 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Apr 12, 2022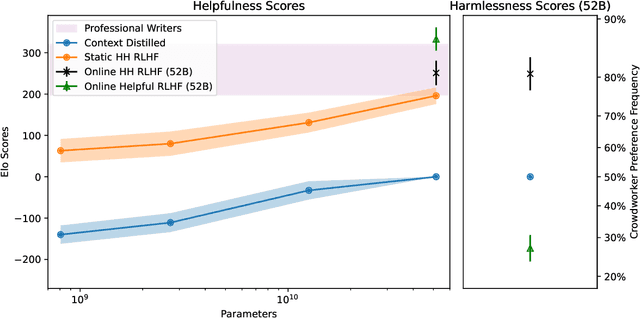
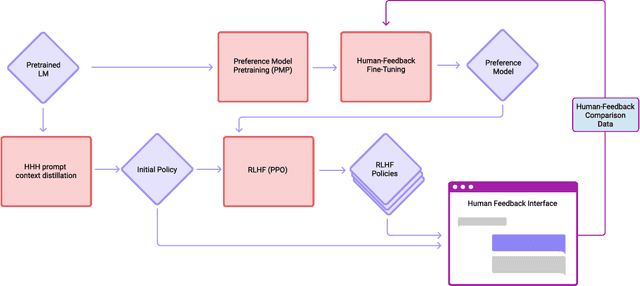
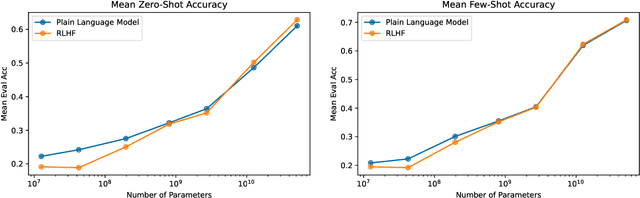
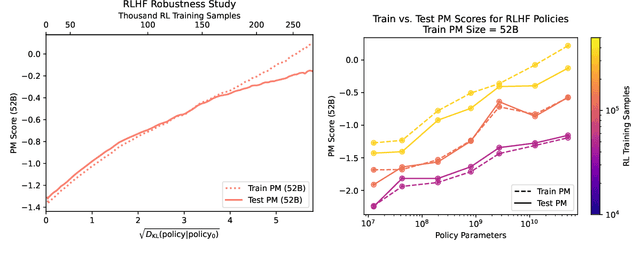
We apply preference modeling and reinforcement learning from human feedback (RLHF) to finetune language models to act as helpful and harmless assistants. We find this alignment training improves performance on almost all NLP evaluations, and is fully compatible with training for specialized skills such as python coding and summarization. We explore an iterated online mode of training, where preference models and RL policies are updated on a weekly cadence with fresh human feedback data, efficiently improving our datasets and models. Finally, we investigate the robustness of RLHF training, and identify a roughly linear relation between the RL reward and the square root of the KL divergence between the policy and its initialization. Alongside our main results, we perform peripheral analyses on calibration, competing objectives, and the use of OOD detection, compare our models with human writers, and provide samples from our models using prompts appearing in recent related work.
Adversarial vulnerability of powerful near out-of-distribution detection
Jan 18, 2022



There has been a significant progress in detecting out-of-distribution (OOD) inputs in neural networks recently, primarily due to the use of large models pretrained on large datasets, and an emerging use of multi-modality. We show a severe adversarial vulnerability of even the strongest current OOD detection techniques. With a small, targeted perturbation to the input pixels, we can change the image assignment from an in-distribution to an out-distribution, and vice versa, easily. In particular, we demonstrate severe adversarial vulnerability on the challenging near OOD CIFAR-100 vs CIFAR-10 task, as well as on the far OOD CIFAR-100 vs SVHN. We study the adversarial robustness of several post-processing techniques, including the simple baseline of Maximum of Softmax Probabilities (MSP), the Mahalanobis distance, and the newly proposed \textit{Relative} Mahalanobis distance. By comparing the loss of OOD detection performance at various perturbation strengths, we demonstrate the beneficial effect of using ensembles of OOD detectors, and the use of the \textit{Relative} Mahalanobis distance over other post-processing methods. In addition, we show that even strong zero-shot OOD detection using CLIP and multi-modality suffers from a severe lack of adversarial robustness as well. Our code is available at https://github.com/stanislavfort/adversaries_to_OOD_detection
How many degrees of freedom do we need to train deep networks: a loss landscape perspective
Jul 13, 2021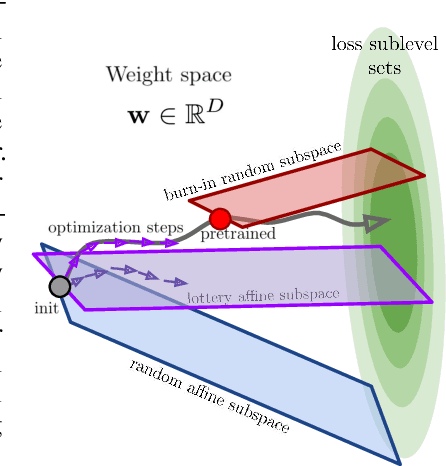
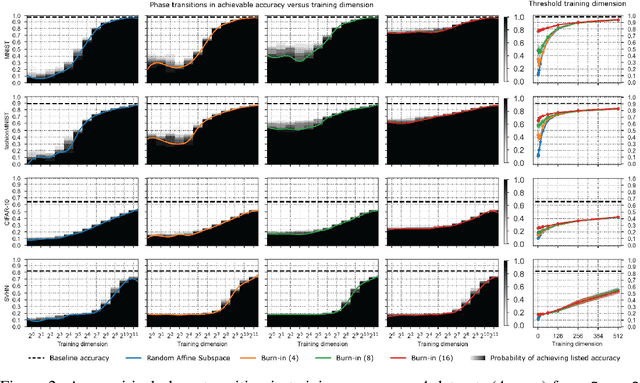
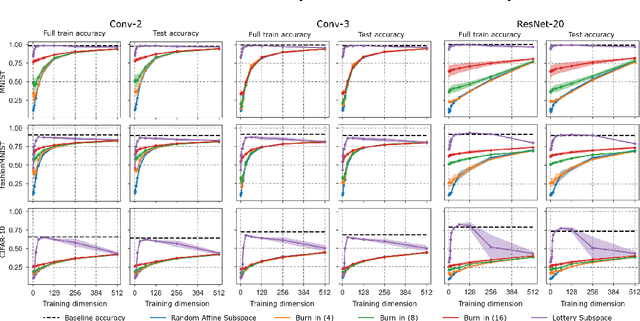
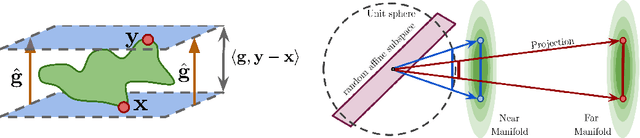
A variety of recent works, spanning pruning, lottery tickets, and training within random subspaces, have shown that deep neural networks can be trained using far fewer degrees of freedom than the total number of parameters. We explain this phenomenon by first examining the success probability of hitting a training loss sub-level set when training within a random subspace of a given training dimensionality. We find a sharp phase transition in the success probability from $0$ to $1$ as the training dimension surpasses a threshold. This threshold training dimension increases as the desired final loss decreases, but decreases as the initial loss decreases. We then theoretically explain the origin of this phase transition, and its dependence on initialization and final desired loss, in terms of precise properties of the high dimensional geometry of the loss landscape. In particular, we show via Gordon's escape theorem, that the training dimension plus the Gaussian width of the desired loss sub-level set, projected onto a unit sphere surrounding the initialization, must exceed the total number of parameters for the success probability to be large. In several architectures and datasets, we measure the threshold training dimension as a function of initialization and demonstrate that it is a small fraction of the total number of parameters, thereby implying, by our theory, that successful training with so few dimensions is possible precisely because the Gaussian width of low loss sub-level sets is very large. Moreover, this threshold training dimension provides a strong null model for assessing the efficacy of more sophisticated ways to reduce training degrees of freedom, including lottery tickets as well a more optimal method we introduce: lottery subspaces.
A Simple Fix to Mahalanobis Distance for Improving Near-OOD Detection
Jun 16, 2021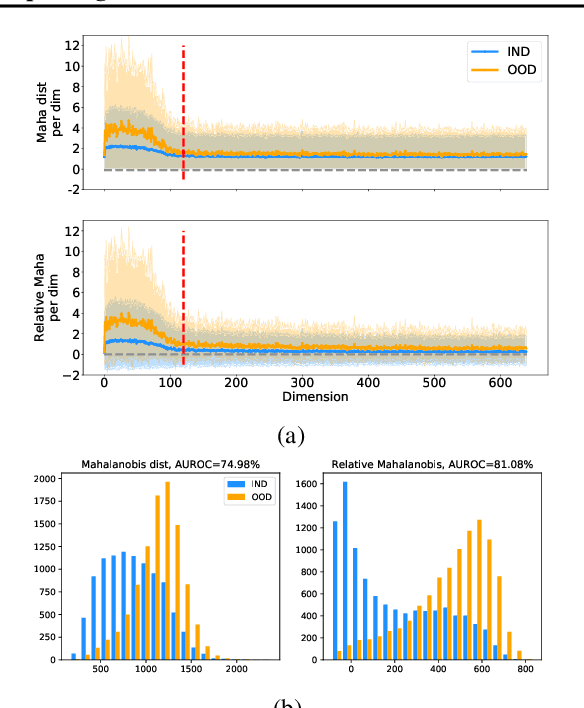
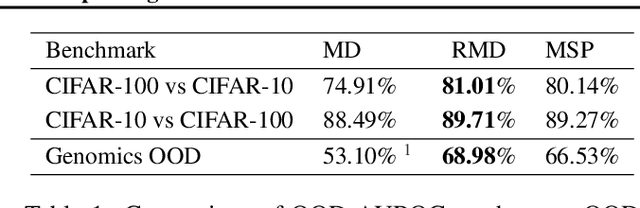
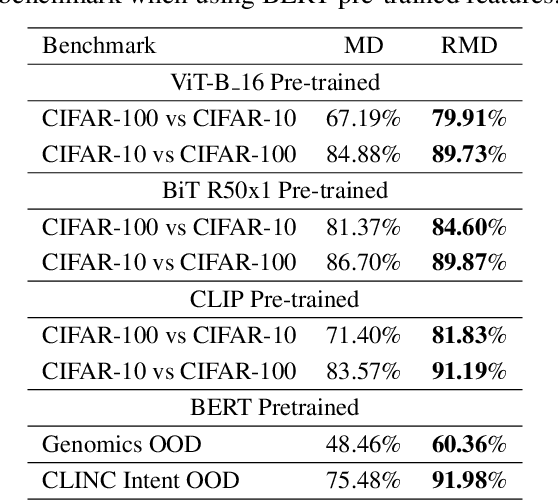
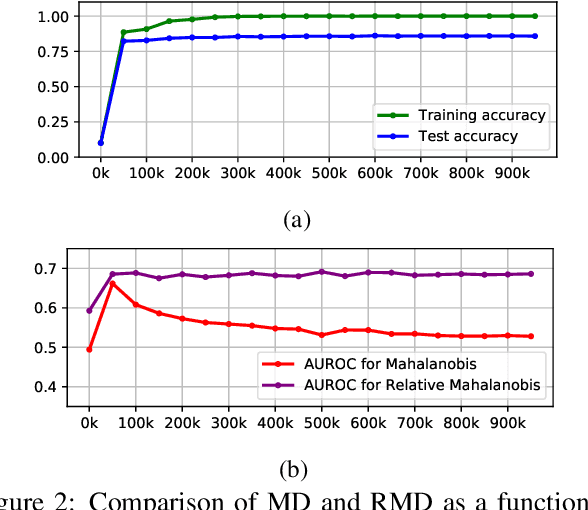
Mahalanobis distance (MD) is a simple and popular post-processing method for detecting out-of-distribution (OOD) inputs in neural networks. We analyze its failure modes for near-OOD detection and propose a simple fix called relative Mahalanobis distance (RMD) which improves performance and is more robust to hyperparameter choice. On a wide selection of challenging vision, language, and biology OOD benchmarks (CIFAR-100 vs CIFAR-10, CLINC OOD intent detection, Genomics OOD), we show that RMD meaningfully improves upon MD performance (by up to 15% AUROC on genomics OOD).
Exploring the Limits of Out-of-Distribution Detection
Jun 06, 2021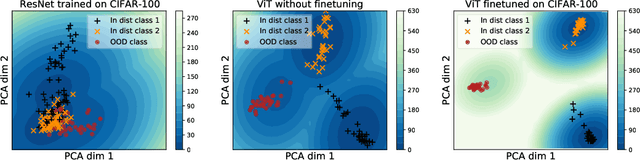
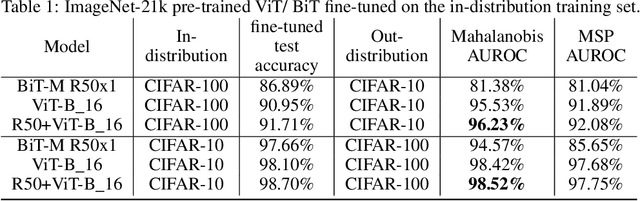
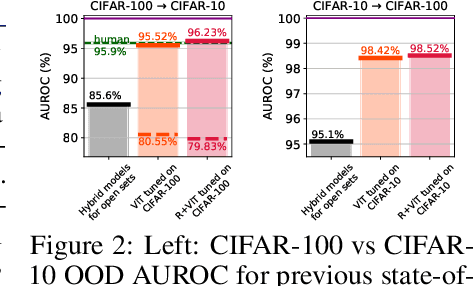

Near out-of-distribution detection (OOD) is a major challenge for deep neural networks. We demonstrate that large-scale pre-trained transformers can significantly improve the state-of-the-art (SOTA) on a range of near OOD tasks across different data modalities. For instance, on CIFAR-100 vs CIFAR-10 OOD detection, we improve the AUROC from 85% (current SOTA) to more than 96% using Vision Transformers pre-trained on ImageNet-21k. On a challenging genomics OOD detection benchmark, we improve the AUROC from 66% to 77% using transformers and unsupervised pre-training. To further improve performance, we explore the few-shot outlier exposure setting where a few examples from outlier classes may be available; we show that pre-trained transformers are particularly well-suited for outlier exposure, and that the AUROC of OOD detection on CIFAR-100 vs CIFAR-10 can be improved to 98.7% with just 1 image per OOD class, and 99.46% with 10 images per OOD class. For multi-modal image-text pre-trained transformers such as CLIP, we explore a new way of using just the names of outlier classes as a sole source of information without any accompanying images, and show that this outperforms previous SOTA on standard vision OOD benchmark tasks.
Drawing Multiple Augmentation Samples Per Image During Training Efficiently Decreases Test Error
May 27, 2021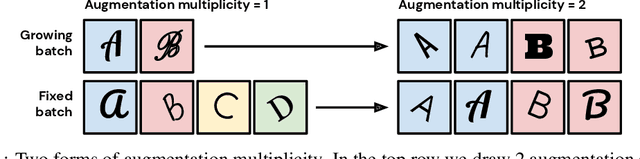

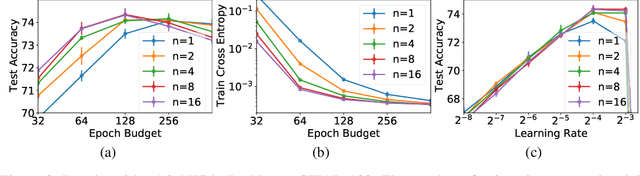

In computer vision, it is standard practice to draw a single sample from the data augmentation procedure for each unique image in the mini-batch, however it is not clear whether this choice is optimal for generalization. In this work, we provide a detailed empirical evaluation of how the number of augmentation samples per unique image influences performance on held out data. Remarkably, we find that drawing multiple samples per image consistently enhances the test accuracy achieved for both small and large batch training, despite reducing the number of unique training examples in each mini-batch. This benefit arises even when different augmentation multiplicities perform the same number of parameter updates and gradient evaluations. Our results suggest that, although the variance in the gradient estimate arising from subsampling the dataset has an implicit regularization benefit, the variance which arises from the data augmentation process harms test accuracy. By applying augmentation multiplicity to the recently proposed NFNet model family, we achieve a new ImageNet state of the art of 86.8$\%$ top-1 w/o extra data.
Analyzing Monotonic Linear Interpolation in Neural Network Loss Landscapes
Apr 23, 2021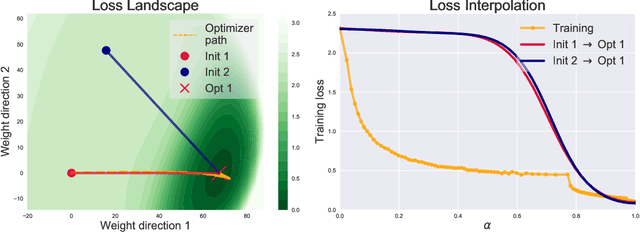


Linear interpolation between initial neural network parameters and converged parameters after training with stochastic gradient descent (SGD) typically leads to a monotonic decrease in the training objective. This Monotonic Linear Interpolation (MLI) property, first observed by Goodfellow et al. (2014) persists in spite of the non-convex objectives and highly non-linear training dynamics of neural networks. Extending this work, we evaluate several hypotheses for this property that, to our knowledge, have not yet been explored. Using tools from differential geometry, we draw connections between the interpolated paths in function space and the monotonicity of the network - providing sufficient conditions for the MLI property under mean squared error. While the MLI property holds under various settings (e.g. network architectures and learning problems), we show in practice that networks violating the MLI property can be produced systematically, by encouraging the weights to move far from initialization. The MLI property raises important questions about the loss landscape geometry of neural networks and highlights the need to further study their global properties.
Deep learning versus kernel learning: an empirical study of loss landscape geometry and the time evolution of the Neural Tangent Kernel
Oct 28, 2020
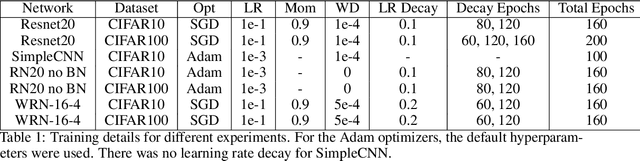
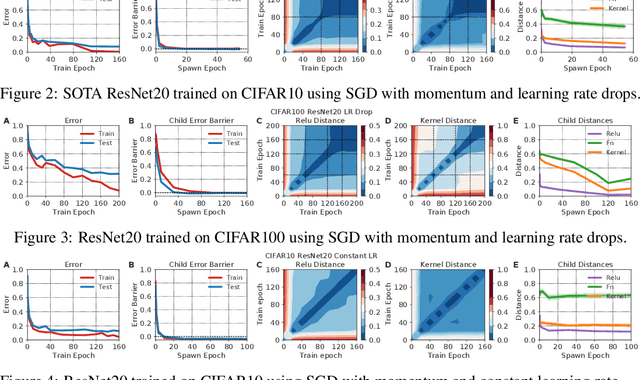
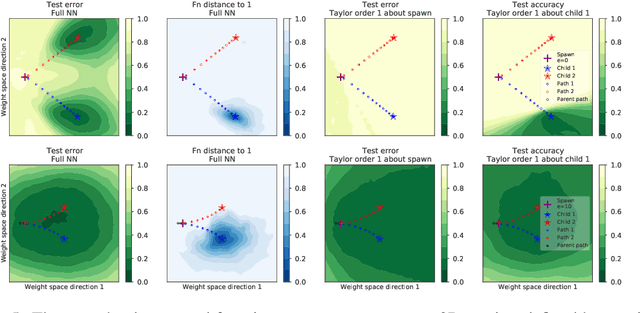
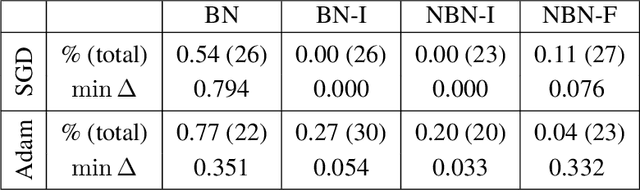
In suitably initialized wide networks, small learning rates transform deep neural networks (DNNs) into neural tangent kernel (NTK) machines, whose training dynamics is well-approximated by a linear weight expansion of the network at initialization. Standard training, however, diverges from its linearization in ways that are poorly understood. We study the relationship between the training dynamics of nonlinear deep networks, the geometry of the loss landscape, and the time evolution of a data-dependent NTK. We do so through a large-scale phenomenological analysis of training, synthesizing diverse measures characterizing loss landscape geometry and NTK dynamics. In multiple neural architectures and datasets, we find these diverse measures evolve in a highly correlated manner, revealing a universal picture of the deep learning process. In this picture, deep network training exhibits a highly chaotic rapid initial transient that within 2 to 3 epochs determines the final linearly connected basin of low loss containing the end point of training. During this chaotic transient, the NTK changes rapidly, learning useful features from the training data that enables it to outperform the standard initial NTK by a factor of 3 in less than 3 to 4 epochs. After this rapid chaotic transient, the NTK changes at constant velocity, and its performance matches that of full network training in 15% to 45% of training time. Overall, our analysis reveals a striking correlation between a diverse set of metrics over training time, governed by a rapid chaotic to stable transition in the first few epochs, that together poses challenges and opportunities for the development of more accurate theories of deep learning.
Training independent subnetworks for robust prediction
Oct 13, 2020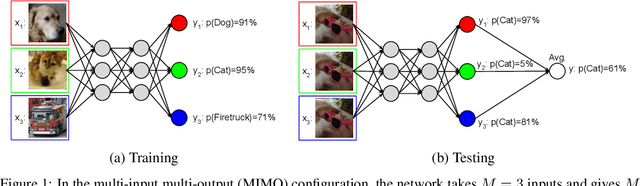
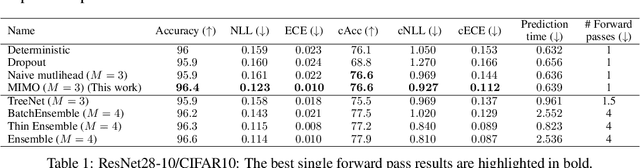

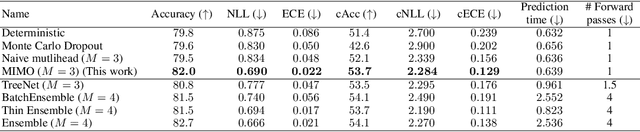
Recent approaches to efficiently ensemble neural networks have shown that strong robustness and uncertainty performance can be achieved with a negligible gain in parameters over the original network. However, these methods still require multiple forward passes for prediction, leading to a significant computational cost. In this work, we show a surprising result: the benefits of using multiple predictions can be achieved `for free' under a single model's forward pass. In particular, we show that, using a multi-input multi-output (MIMO) configuration, one can utilize a single model's capacity to train multiple subnetworks that independently learn the task at hand. By ensembling the predictions made by the subnetworks, we improve model robustness without increasing compute. We observe a significant improvement in negative log-likelihood, accuracy, and calibration error on CIFAR10, CIFAR100, ImageNet, and their out-of-distribution variants compared to previous methods.
The Break-Even Point on Optimization Trajectories of Deep Neural Networks
Feb 21, 2020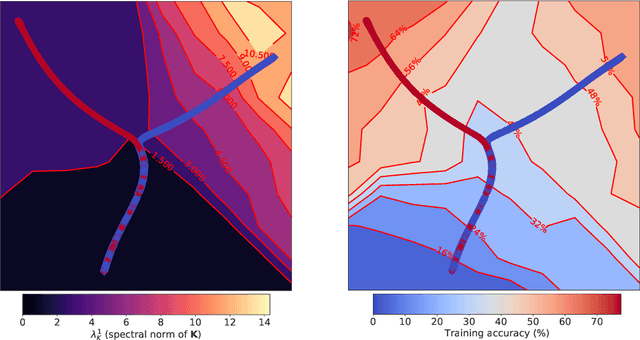
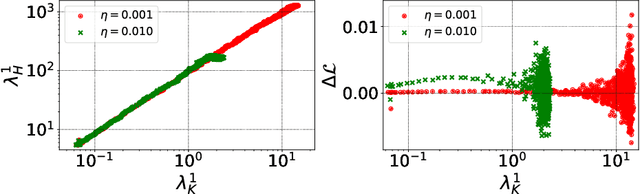

The early phase of training of deep neural networks is critical for their final performance. In this work, we study how the hyperparameters of stochastic gradient descent (SGD) used in the early phase of training affect the rest of the optimization trajectory. We argue for the existence of the "break-even" point on this trajectory, beyond which the curvature of the loss surface and noise in the gradient are implicitly regularized by SGD. In particular, we demonstrate on multiple classification tasks that using a large learning rate in the initial phase of training reduces the variance of the gradient, and improves the conditioning of the covariance of gradients. These effects are beneficial from the optimization perspective and become visible after the break-even point. Complementing prior work, we also show that using a low learning rate results in bad conditioning of the loss surface even for a neural network with batch normalization layers. In short, our work shows that key properties of the loss surface are strongly influenced by SGD in the early phase of training. We argue that studying the impact of the identified effects on generalization is a promising future direction.