 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Normalizing Flows for Many-to-Many Cross-Domain Mappings
Feb 16, 2020
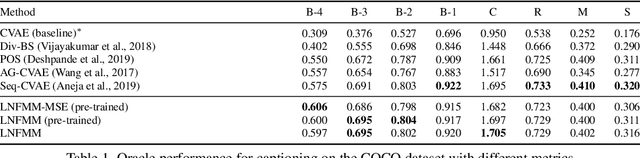
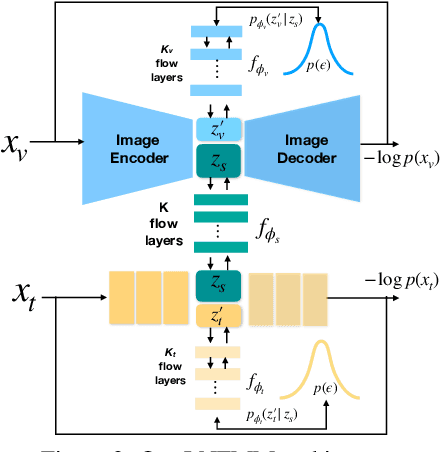
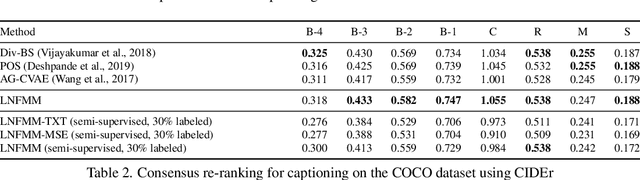
Learned joint representations of images and text form the backbone of several important cross-domain tasks such as image captioning. Prior work mostly maps both domains into a common latent representation in a purely supervised fashion. This is rather restrictive, however, as the two domains follow distinct generative processes. Therefore, we propose a novel semi-supervised framework, which models shared information between domains and domain-specific information separately. The information shared between the domains is aligned with an invertible neural network. Our model integrates normalizing flow-based priors for the domain-specific information, which allows us to learn diverse many-to-many mappings between the two domains. We demonstrate the effectiveness of our model on diverse tasks, including image captioning and text-to-image synthesis.
Driving Style Encoder: Situational Reward Adaptation for General-Purpose Planning in Automated Driving
Dec 07, 2019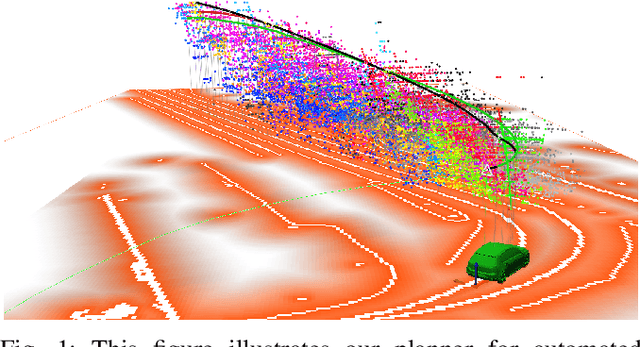

General-purpose planning algorithms for automated driving combine mission, behavior, and local motion planning. Such planning algorithms map features of the environment and driving kinematics into complex reward functions. To achieve this, planning experts often rely on linear reward functions. The specification and tuning of these reward functions is a tedious process and requires significant experience. Moreover, a manually designed linear reward function does not generalize across different driving situations. In this work, we propose a deep learning approach based on inverse reinforcement learning that generates situation-dependent reward functions. Our neural network provides a mapping between features and actions of sampled driving policies of a model-predictive control-based planner and predicts reward functions for upcoming planning cycles. In our evaluation, we compare the driving style of reward functions predicted by our deep network against clustered and linear reward functions. Our proposed deep learning approach outperforms clustered linear reward functions and is at par with linear reward functions with a-priori knowledge about the situation.
Markov Decision Process for Video Generation
Sep 26, 2019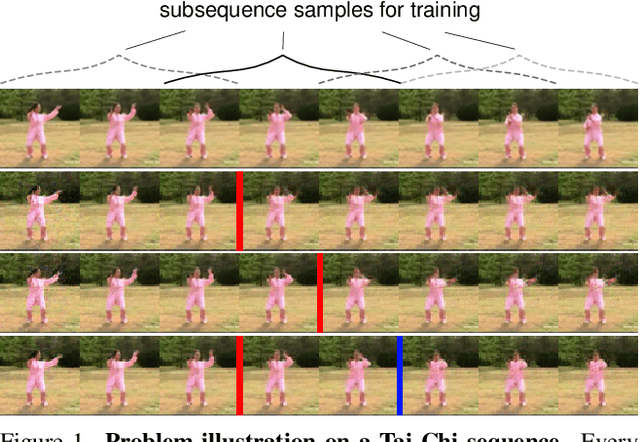
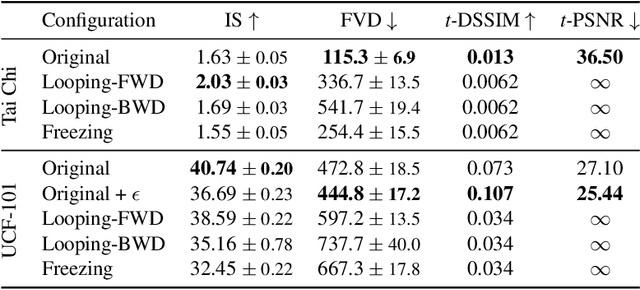
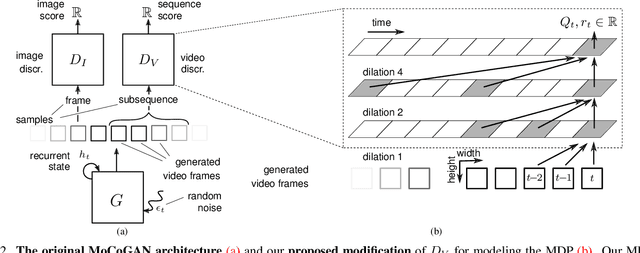

We identify two pathological cases of temporal inconsistencies in video generation: video freezing and video looping. To better quantify the temporal diversity, we propose a class of complementary metrics that are effective, easy to implement, data agnostic, and interpretable. Further, we observe that current state-of-the-art models are trained on video samples of fixed length thereby inhibiting long-term modeling. To address this, we reformulate the problem of video generation as a Markov Decision Process (MDP). The underlying idea is to represent motion as a stochastic process with an infinite forecast horizon to overcome the fixed length limitation and to mitigate the presence of temporal artifacts. We show that our formulation is easy to integrate into the state-of-the-art MoCoGAN framework. Our experiments on the Human Actions and UCF-101 datasets demonstrate that our MDP-based model is more memory efficient and improves the video quality both in terms of the new and established metrics.
Deep Video Deblurring: The Devil is in the Details
Sep 26, 2019
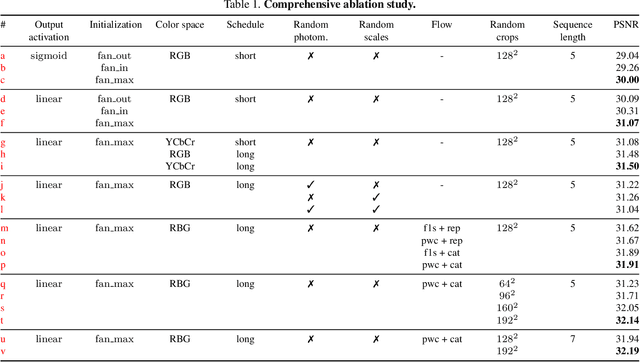
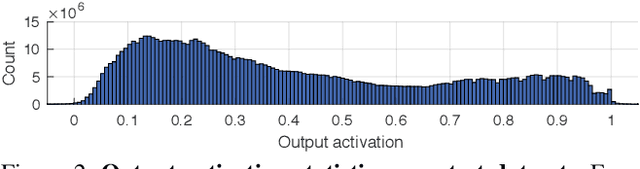
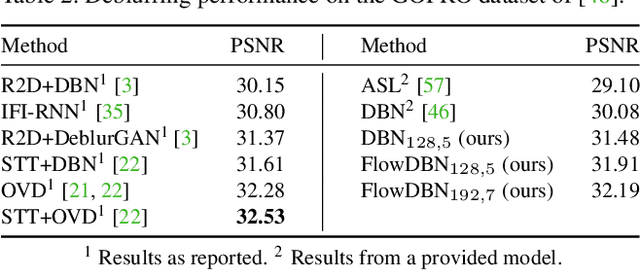
Video deblurring for hand-held cameras is a challenging task, since the underlying blur is caused by both camera shake and object motion. State-of-the-art deep networks exploit temporal information from neighboring frames, either by means of spatio-temporal transformers or by recurrent architectures. In contrast to these involved models, we found that a simple baseline CNN can perform astonishingly well when particular care is taken w.r.t. the details of model and training procedure. To that end, we conduct a comprehensive study regarding these crucial details, uncovering extreme differences in quantitative and qualitative performance. Exploiting these details allows us to boost the architecture and training procedure of a simple baseline CNN by a staggering 3.15dB, such that it becomes highly competitive w.r.t. cutting-edge networks. This raises the question whether the reported accuracy difference between models is always due to technical contributions or also subject to such orthogonal, but crucial details.
Joint Wasserstein Autoencoders for Aligning Multimodal Embeddings
Sep 14, 2019



One of the key challenges in learning joint embeddings of multiple modalities, e.g. of images and text, is to ensure coherent cross-modal semantics that generalize across datasets. We propose to address this through joint Gaussian regularization of the latent representations. Building on Wasserstein autoencoders (WAEs) to encode the input in each domain, we enforce the latent embeddings to be similar to a Gaussian prior that is shared across the two domains, ensuring compatible continuity of the encoded semantic representations of images and texts. Semantic alignment is achieved through supervision from matching image-text pairs. To show the benefits of our semi-supervised representation, we apply it to cross-modal retrieval and phrase localization. We not only achieve state-of-the-art accuracy, but significantly better generalization across datasets, owing to the semantic continuity of the latent space.
Learning Task-Specific Generalized Convolutions in the Permutohedral Lattice
Sep 09, 2019



Dense prediction tasks typically employ encoder-decoder architectures, but the prevalent convolutions in the decoder are not image-adaptive and can lead to boundary artifacts. Different generalized convolution operations have been introduced to counteract this. We go beyond these by leveraging guidance data to redefine their inherent notion of proximity. Our proposed network layer builds on the permutohedral lattice, which performs sparse convolutions in a high-dimensional space allowing for powerful non-local operations despite small filters. Multiple features with different characteristics span this permutohedral space. In contrast to prior work, we learn these features in a task-specific manner by generalizing the basic permutohedral operations to learnt feature representations. As the resulting objective is complex, a carefully designed framework and learning procedure are introduced, yielding rich feature embeddings in practice. We demonstrate the general applicability of our approach in different joint upsampling tasks. When adding our network layer to state-of-the-art networks for optical flow and semantic segmentation, boundary artifacts are removed and the accuracy is improved.
CVPR19 Tracking and Detection Challenge: How crowded can it get?
Jun 10, 2019
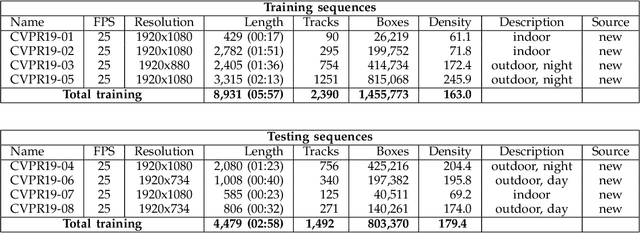

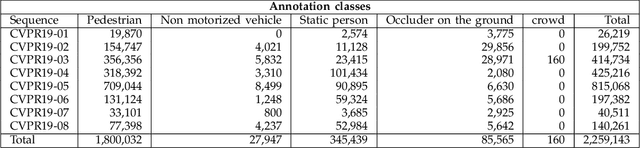
Standardized benchmarks are crucial for the majority of computer vision applications. Although leaderboards and ranking tables should not be over-claimed, benchmarks often provide the most objective measure of performance and are therefore important guides for research. The benchmark for Multiple Object Tracking, MOTChallenge, was launched with the goal to establish a standardized evaluation of multiple object tracking methods. The challenge focuses on multiple people tracking, since pedestrians are well studied in the tracking community, and precise tracking and detection has high practical relevance. Since the first release, MOT15, MOT16 and MOT17 have tremendously contributed to the community by introducing a clean dataset and precise framework to benchmark multi-object trackers. In this paper, we present our CVPR19 benchmark, consisting of 8 new sequences depicting very crowded challenging scenes. The benchmark will be presented at the 4th BMTT MOT Challenge Workshop at the Computer Vision and Pattern Recognition Conference (CVPR) 2019, and will evaluate the state-of-the-art in multiple object tracking whend handling extremely crowded scenarios.
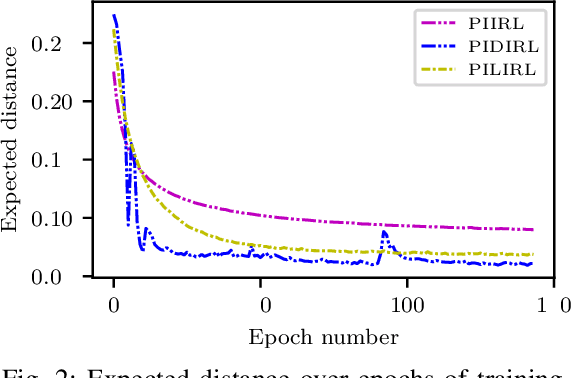
Driving with Style: Inverse Reinforcement Learning in General-Purpose Planning for Automated Driving
May 01, 2019
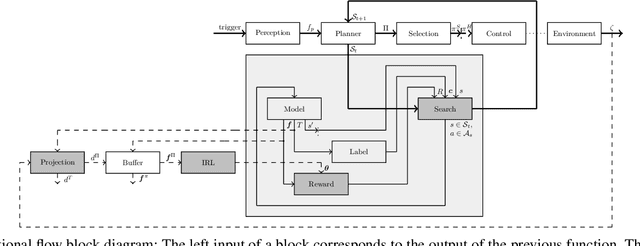
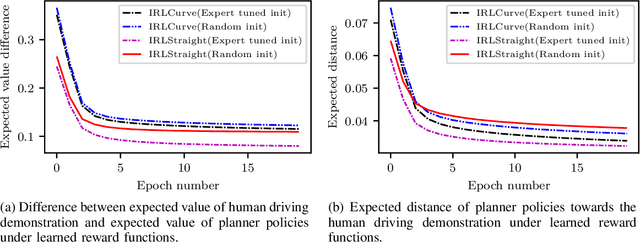
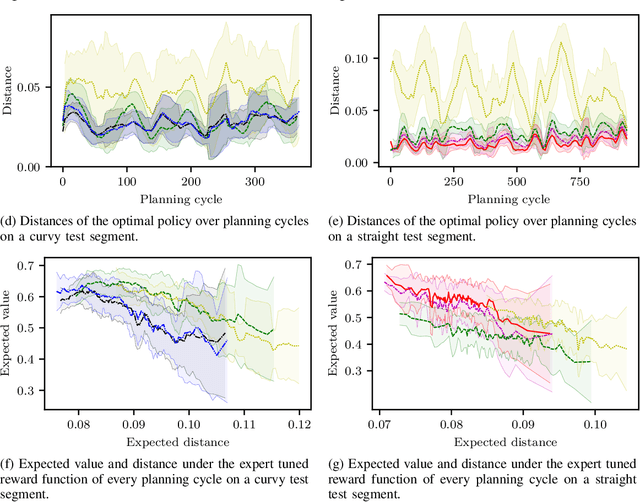
Behavior and motion planning play an important role in automated driving. Traditionally, behavior planners instruct local motion planners with predefined behaviors. Due to the high scene complexity in urban environments, unpredictable situations may occur in which behavior planners fail to match predefined behavior templates. Recently, general-purpose planners have been introduced, combining behavior and local motion planning. These general-purpose planners allow behavior-aware motion planning given a single reward function. However, two challenges arise: First, this function has to map a complex feature space into rewards. Second, the reward function has to be manually tuned by an expert. Manually tuning this reward function becomes a tedious task. In this paper, we propose an approach that relies on human driving demonstrations to automatically tune reward functions. This study offers important insights into the driving style optimization of general-purpose planners with maximum entropy inverse reinforcement learning. We evaluate our approach based on the expected value difference between learned and demonstrated policies. Furthermore, we compare the similarity of human driven trajectories with optimal policies of our planner under learned and expert-tuned reward functions. Our experiments show that we are able to learn reward functions exceeding the level of manual expert tuning without prior domain knowledge.
Iterative Residual Refinement for Joint Optical Flow and Occlusion Estimation
Apr 10, 2019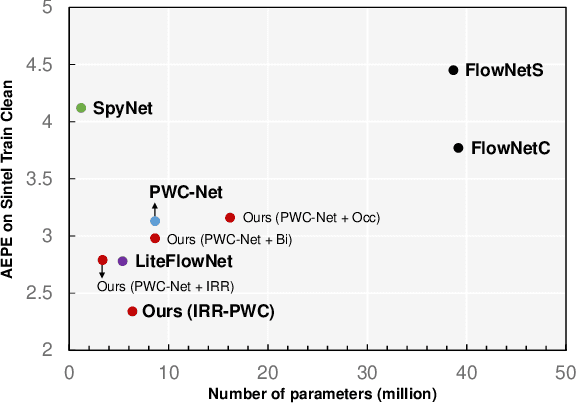
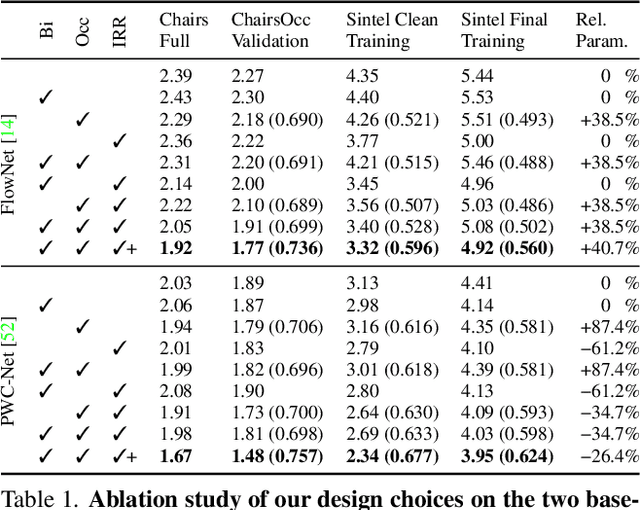
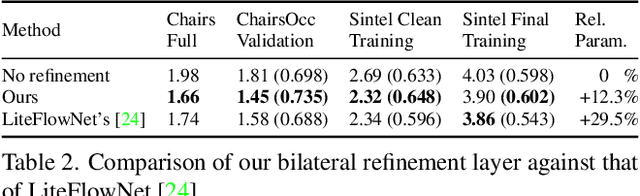
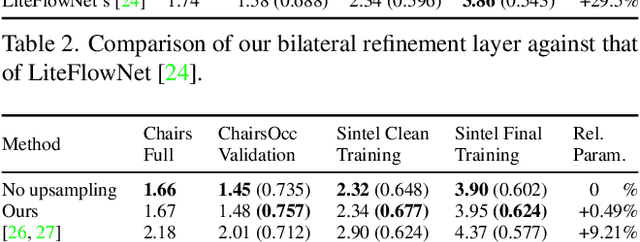
Deep learning approaches to optical flow estimation have seen rapid progress over the recent years. One common trait of many networks is that they refine an initial flow estimate either through multiple stages or across the levels of a coarse-to-fine representation. While leading to more accurate results, the downside of this is an increased number of parameters. Taking inspiration from both classical energy minimization approaches as well as residual networks, we propose an iterative residual refinement (IRR) scheme based on weight sharing that can be combined with several backbone networks. It reduces the number of parameters, improves the accuracy, or even achieves both. Moreover, we show that integrating occlusion prediction and bi-directional flow estimation into our IRR scheme can further boost the accuracy. Our full network achieves state-of-the-art results for both optical flow and occlusion estimation across several standard datasets.
Actor-Critic Instance Segmentation
Apr 10, 2019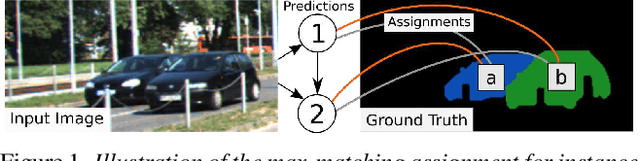

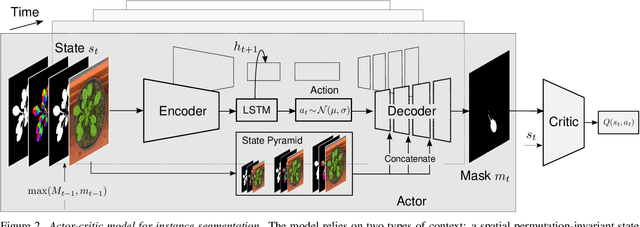
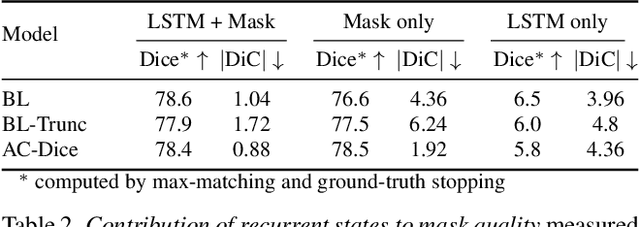
Most approaches to visual scene analysis have emphasised parallel processing of the image elements. However, one area in which the sequential nature of vision is apparent, is that of segmenting multiple, potentially similar and partially occluded objects in a scene. In this work, we revisit the recurrent formulation of this challenging problem in the context of reinforcement learning. Motivated by the limitations of the global max-matching assignment of the ground-truth segments to the recurrent states, we develop an actor-critic approach in which the actor recurrently predicts one instance mask at a time and utilises the gradient from a concurrently trained critic network. We formulate the state, action, and the reward such as to let the critic model long-term effects of the current prediction and incorporate this information into the gradient signal. Furthermore, to enable effective exploration in the inherently high-dimensional action space of instance masks, we learn a compact representation using a conditional variational auto-encoder. We show that our actor-critic model consistently provides accuracy benefits over the recurrent baseline on standard instance segmentation benchmarks.