 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Monotonic Linear Interpolation in Neural Network Loss Landscapes
Paper and Code
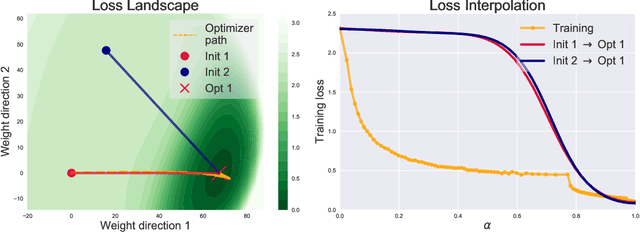


Linear interpolation between initial neural network parameters and converged parameters after training with stochastic gradient descent (SGD) typically leads to a monotonic decrease in the training objective. This Monotonic Linear Interpolation (MLI) property, first observed by Goodfellow et al. (2014) persists in spite of the non-convex objectives and highly non-linear training dynamics of neural networks. Extending this work, we evaluate several hypotheses for this property that, to our knowledge, have not yet been explored. Using tools from differential geometry, we draw connections between the interpolated paths in function space and the monotonicity of the network - providing sufficient conditions for the MLI property under mean squared error. While the MLI property holds under various settings (e.g. network architectures and learning problems), we show in practice that networks violating the MLI property can be produced systematically, by encouraging the weights to move far from initialization. The MLI property raises important questions about the loss landscape geometry of neural networks and highlights the need to further study their global properties.