 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch Community Perspectives on "Intelligence" and Large Language Models
May 27, 2025Despite the widespread use of ''artificial intelligence'' (AI) framing in Natural Language Processing (NLP) research, it is not clear what researchers mean by ''intelligence''. To that end, we present the results of a survey on the notion of ''intelligence'' among researchers and its role in the research agenda. The survey elicited complete responses from 303 researchers from a variety of fields including NLP, Machine Learning (ML), Cognitive Science, Linguistics, and Neuroscience. We identify 3 criteria of intelligence that the community agrees on the most: generalization, adaptability, & reasoning. Our results suggests that the perception of the current NLP systems as ''intelligent'' is a minority position (29%). Furthermore, only 16.2% of the respondents see developing intelligent systems as a research goal, and these respondents are more likely to consider the current systems intelligent.
Reducing annotator bias by belief elicitation
Oct 21, 2024Crowdsourced annotations of data play a substantial role in the development of Artificial Intelligence (AI). It is broadly recognised that annotations of text data can contain annotator bias, where systematic disagreement in annotations can be traced back to differences in the annotators' backgrounds. Being unaware of such annotator bias can lead to representational bias against minority group perspectives and therefore several methods have been proposed for recognising bias or preserving perspectives. These methods typically require either a substantial number of annotators or annotations per data instance. In this study, we propose a simple method for handling bias in annotations without requirements on the number of annotators or instances. Instead, we ask annotators about their beliefs of other annotators' judgements of an instance, under the hypothesis that these beliefs may provide more representative and less biased labels than judgements. The method was examined in two controlled, survey-based experiments involving Democrats and Republicans (n=1,590) asked to judge statements as arguments and then report beliefs about others' judgements. The results indicate that bias, defined as systematic differences between the two groups of annotators, is consistently reduced when asking for beliefs instead of judgements. Our proposed method therefore has the potential to reduce the risk of annotator bias, thereby improving the generalisability of AI systems and preventing harm to unrepresented socio-demographic groups, and we highlight the need for further studies of this potential in other tasks and downstream applications.
Being Right for Whose Right Reasons?
Jun 01, 2023



Explainability methods are used to benchmark the extent to which model predictions align with human rationales i.e., are 'right for the right reasons'. Previous work has failed to acknowledge, however, that what counts as a rationale is sometimes subjective. This paper presents what we think is a first of its kind, a collection of human rationale annotations augmented with the annotators demographic information. We cover three datasets spanning sentiment analysis and common-sense reasoning, and six demographic groups (balanced across age and ethnicity). Such data enables us to ask both what demographics our predictions align with and whose reasoning patterns our models' rationales align with. We find systematic inter-group annotator disagreement and show how 16 Transformer-based models align better with rationales provided by certain demographic groups: We find that models are biased towards aligning best with older and/or white annotators. We zoom in on the effects of model size and model distillation, finding -- contrary to our expectations -- negative correlations between model size and rationale agreement as well as no evidence that either model size or model distillation improves fairness.
What Factors Should Paper-Reviewer Assignments Rely On? Community Perspectives on Issues and Ideals in Conference Peer-Review
May 03, 2022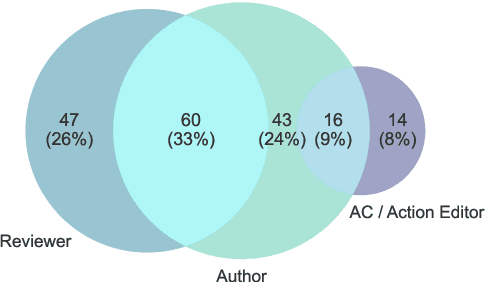
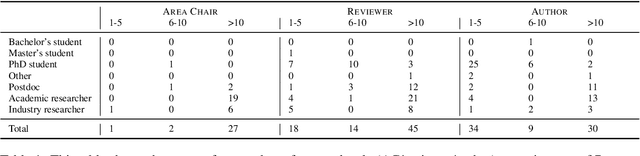
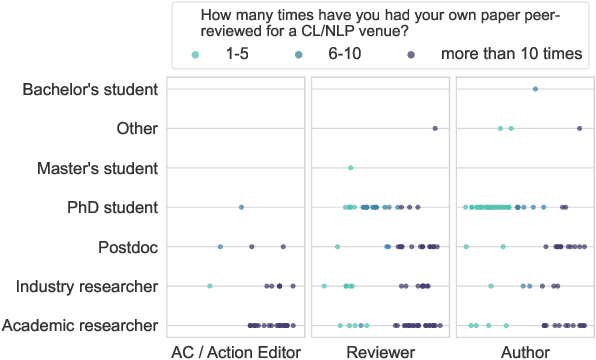

Both scientific progress and individual researcher careers depend on the quality of peer review, which in turn depends on paper-reviewer matching. Surprisingly, this problem has been mostly approached as an automated recommendation problem rather than as a matter where different stakeholders (area chairs, reviewers, authors) have accumulated experience worth taking into account. We present the results of the first survey of the NLP community, identifying common issues and perspectives on what factors should be considered by paper-reviewer matching systems. This study contributes actionable recommendations for improving future NLP conferences, and desiderata for interpretable peer review assignments.