 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffect Analysis in-the-wild: Valence-Arousal, Expressions, Action Units and a Unified Framework
Mar 29, 2021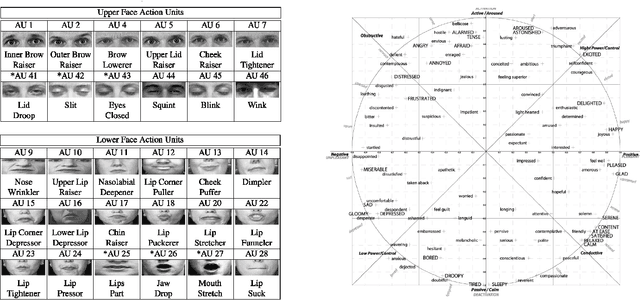
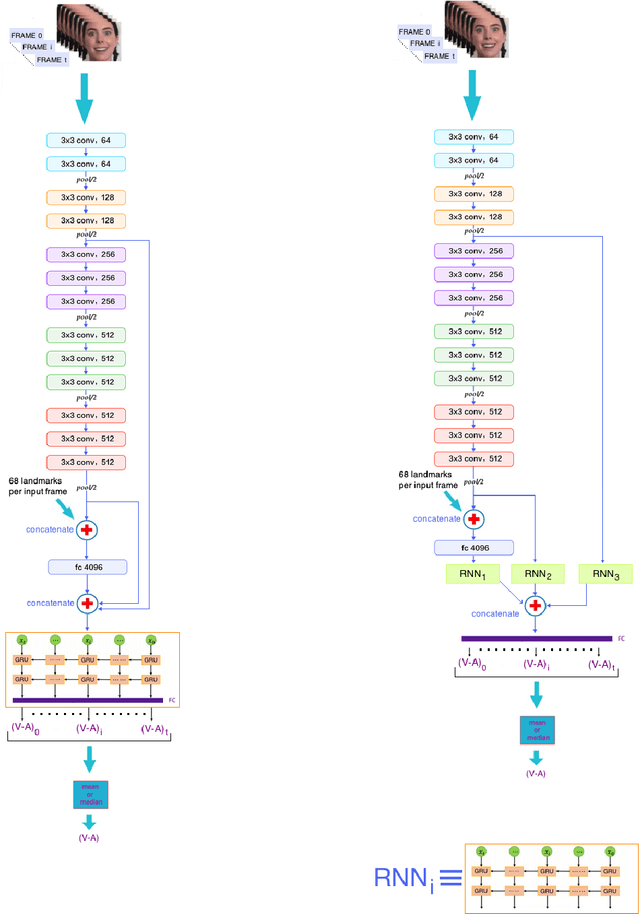
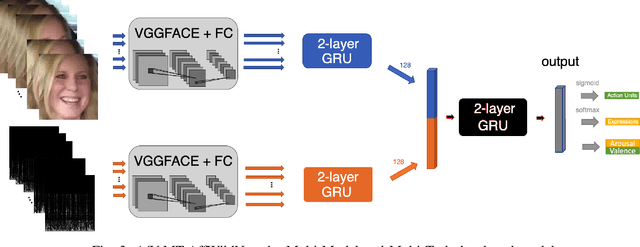
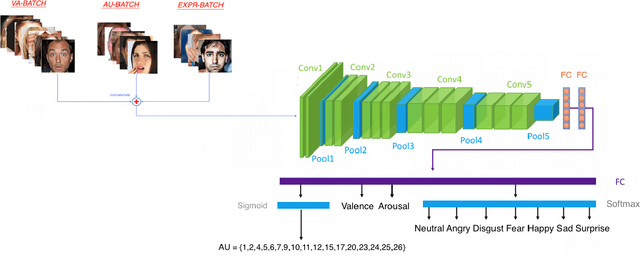
Affect recognition based on subjects' facial expressions has been a topic of major research in the attempt to generate machines that can understand the way subjects feel, act and react. In the past, due to the unavailability of large amounts of data captured in real-life situations, research has mainly focused on controlled environments. However, recently, social media and platforms have been widely used. Moreover, deep learning has emerged as a means to solve visual analysis and recognition problems. This paper exploits these advances and presents significant contributions for affect analysis and recognition in-the-wild. Affect analysis and recognition can be seen as a dual knowledge generation problem, involving: i) creation of new, large and rich in-the-wild databases and ii) design and training of novel deep neural architectures that are able to analyse affect over these databases and to successfully generalise their performance on other datasets. The paper focuses on large in-the-wild databases, i.e., Aff-Wild and Aff-Wild2 and presents the design of two classes of deep neural networks trained with these databases. The first class refers to uni-task affect recognition, focusing on prediction of the valence and arousal dimensional variables. The second class refers to estimation of all main behavior tasks, i.e. valence-arousal prediction; categorical emotion classification in seven basic facial expressions; facial Action Unit detection. A novel multi-task and holistic framework is presented which is able to jointly learn and effectively generalize and perform affect recognition over all existing in-the-wild databases. Large experimental studies illustrate the achieved performance improvement over the existing state-of-the-art in affect recognition.
Speech Emotion Recognition using Semantic Information
Mar 04, 2021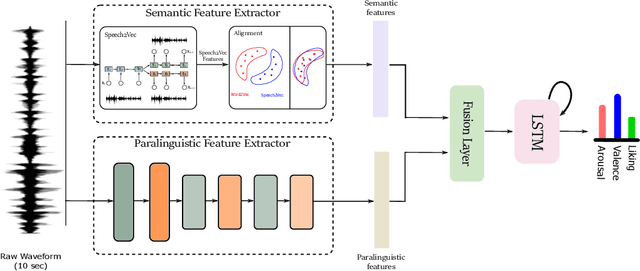

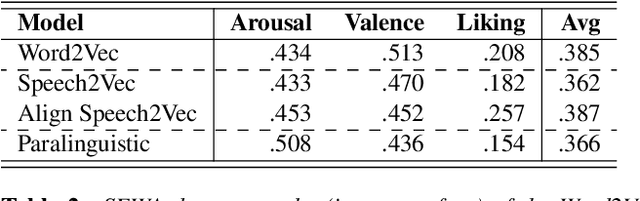

Speech emotion recognition is a crucial problem manifesting in a multitude of applications such as human computer interaction and education. Although several advancements have been made in the recent years, especially with the advent of Deep Neural Networks (DNN), most of the studies in the literature fail to consider the semantic information in the speech signal. In this paper, we propose a novel framework that can capture both the semantic and the paralinguistic information in the signal. In particular, our framework is comprised of a semantic feature extractor, that captures the semantic information, and a paralinguistic feature extractor, that captures the paralinguistic information. Both semantic and paraliguistic features are then combined to a unified representation using a novel attention mechanism. The unified feature vector is passed through a LSTM to capture the temporal dynamics in the signal, before the final prediction. To validate the effectiveness of our framework, we use the popular SEWA dataset of the AVEC challenge series and compare with the three winning papers. Our model provides state-of-the-art results in the valence and liking dimensions.
Binary Graph Neural Networks
Dec 31, 2020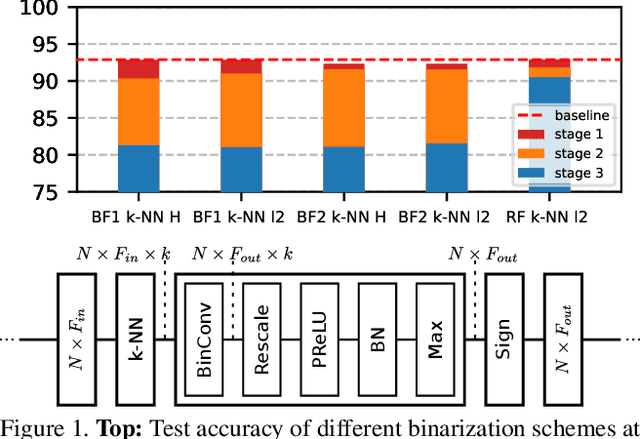
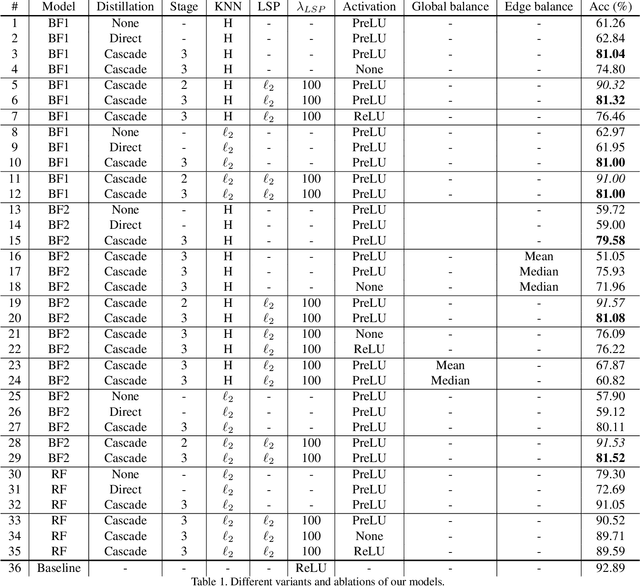
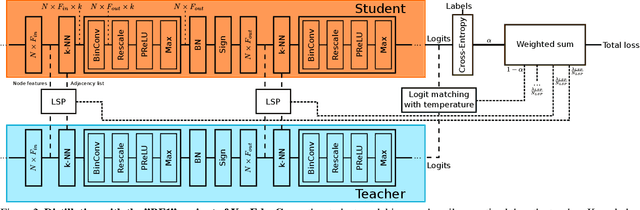
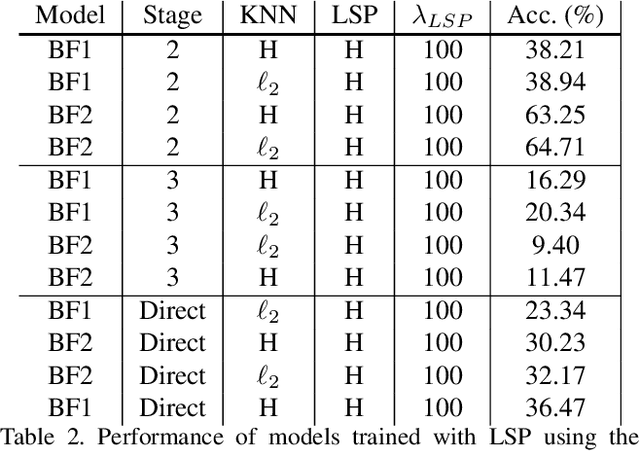
Graph Neural Networks (GNNs) have emerged as a powerful and flexible framework for representation learning on irregular data. As they generalize the operations of classical CNNs on grids to arbitrary topologies, GNNs also bring much of the implementation challenges of their Euclidean counterparts. Model size, memory footprint, and energy consumption are common concerns for many real-world applications. Network binarization allocates a single bit to network parameters and activations, thus dramatically reducing the memory requirements (up to 32x compared to single-precision floating-point parameters) and maximizing the benefits of fast SIMD instructions of modern hardware for measurable speedups. However, in spite of the large body of work on binarization for classical CNNs, this area remains largely unexplored in geometric deep learning. In this paper, we present and evaluate different strategies for the binarization of graph neural networks. We show that through careful design of the models, and control of the training process, binary graph neural networks can be trained at only a moderate cost in accuracy on challenging benchmarks. In particular, we present the first dynamic graph neural network in Hamming space, able to leverage efficient $k$-NN search on binary vectors to speed-up the construction of the dynamic graph. We further verify that the binary models offer significant savings on embedded devices.
OSTeC: One-Shot Texture Completion
Dec 30, 2020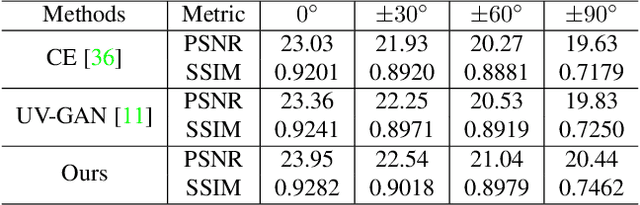

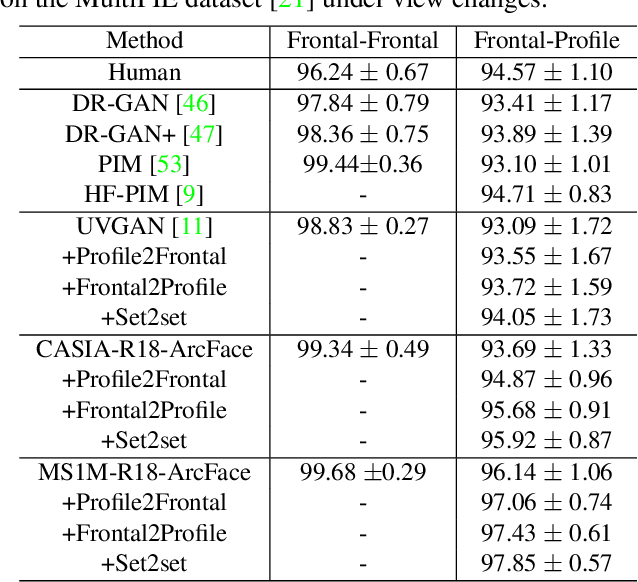

The last few years have witnessed the great success of non-linear generative models in synthesizing high-quality photorealistic face images. Many recent 3D facial texture reconstruction and pose manipulation from a single image approaches still rely on large and clean face datasets to train image-to-image Generative Adversarial Networks (GANs). Yet the collection of such a large scale high-resolution 3D texture dataset is still very costly and difficult to maintain age/ethnicity balance. Moreover, regression-based approaches suffer from generalization to the in-the-wild conditions and are unable to fine-tune to a target-image. In this work, we propose an unsupervised approach for one-shot 3D facial texture completion that does not require large-scale texture datasets, but rather harnesses the knowledge stored in 2D face generators. The proposed approach rotates an input image in 3D and fill-in the unseen regions by reconstructing the rotated image in a 2D face generator, based on the visible parts. Finally, we stitch the most visible textures at different angles in the UV image-plane. Further, we frontalize the target image by projecting the completed texture into the generator. The qualitative and quantitative experiments demonstrate that the completed UV textures and frontalized images are of high quality, resembles the original identity, can be used to train a texture GAN model for 3DMM fitting and improve pose-invariant face recognition.
Shape My Face: Registering 3D Face Scans by Surface-to-Surface Translation
Dec 16, 2020
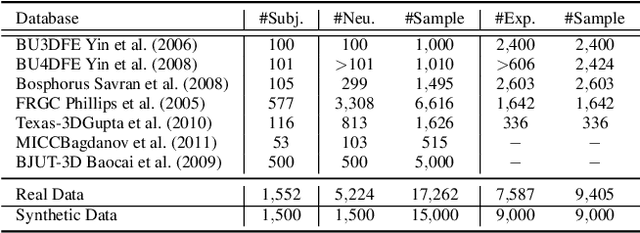

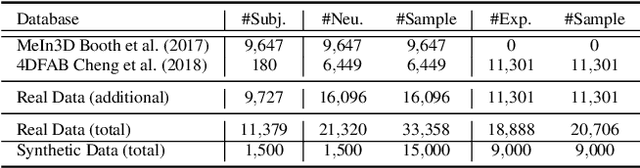
Existing surface registration methods focus on fitting in-sample data with little to no generalization ability and require both heavy pre-processing and careful hand-tuning. In this paper, we cast the registration task as a surface-to-surface translation problem, and design a model to reliably capture the latent geometric information directly from raw 3D face scans. We introduce Shape-My-Face (SMF), a powerful encoder-decoder architecture based on an improved point cloud encoder, a novel visual attention mechanism, graph convolutional decoders with skip connections, and a specialized mouth model that we smoothly integrate with the mesh convolutions. Compared to the previous state-of-the-art learning algorithms for non-rigid registration of face scans, SMF only requires the raw data to be rigidly aligned (with scaling) with a pre-defined face template. Additionally, our model provides topologically-sound meshes with minimal supervision, offers faster training time, has orders of magnitude fewer trainable parameters, is more robust to noise, and can generalize to previously unseen datasets. We extensively evaluate the quality of our registrations on diverse data. We demonstrate the robustness and generalizability of our model with in-the-wild face scans across different modalities, sensor types, and resolutions. Finally, we show that, by learning to register scans, SMF produces a hybrid linear and non-linear morphable model that can be used for generation, shape morphing, and expression transfer through manipulation of the latent space, including in-the-wild. We train SMF on a dataset of human faces comprising 9 large-scale databases on commodity hardware.
HeadGAN: Video-and-Audio-Driven Talking Head Synthesis
Dec 15, 2020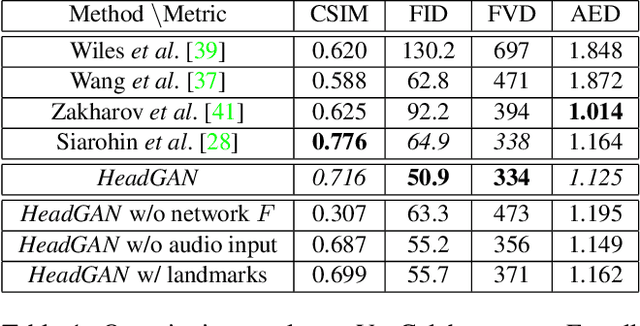
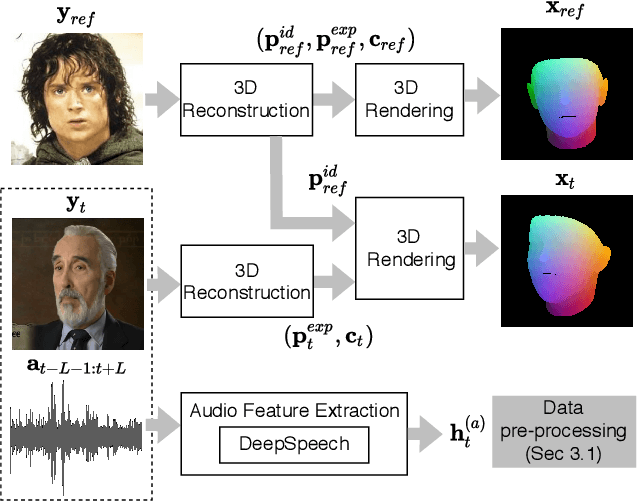
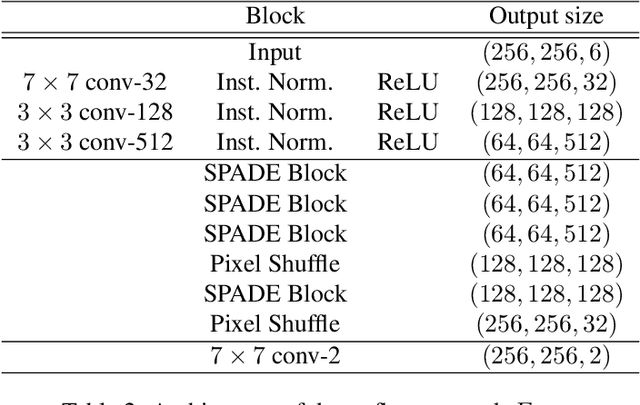
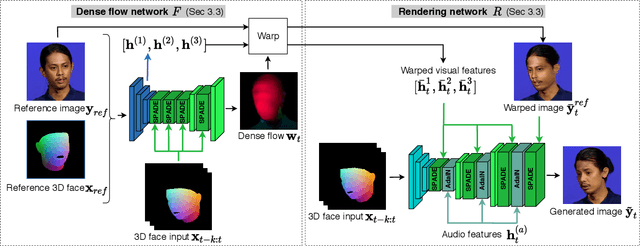
Recent attempts to solve the problem of talking head synthesis using a single reference image have shown promising results. However, most of them fail to meet the identity preservation problem, or perform poorly in terms of photo-realism, especially in extreme head poses. We propose HeadGAN, a novel reenactment approach that conditions synthesis on 3D face representations, which can be extracted from any driving video and adapted to the facial geometry of any source. We improve the plausibility of mouth movements, by utilising audio features as a complementary input to the Generator. Quantitative and qualitative experiments demonstrate the merits of our approach.
Learning to Generate Customized Dynamic 3D Facial Expressions
Jul 21, 2020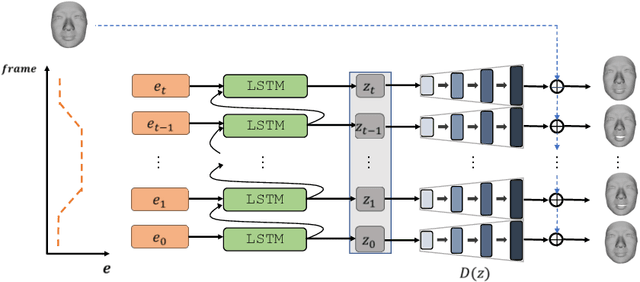
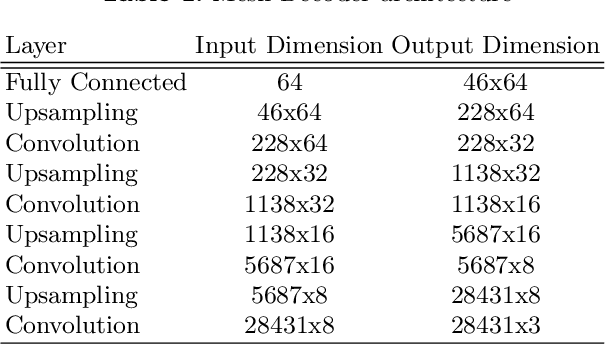
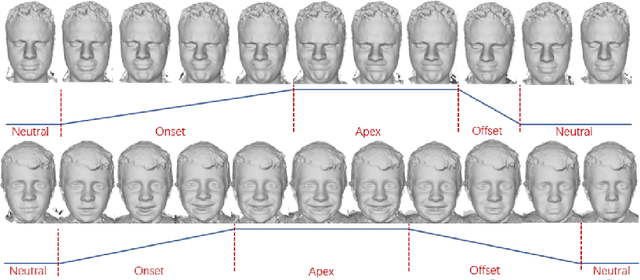

Recent advances in deep learning have significantly pushed the state-of-the-art in photorealistic video animation given a single image. In this paper, we extrapolate those advances to the 3D domain, by studying 3D image-to-video translation with a particular focus on 4D facial expressions. Although 3D facial generative models have been widely explored during the past years, 4D animation remains relatively unexplored. To this end, in this study we employ a deep mesh encoder-decoder like architecture to synthesize realistic high resolution facial expressions by using a single neutral frame along with an expression identification. In addition, processing 3D meshes remains a non-trivial task compared to data that live on grid-like structures, such as images. Given the recent progress in mesh processing with graph convolutions, we make use of a recently introduced learnable operator which acts directly on the mesh structure by taking advantage of local vertex orderings. In order to generalize to 4D facial expressions across subjects, we trained our model using a high resolution dataset with 4D scans of six facial expressions from 180 subjects. Experimental results demonstrate that our approach preserves the subject's identity information even for unseen subjects and generates high quality expressions. To the best of our knowledge, this is the first study tackling the problem of 4D facial expression synthesis.
Deep Polynomial Neural Networks
Jun 20, 2020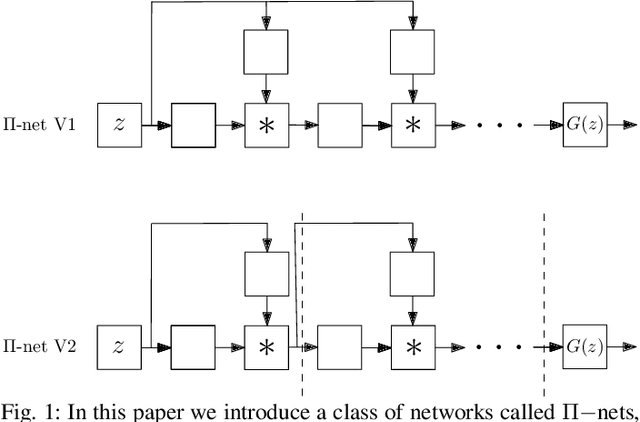

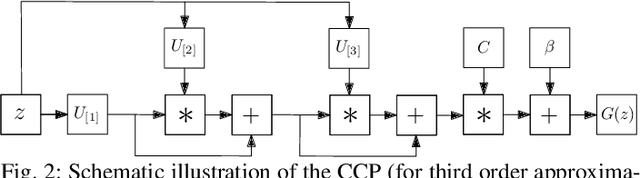
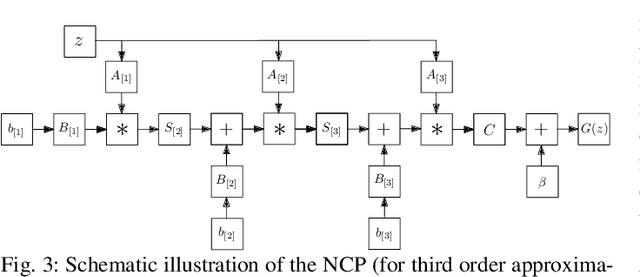
Deep Convolutional Neural Networks (DCNNs) are currently the method of choice both for generative, as well as for discriminative learning in computer vision and machine learning. The success of DCNNs can be attributed to the careful selection of their building blocks (e.g., residual blocks, rectifiers, sophisticated normalization schemes, to mention but a few). In this paper, we propose $\Pi$-Nets, a new class of DCNNs. $\Pi$-Nets are polynomial neural networks, i.e., the output is a high-order polynomial of the input. The unknown parameters, which are naturally represented by high-order tensors, are estimated through a collective tensor factorization with factors sharing. We introduce three tensor decompositions that significantly reduce the number of parameters and show how they can be efficiently implemented by hierarchical neural networks. We empirically demonstrate that $\Pi$-Nets are very expressive and they even produce good results without the use of non-linear activation functions in a large battery of tasks and signals, i.e., images, graphs, and audio. When used in conjunction with activation functions, $\Pi$-Nets produce state-of-the-art results in three challenging tasks, i.e. image generation, face verification and 3D mesh representation learning.
Improving Graph Neural Network Expressivity via Subgraph Isomorphism Counting
Jun 16, 2020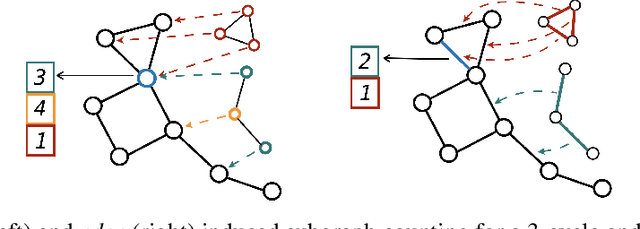
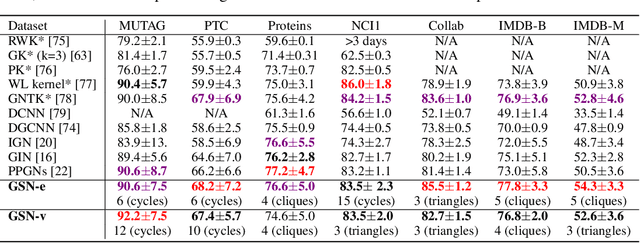
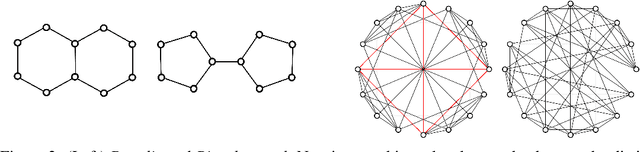
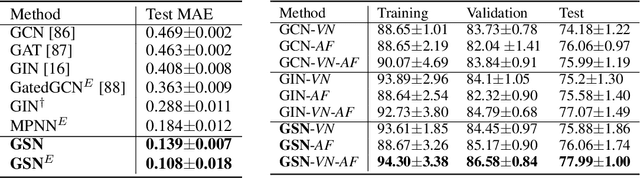
While Graph Neural Networks (GNNs) have achieved remarkable results in a variety of applications, recent studies exposed important shortcomings in their ability to capture the structure of the underlying graph. It has been shown that the expressive power of standard GNNs is bounded by the Weisfeiler-Lehman (WL) graph isomorphism test, from which they inherit proven limitations such as the inability to detect and count graph substructures. On the other hand, there is significant empirical evidence, e.g. in network science and bioinformatics, that substructures are often informative for downstream tasks, suggesting that it is desirable to design GNNs capable of leveraging this important source of information. To this end, we propose a novel topologically-aware message passing scheme based on subgraph isomorphism counting. We show that our architecture allows incorporating domain-specific inductive biases and that it is strictly more expressive than the WL test. Importantly, in contrast to recent works on the expressivity of GNNs, we do not attempt to adhere to the WL hierarchy; this allows us to retain multiple attractive properties of standard GNNs such as locality and linear complexity, while being able to disambiguate even hard instances of graph isomorphism. We extensively evaluate our method on graph classification and regression tasks and show state-of-the-art results on multiple datasets including molecular graphs and social networks.
ReenactNet: Real-time Full Head Reenactment
May 22, 2020Video-to-video synthesis is a challenging problem aiming at learning a translation function between a sequence of semantic maps and a photo-realistic video depicting the characteristics of a driving video. We propose a head-to-head system of our own implementation capable of fully transferring the human head 3D pose, facial expressions and eye gaze from a source to a target actor, while preserving the identity of the target actor. Our system produces high-fidelity, temporally-smooth and photo-realistic synthetic videos faithfully transferring the human time-varying head attributes from the source to the target actor. Our proposed implementation: 1) works in real time ($\sim 20$ fps), 2) runs on a commodity laptop with a webcam as the only input, 3) is interactive, allowing the participant to drive a target person, e.g. a celebrity, politician, etc, instantly by varying their expressions, head pose, and eye gaze, and visualising the synthesised video concurrently.