 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVA-Bench: Atomic Visual Ability Benchmark for Vision Foundation Models
Paper and Code
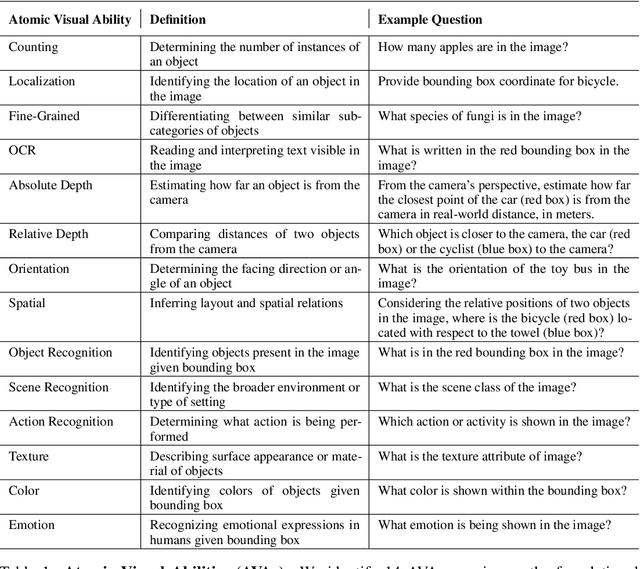
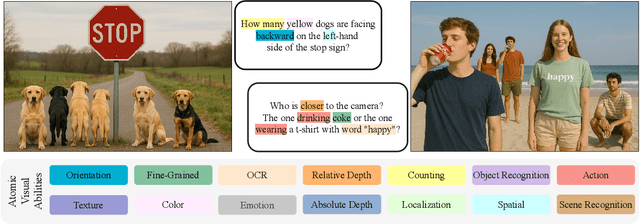
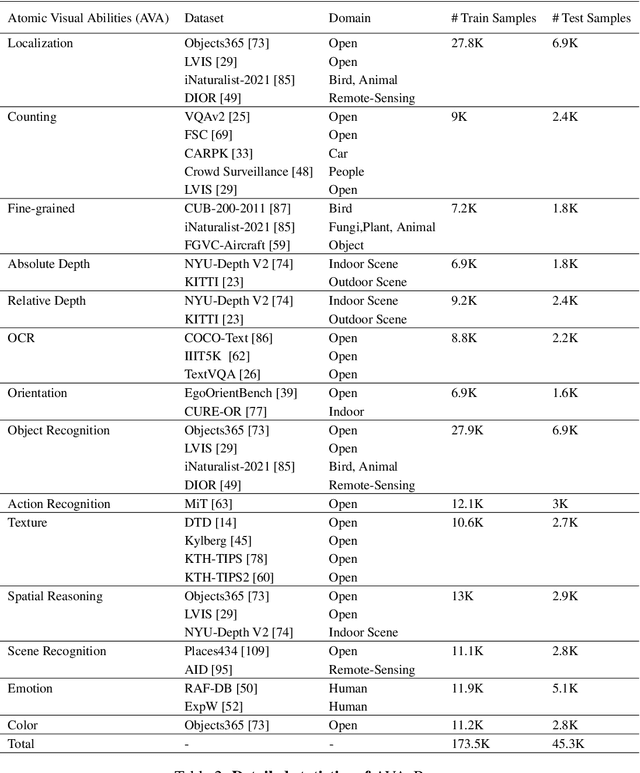

The rise of vision foundation models (VFMs) calls for systematic evaluation. A common approach pairs VFMs with large language models (LLMs) as general-purpose heads, followed by evaluation on broad Visual Question Answering (VQA) benchmarks. However, this protocol has two key blind spots: (i) the instruction tuning data may not align with VQA test distributions, meaning a wrong prediction can stem from such data mismatch rather than a VFM' visual shortcomings; (ii) VQA benchmarks often require multiple visual abilities, making it hard to tell whether errors stem from lacking all required abilities or just a single critical one. To address these gaps, we introduce AVA-Bench, the first benchmark that explicitly disentangles 14 Atomic Visual Abilities (AVAs) -- foundational skills like localization, depth estimation, and spatial understanding that collectively support complex visual reasoning tasks. By decoupling AVAs and matching training and test distributions within each, AVA-Bench pinpoints exactly where a VFM excels or falters. Applying AVA-Bench to leading VFMs thus reveals distinctive "ability fingerprints," turning VFM selection from educated guesswork into principled engineering. Notably, we find that a 0.5B LLM yields similar VFM rankings as a 7B LLM while cutting GPU hours by 8x, enabling more efficient evaluation. By offering a comprehensive and transparent benchmark, we hope AVA-Bench lays the foundation for the next generation of VFMs.