 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Learning Patterns in Financial Time-Series for Trend-Following Strategies
Oct 16, 2023



Forecasting models for systematic trading strategies do not adapt quickly when financial market conditions change, as was seen in the advent of the COVID-19 pandemic in 2020, when market conditions changed dramatically causing many forecasting models to take loss-making positions. To deal with such situations, we propose a novel time-series trend-following forecaster that is able to quickly adapt to new market conditions, referred to as regimes. We leverage recent developments from the deep learning community and use few-shot learning. We propose the Cross Attentive Time-Series Trend Network - X-Trend - which takes positions attending over a context set of financial time-series regimes. X-Trend transfers trends from similar patterns in the context set to make predictions and take positions for a new distinct target regime. X-Trend is able to quickly adapt to new financial regimes with a Sharpe ratio increase of 18.9% over a neural forecaster and 10-fold over a conventional Time-series Momentum strategy during the turbulent market period from 2018 to 2023. Our strategy recovers twice as quickly from the COVID-19 drawdown compared to the neural-forecaster. X-Trend can also take zero-shot positions on novel unseen financial assets obtaining a 5-fold Sharpe ratio increase versus a neural time-series trend forecaster over the same period. X-Trend both forecasts next-day prices and outputs a trading signal. Furthermore, the cross-attention mechanism allows us to interpret the relationship between forecasts and patterns in the context set.
JAX-LOB: A GPU-Accelerated limit order book simulator to unlock large scale reinforcement learning for trading
Aug 25, 2023



Financial exchanges across the world use limit order books (LOBs) to process orders and match trades. For research purposes it is important to have large scale efficient simulators of LOB dynamics. LOB simulators have previously been implemented in the context of agent-based models (ABMs), reinforcement learning (RL) environments, and generative models, processing order flows from historical data sets and hand-crafted agents alike. For many applications, there is a requirement for processing multiple books, either for the calibration of ABMs or for the training of RL agents. We showcase the first GPU-enabled LOB simulator designed to process thousands of books in parallel, with a notably reduced per-message processing time. The implementation of our simulator - JAX-LOB - is based on design choices that aim to best exploit the powers of JAX without compromising on the realism of LOB-related mechanisms. We integrate JAX-LOB with other JAX packages, to provide an example of how one may address an optimal execution problem with reinforcement learning, and to share some preliminary results from end-to-end RL training on GPUs.
Generative AI for End-to-End Limit Order Book Modelling: A Token-Level Autoregressive Generative Model of Message Flow Using a Deep State Space Network
Aug 23, 2023Developing a generative model of realistic order flow in financial markets is a challenging open problem, with numerous applications for market participants. Addressing this, we propose the first end-to-end autoregressive generative model that generates tokenized limit order book (LOB) messages. These messages are interpreted by a Jax-LOB simulator, which updates the LOB state. To handle long sequences efficiently, the model employs simplified structured state-space layers to process sequences of order book states and tokenized messages. Using LOBSTER data of NASDAQ equity LOBs, we develop a custom tokenizer for message data, converting groups of successive digits to tokens, similar to tokenization in large language models. Out-of-sample results show promising performance in approximating the data distribution, as evidenced by low model perplexity. Furthermore, the mid-price returns calculated from the generated order flow exhibit a significant correlation with the data, indicating impressive conditional forecast performance. Due to the granularity of generated data, and the accuracy of the model, it offers new application areas for future work beyond forecasting, e.g. acting as a world model in high-frequency financial reinforcement learning applications. Overall, our results invite the use and extension of the model in the direction of autoregressive large financial models for the generation of high-frequency financial data and we commit to open-sourcing our code to facilitate future research.
Learning to Learn Financial Networks for Optimising Momentum Strategies
Aug 23, 2023Network momentum provides a novel type of risk premium, which exploits the interconnections among assets in a financial network to predict future returns. However, the current process of constructing financial networks relies heavily on expensive databases and financial expertise, limiting accessibility for small-sized and academic institutions. Furthermore, the traditional approach treats network construction and portfolio optimisation as separate tasks, potentially hindering optimal portfolio performance. To address these challenges, we propose L2GMOM, an end-to-end machine learning framework that simultaneously learns financial networks and optimises trading signals for network momentum strategies. The model of L2GMOM is a neural network with a highly interpretable forward propagation architecture, which is derived from algorithm unrolling. The L2GMOM is flexible and can be trained with diverse loss functions for portfolio performance, e.g. the negative Sharpe ratio. Backtesting on 64 continuous future contracts demonstrates a significant improvement in portfolio profitability and risk control, with a Sharpe ratio of 1.74 across a 20-year period.
Network Momentum across Asset Classes
Aug 22, 2023We investigate the concept of network momentum, a novel trading signal derived from momentum spillover across assets. Initially observed within the confines of pairwise economic and fundamental ties, such as the stock-bond connection of the same company and stocks linked through supply-demand chains, momentum spillover implies a propagation of momentum risk premium from one asset to another. The similarity of momentum risk premium, exemplified by co-movement patterns, has been spotted across multiple asset classes including commodities, equities, bonds and currencies. However, studying the network effect of momentum spillover across these classes has been challenging due to a lack of readily available common characteristics or economic ties beyond the company level. In this paper, we explore the interconnections of momentum features across a diverse range of 64 continuous future contracts spanning these four classes. We utilise a linear and interpretable graph learning model with minimal assumptions to reveal the intricacies of the momentum spillover network. By leveraging the learned networks, we construct a network momentum strategy that exhibits a Sharpe ratio of 1.5 and an annual return of 22%, after volatility scaling, from 2000 to 2022. This paper pioneers the examination of momentum spillover across multiple asset classes using only pricing data, presents a multi-asset investment strategy based on network momentum, and underscores the effectiveness of this strategy through robust empirical analysis.
Robust Detection of Lead-Lag Relationships in Lagged Multi-Factor Models
May 11, 2023



In multivariate time series systems, key insights can be obtained by discovering lead-lag relationships inherent in the data, which refer to the dependence between two time series shifted in time relative to one another, and which can be leveraged for the purposes of control, forecasting or clustering. We develop a clustering-driven methodology for the robust detection of lead-lag relationships in lagged multi-factor models. Within our framework, the envisioned pipeline takes as input a set of time series, and creates an enlarged universe of extracted subsequence time series from each input time series, by using a sliding window approach. We then apply various clustering techniques (e.g, K-means++ and spectral clustering), employing a variety of pairwise similarity measures, including nonlinear ones. Once the clusters have been extracted, lead-lag estimates across clusters are aggregated to enhance the identification of the consistent relationships in the original universe. Since multivariate time series are ubiquitous in a wide range of domains, we demonstrate that our method is not only able to robustly detect lead-lag relationships in financial markets, but can also yield insightful results when applied to an environmental data set.
Spatio-Temporal Momentum: Jointly Learning Time-Series and Cross-Sectional Strategies
Feb 20, 2023



We introduce Spatio-Temporal Momentum strategies, a class of models that unify both time-series and cross-sectional momentum strategies by trading assets based on their cross-sectional momentum features over time. While both time-series and cross-sectional momentum strategies are designed to systematically capture momentum risk premia, these strategies are regarded as distinct implementations and do not consider the concurrent relationship and predictability between temporal and cross-sectional momentum features of different assets. We model spatio-temporal momentum with neural networks of varying complexities and demonstrate that a simple neural network with only a single fully connected layer learns to simultaneously generate trading signals for all assets in a portfolio by incorporating both their time-series and cross-sectional momentum features. Backtesting on portfolios of 46 actively-traded US equities and 12 equity index futures contracts, we demonstrate that the model is able to retain its performance over benchmarks in the presence of high transaction costs of up to 5-10 basis points. In particular, we find that the model when coupled with least absolute shrinkage and turnover regularization results in the best performance over various transaction cost scenarios.
Asynchronous Deep Double Duelling Q-Learning for Trading-Signal Execution in Limit Order Book Markets
Jan 20, 2023



We employ deep reinforcement learning (RL) to train an agent to successfully translate a high-frequency trading signal into a trading strategy that places individual limit orders. Based on the ABIDES limit order book simulator, we build a reinforcement learning OpenAI gym environment and utilise it to simulate a realistic trading environment for NASDAQ equities based on historic order book messages. To train a trading agent that learns to maximise its trading return in this environment, we use Deep Duelling Double Q-learning with the APEX (asynchronous prioritised experience replay) architecture. The agent observes the current limit order book state, its recent history, and a short-term directional forecast. To investigate the performance of RL for adaptive trading independently from a concrete forecasting algorithm, we study the performance of our approach utilising synthetic alpha signals obtained by perturbing forward-looking returns with varying levels of noise. Here, we find that the RL agent learns an effective trading strategy for inventory management and order placing that outperforms a heuristic benchmark trading strategy having access to the same signal.
On Sequential Bayesian Inference for Continual Learning
Jan 04, 2023



Sequential Bayesian inference can be used for continual learning to prevent catastrophic forgetting of past tasks and provide an informative prior when learning new tasks. We revisit sequential Bayesian inference and test whether having access to the true posterior is guaranteed to prevent catastrophic forgetting in Bayesian neural networks. To do this we perform sequential Bayesian inference using Hamiltonian Monte Carlo. We propagate the posterior as a prior for new tasks by fitting a density estimator on Hamiltonian Monte Carlo samples. We find that this approach fails to prevent catastrophic forgetting demonstrating the difficulty in performing sequential Bayesian inference in neural networks. From there we study simple analytical examples of sequential Bayesian inference and CL and highlight the issue of model misspecification which can lead to sub-optimal continual learning performance despite exact inference. Furthermore, we discuss how task data imbalances can cause forgetting. From these limitations, we argue that we need probabilistic models of the continual learning generative process rather than relying on sequential Bayesian inference over Bayesian neural network weights. In this vein, we also propose a simple baseline called Prototypical Bayesian Continual Learning, which is competitive with state-of-the-art Bayesian continual learning methods on class incremental continual learning vision benchmarks.
DeepVol: Volatility Forecasting from High-Frequency Data with Dilated Causal Convolutions
Sep 23, 2022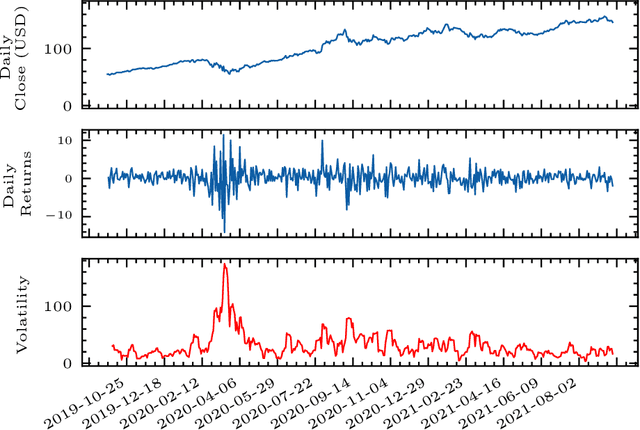
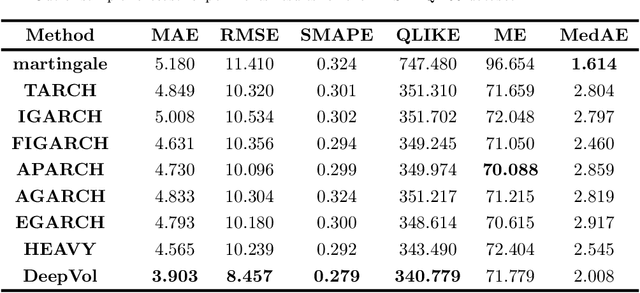
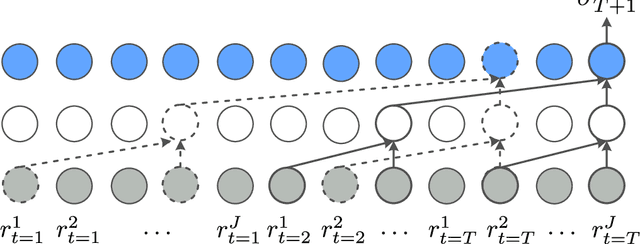
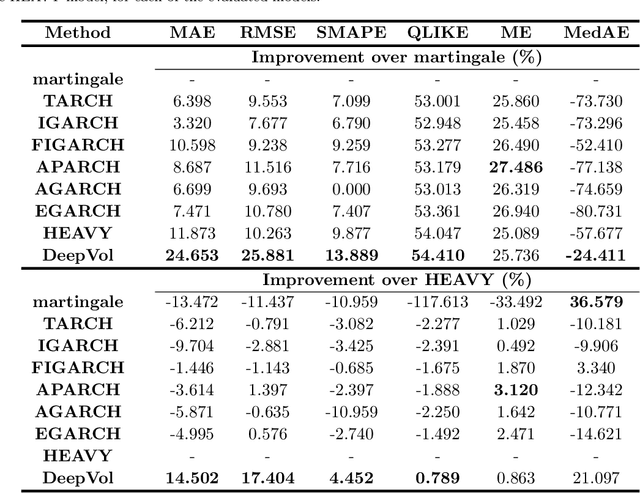
Volatility forecasts play a central role among equity risk measures. Besides traditional statistical models, modern forecasting techniques, based on machine learning, can readily be employed when treating volatility as a univariate, daily time-series. However, econometric studies have shown that increasing the number of daily observations with high-frequency intraday data helps to improve predictions. In this work, we propose DeepVol, a model based on Dilated Causal Convolutions to forecast day-ahead volatility by using high-frequency data. We show that the dilated convolutional filters are ideally suited to extract relevant information from intraday financial data, thereby naturally mimicking (via a data-driven approach) the econometric models which incorporate realised measures of volatility into the forecast. This allows us to take advantage of the abundance of intraday observations, helping us to avoid the limitations of models that use daily data, such as model misspecification or manually designed handcrafted features, whose devise involves optimising the trade-off between accuracy and computational efficiency and makes models prone to lack of adaptation into changing circumstances. In our analysis, we use two years of intraday data from NASDAQ-100 to evaluate DeepVol's performance. The reported empirical results suggest that the proposed deep learning-based approach learns global features from high-frequency data, achieving more accurate predictions than traditional methodologies, yielding to more appropriate risk measures.