 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogate Assisted Generation of Human-Robot Interaction Scenarios
May 11, 2023



As human-robot interaction (HRI) systems advance, so does the difficulty of evaluating and understanding the strengths and limitations of these systems in different environments and with different users. To this end, previous methods have algorithmically generated diverse scenarios that reveal system failures in a shared control teleoperation task. However, these methods require directly evaluating generated scenarios by simulating robot policies and human actions. The computational cost of these evaluations limits their applicability in more complex domains. Thus, we propose augmenting scenario generation systems with surrogate models that predict both human and robot behaviors. In the shared control teleoperation domain and a more complex shared workspace collaboration task, we show that surrogate assisted scenario generation efficiently synthesizes diverse datasets of challenging scenarios. We demonstrate that these failures are reproducible in real-world interactions.
pyribs: A Bare-Bones Python Library for Quality Diversity Optimization
Mar 01, 2023



Recent years have seen a rise in the popularity of quality diversity (QD) optimization, a branch of optimization that seeks to find a collection of diverse, high-performing solutions to a given problem. To grow further, we believe the QD community faces two challenges: developing a framework to represent the field's growing array of algorithms, and implementing that framework in software that supports a range of researchers and practitioners. To address these challenges, we have developed pyribs, a library built on a highly modular conceptual QD framework. By replacing components in the conceptual framework, and hence in pyribs, users can compose algorithms from across the QD literature; equally important, they can identify unexplored algorithm variations. Furthermore, pyribs makes this framework simple, flexible, and accessible, with a user-friendly API supported by extensive documentation and tutorials. This paper overviews the creation of pyribs, focusing on the conceptual framework that it implements and the design principles that have guided the library's development.
PATO: Policy Assisted TeleOperation for Scalable Robot Data Collection
Dec 09, 2022Large-scale data is an essential component of machine learning as demonstrated in recent advances in natural language processing and computer vision research. However, collecting large-scale robotic data is much more expensive and slower as each operator can control only a single robot at a time. To make this costly data collection process efficient and scalable, we propose Policy Assisted TeleOperation (PATO), a system which automates part of the demonstration collection process using a learned assistive policy. PATO autonomously executes repetitive behaviors in data collection and asks for human input only when it is uncertain about which subtask or behavior to execute. We conduct teleoperation user studies both with a real robot and a simulated robot fleet and demonstrate that our assisted teleoperation system reduces human operators' mental load while improving data collection efficiency. Further, it enables a single operator to control multiple robots in parallel, which is a first step towards scalable robotic data collection. For code and video results, see https://clvrai.com/pato
Training Diverse High-Dimensional Controllers by Scaling Covariance Matrix Adaptation MAP-Annealing
Oct 06, 2022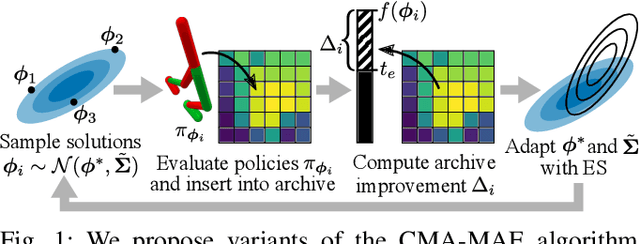

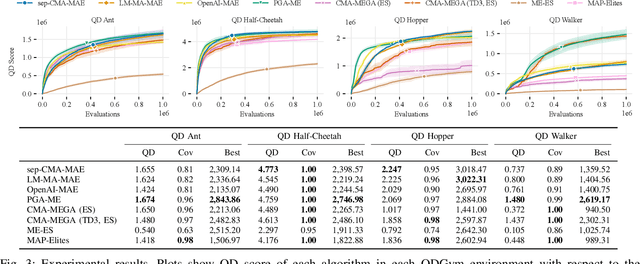
Pre-training a diverse set of robot controllers in simulation has enabled robots to adapt online to damage in robot locomotion tasks. However, finding diverse, high-performing controllers requires specialized hardware and extensive tuning of a large number of hyperparameters. On the other hand, the Covariance Matrix Adaptation MAP-Annealing algorithm, an evolution strategies (ES)-based quality diversity algorithm, does not have these limitations and has been shown to achieve state-of-the-art performance in standard benchmark domains. However, CMA-MAE cannot scale to modern neural network controllers due to its quadratic complexity. We leverage efficient approximation methods in ES to propose three new CMA-MAE variants that scale to very high dimensions. Our experiments show that the variants outperform ES-based baselines in benchmark robotic locomotion tasks, while being comparable with state-of-the-art deep reinforcement learning-based quality diversity algorithms. Source code and videos are available at https://scalingcmamae.github.io
Human Decision Makings on Curriculum Reinforcement Learning with Difficulty Adjustment
Aug 04, 2022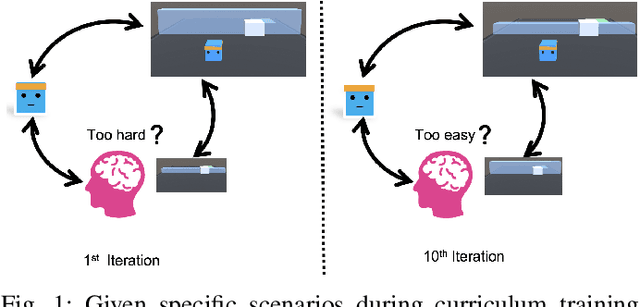
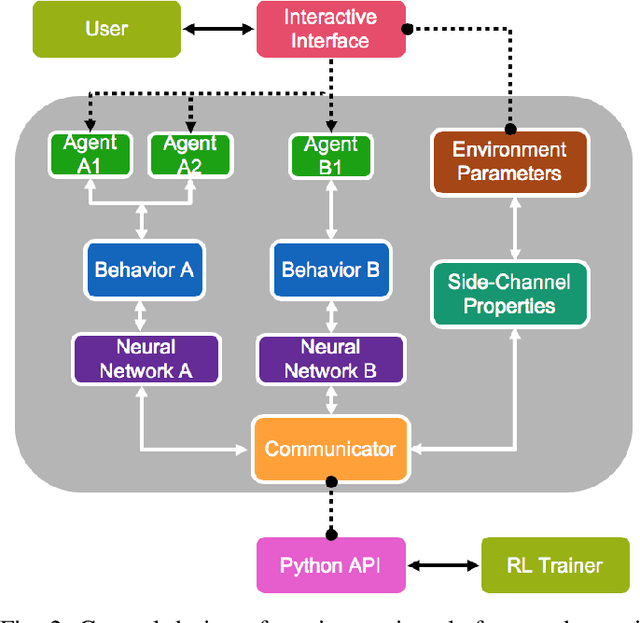
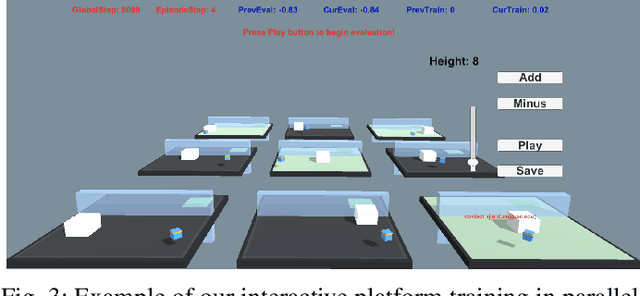
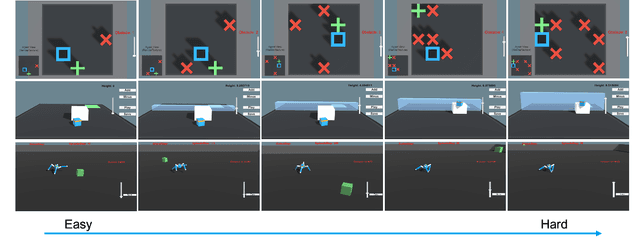
Human-centered AI considers human experiences with AI performance. While abundant research has been helping AI achieve superhuman performance either by fully automatic or weak supervision learning, fewer endeavors are experimenting with how AI can tailor to humans' preferred skill level given fine-grained input. In this work, we guide the curriculum reinforcement learning results towards a preferred performance level that is neither too hard nor too easy via learning from the human decision process. To achieve this, we developed a portable, interactive platform that enables the user to interact with agents online via manipulating the task difficulty, observing performance, and providing curriculum feedback. Our system is highly parallelizable, making it possible for a human to train large-scale reinforcement learning applications that require millions of samples without a server. The result demonstrates the effectiveness of an interactive curriculum for reinforcement learning involving human-in-the-loop. It shows reinforcement learning performance can successfully adjust in sync with the human desired difficulty level. We believe this research will open new doors for achieving flow and personalized adaptive difficulties.
Generating Diverse Indoor Furniture Arrangements
Jun 20, 2022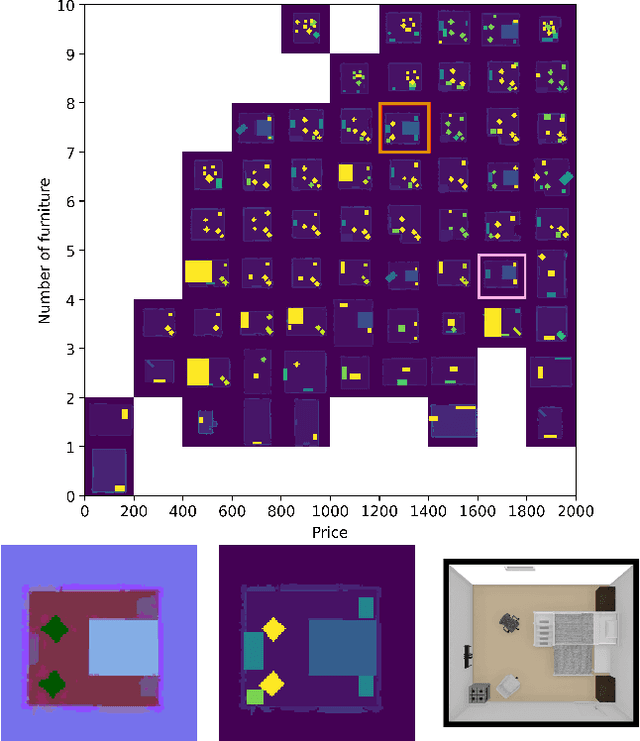

We present a method for generating arrangements of indoor furniture from human-designed furniture layout data. Our method creates arrangements that target specified diversity, such as the total price of all furniture in the room and the number of pieces placed. To generate realistic furniture arrangement, we train a generative adversarial network (GAN) on human-designed layouts. To target specific diversity in the arrangements, we optimize the latent space of the GAN via a quality diversity algorithm to generate a diverse arrangement collection. Experiments show our approach discovers a set of arrangements that are similar to human-designed layouts but varies in price and number of furniture pieces.
Deep Surrogate Assisted Generation of Environments
Jun 14, 2022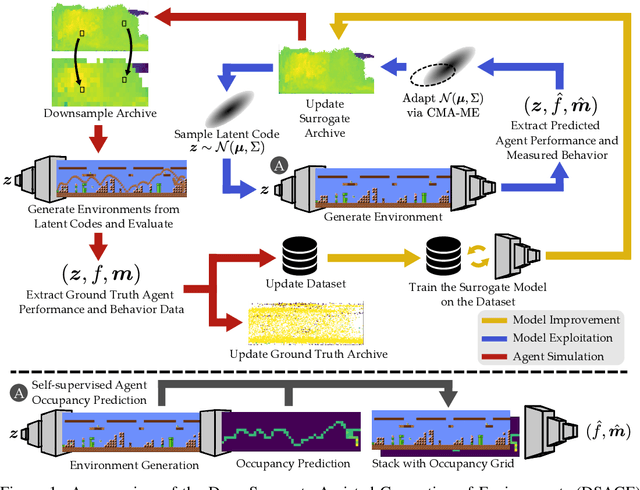
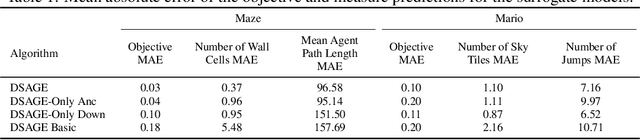
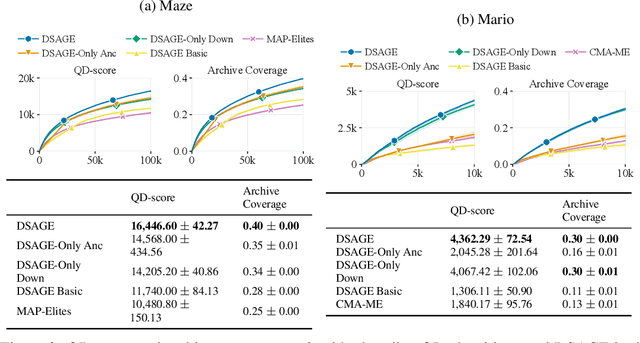

Recent progress in reinforcement learning (RL) has started producing generally capable agents that can solve a distribution of complex environments. These agents are typically tested on fixed, human-authored environments. On the other hand, quality diversity (QD) optimization has been proven to be an effective component of environment generation algorithms, which can generate collections of high-quality environments that are diverse in the resulting agent behaviors. However, these algorithms require potentially expensive simulations of agents on newly generated environments. We propose Deep Surrogate Assisted Generation of Environments (DSAGE), a sample-efficient QD environment generation algorithm that maintains a deep surrogate model for predicting agent behaviors in new environments. Results in two benchmark domains show that DSAGE significantly outperforms existing QD environment generation algorithms in discovering collections of environments that elicit diverse behaviors of a state-of-the-art RL agent and a planning agent.
Covariance Matrix Adaptation MAP-Annealing
May 22, 2022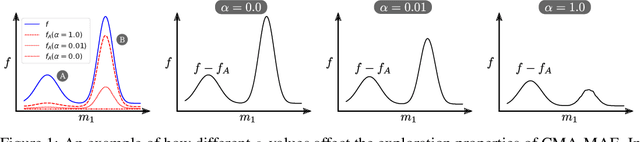

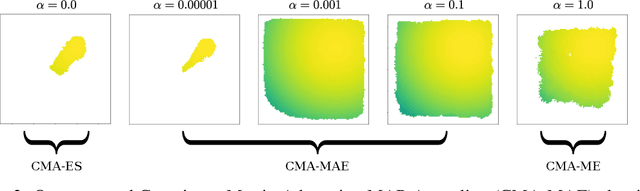
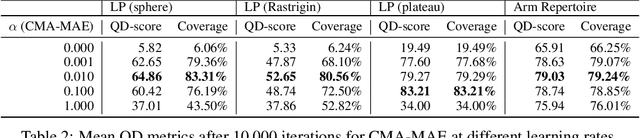
Single-objective optimization algorithms search for the single highest-quality solution with respect to an objective. In contrast, quality diversity (QD) optimization algorithms, such as Covariance Matrix Adaptation MAP-Elites (CMA-ME), search for a collection of solutions that are both high-quality with respect to an objective and diverse with respect to specified measure functions. We propose a new quality diversity algorithm, Covariance Matrix Adaptation MAP-Annealing (CMA-MAE), which bridges the gap between single-objective optimization and QD optimization. We prove that CMA-MAE smoothly blends between the Covariance Matrix Adaptation Evolution Strategy (CMA-ES) single-objective optimizer and CMA-ME by gradually annealing a discount function with a scalar learning rate. We show that CMA-MAE has better performance than the current state-of-the-art QD algorithms on several benchmark domains and that its performance is empirically invariant to the archive resolution and robust to the discount function learning rate.
Learning Performance Graphs from Demonstrations via Task-Based Evaluations
Apr 12, 2022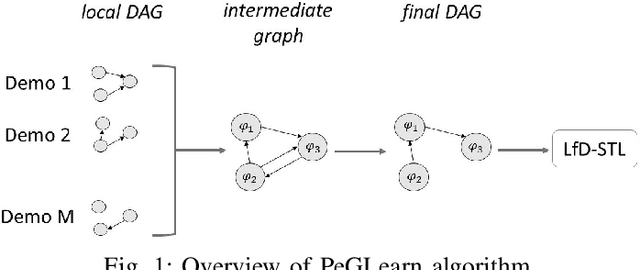
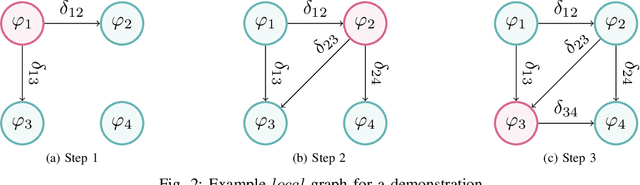
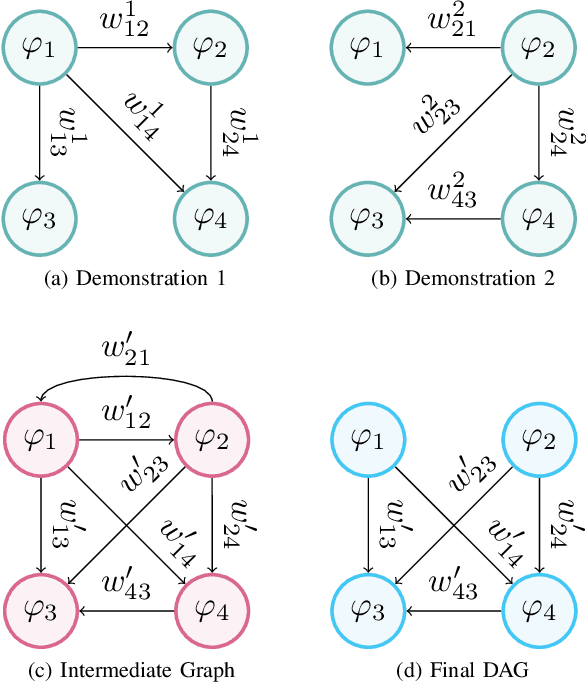
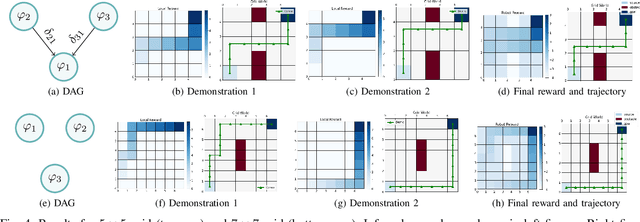
In the learning from demonstration (LfD) paradigm, understanding and evaluating the demonstrated behaviors plays a critical role in extracting control policies for robots. Without this knowledge, a robot may infer incorrect reward functions that lead to undesirable or unsafe control policies. Recent work has proposed an LfD framework where a user provides a set of formal task specifications to guide LfD, to address the challenge of reward shaping. However, in this framework, specifications are manually ordered in a performance graph (a partial order that specifies relative importance between the specifications). The main contribution of this paper is an algorithm to learn the performance graph directly from the user-provided demonstrations, and show that the reward functions generated using the learned performance graph generate similar policies to those from manually specified performance graphs. We perform a user study that shows that priorities specified by users on behaviors in a simulated highway driving domain match the automatically inferred performance graph. This establishes that we can accurately evaluate user demonstrations with respect to task specifications without expert criteria.
Approximating Gradients for Differentiable Quality Diversity in Reinforcement Learning
Feb 08, 2022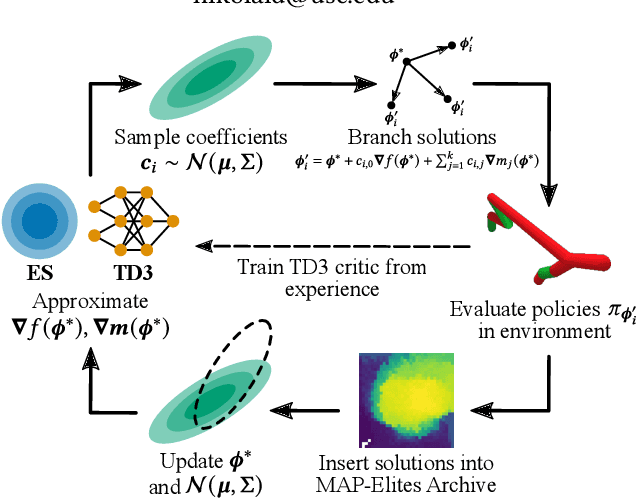

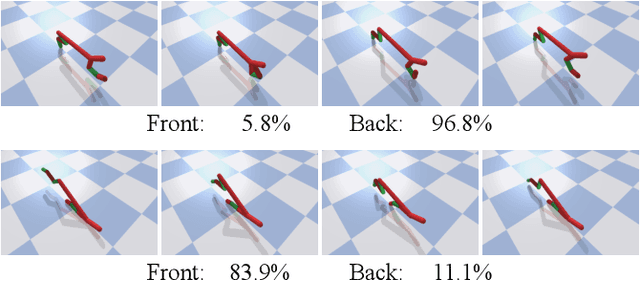
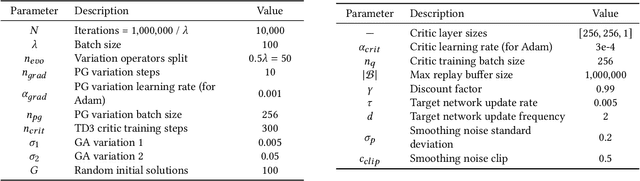
Consider a walking agent that must adapt to damage. To approach this task, we can train a collection of policies and have the agent select a suitable policy when damaged. Training this collection may be viewed as a quality diversity (QD) optimization problem, where we search for solutions (policies) which maximize an objective (walking forward) while spanning a set of measures (measurable characteristics). Recent work shows that differentiable quality diversity (DQD) algorithms greatly accelerate QD optimization when exact gradients are available for the objective and measures. However, such gradients are typically unavailable in RL settings due to non-differentiable environments. To apply DQD in RL settings, we propose to approximate objective and measure gradients with evolution strategies and actor-critic methods. We develop two variants of the DQD algorithm CMA-MEGA, each with different gradient approximations, and evaluate them on four simulated walking tasks. One variant achieves comparable performance (QD score) with the state-of-the-art PGA-MAP-Elites in two tasks. The other variant performs comparably in all tasks but is less efficient than PGA-MAP-Elites in two tasks. These results provide insight into the limitations of CMA-MEGA in domains that require rigorous optimization of the objective and where exact gradients are unavailable.