally has levels of granularity, creating ambiguity in unsupervised segmentation. Existing methods avoid this ambiguity and treat it as a factor outside modeling, whereas we embrace it and desire hierarchical grouping consistency for unsupervised segmentation. We approach unsupervised segmentation as a pixel-wise feature learning problem. Our idea is that a good representation shall reveal not just a particular level of grouping, but any level of grouping in a consistent and predictable manner. We enforce spatial consistency of grouping and bootstrap feature learning with co-segmentation among multiple views of the same image, and enforce semantic consistency across the grouping hierarchy with clustering transformers between coarse- and fine-grained features. We deliver the first data-driven unsupervised hierarchical semantic segmentation method called Hierarchical Segment Grouping (HSG). Capturing visual similarity and statistical co-occurrences, HSG also outperforms existing unsupervised segmentation methods by a large margin on five major object- and scene-centric benchmarks. Our code is publicly available at https://github.com/twke18/HSG .
Debiased Learning from Naturally Imbalanced Pseudo-Labels for Zero-Shot and Semi-Supervised Learning
Jan 05, 2022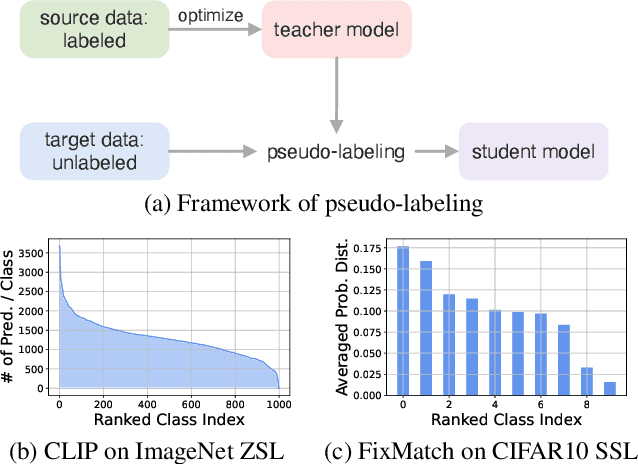
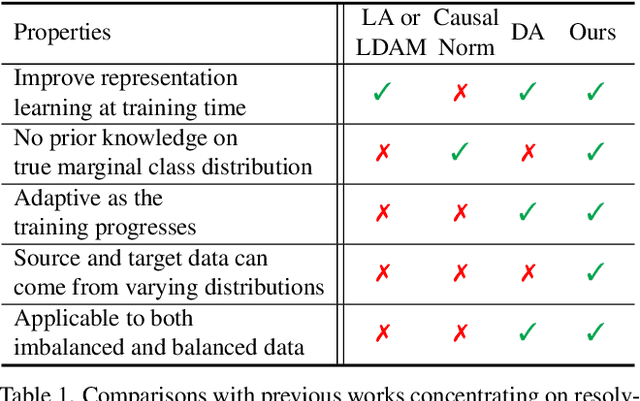
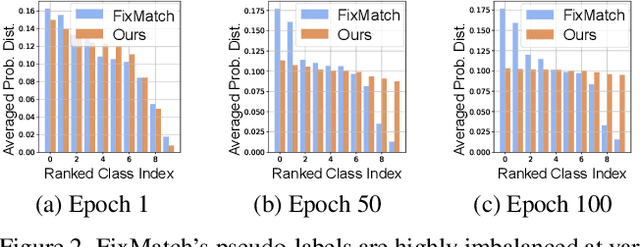
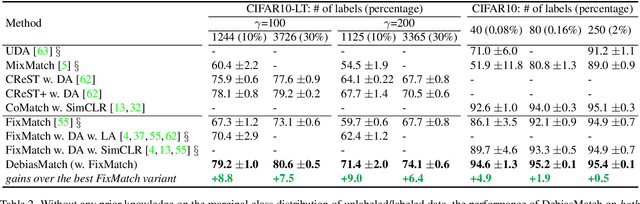
This work studies the bias issue of pseudo-labeling, a natural phenomenon that widely occurs but often overlooked by prior research. Pseudo-labels are generated when a classifier trained on source data is transferred to unlabeled target data. We observe heavy long-tailed pseudo-labels when a semi-supervised learning model FixMatch predicts labels on the unlabeled set even though the unlabeled data is curated to be balanced. Without intervention, the training model inherits the bias from the pseudo-labels and end up being sub-optimal. To eliminate the model bias, we propose a simple yet effective method DebiasMatch, comprising of an adaptive debiasing module and an adaptive marginal loss. The strength of debiasing and the size of margins can be automatically adjusted by making use of an online updated queue. Benchmarked on ImageNet-1K, DebiasMatch significantly outperforms previous state-of-the-arts by more than 26% and 8.7% on semi-supervised learning (0.2% annotated data) and zero-shot learning tasks respectively.
Co-domain Symmetry for Complex-Valued Deep Learning
Dec 02, 2021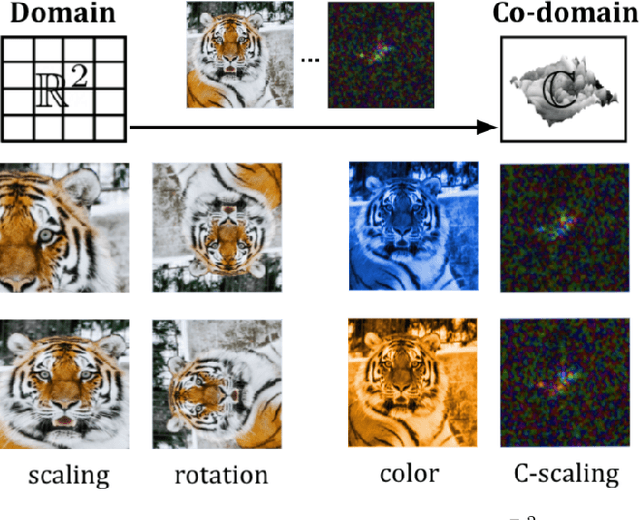
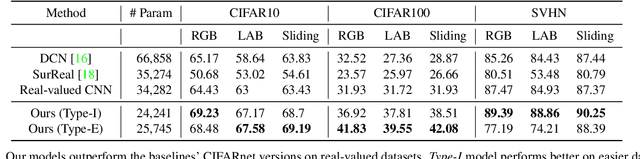
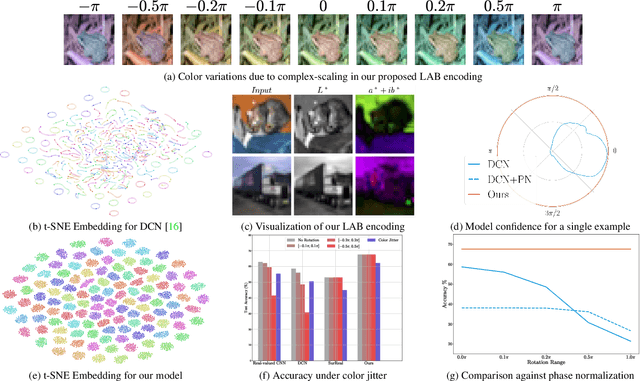
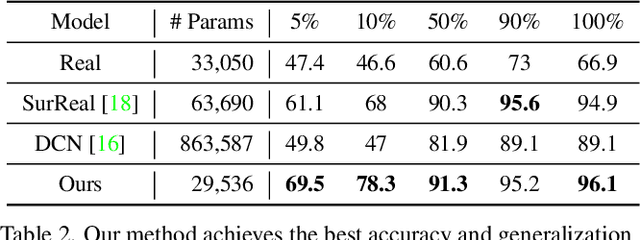
We study complex-valued scaling as a type of symmetry natural and unique to complex-valued measurements and representations. Deep Complex Networks (DCN) extends real-valued algebra to the complex domain without addressing complex-valued scaling. SurReal takes a restrictive manifold view of complex numbers, adopting a distance metric to achieve complex-scaling invariance while losing rich complex-valued information. We analyze complex-valued scaling as a co-domain transformation and design novel equivariant and invariant neural network layer functions for this special transformation. We also propose novel complex-valued representations of RGB images, where complex-valued scaling indicates hue shift or correlated changes across color channels. Benchmarked on MSTAR, CIFAR10, CIFAR100, and SVHN, our co-domain symmetric (CDS) classifiers deliver higher accuracy, better generalization, robustness to co-domain transformations, and lower model bias and variance than DCN and SurReal with far fewer parameters.