 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrice of Fairness in Short-Term and Long-Term Algorithmic Selections
May 07, 2026Algorithmic decision-making in high-stakes settings can have profound impacts on individuals and populations. While much prior work studies fairness in static settings, recent results show that enforcing static fairness constraints may exacerbate long-run disparities. Motivated by this tension, we study a stylized sequential selection problem in which a decision-maker repeatedly selects individuals, affecting both immediate utility and the population distribution over time. We introduce notions of group fairness for both the short and long term and theoretically analyze the trade-off between fairness and utility via the Price of Fairness (PoF). We characterize optimal and fair policies in the short term and show that the PoF can be large even when group distributions are nearly identical. In contrast, we show that long-term disparities can vanish under simple investment policies that achieve a low PoF. We also empirically validate these theoretical observations using both synthetic and real datasets.
Learning-Augmented Robust Algorithmic Recourse
Oct 02, 2024



The widespread use of machine learning models in high-stakes domains can have a major negative impact, especially on individuals who receive undesirable outcomes. Algorithmic recourse provides such individuals with suggestions of minimum-cost improvements they can make to achieve a desirable outcome in the future. However, machine learning models often get updated over time and this can cause a recourse to become invalid (i.e., not lead to the desirable outcome). The robust recourse literature aims to choose recourses that are less sensitive, even against adversarial model changes, but this comes at a higher cost. To overcome this obstacle, we initiate the study of algorithmic recourse through the learning-augmented framework and evaluate the extent to which a designer equipped with a prediction regarding future model changes can reduce the cost of recourse when the prediction is accurate (consistency) while also limiting the cost even when the prediction is inaccurate (robustness). We propose a novel algorithm for this problem, study the robustness-consistency trade-off, and analyze how prediction accuracy affects performance.
Improving Fairness in Adaptive Social Exergames via Shapley Bandits
Feb 21, 2023Algorithmic fairness is an essential requirement as AI becomes integrated in society. In the case of social applications where AI distributes resources, algorithms often must make decisions that will benefit a subset of users, sometimes repeatedly or exclusively, while attempting to maximize specific outcomes. How should we design such systems to serve users more fairly? This paper explores this question in the case where a group of users works toward a shared goal in a social exergame called Step Heroes. We identify adverse outcomes in traditional multi-armed bandits (MABs) and formalize the Greedy Bandit Problem. We then propose a solution based on a new type of fairness-aware multi-armed bandit, Shapley Bandits. It uses the Shapley Value for increasing overall player participation and intervention adherence rather than the maximization of total group output, which is traditionally achieved by favoring only high-performing participants. We evaluate our approach via a user study (n=46). Our results indicate that our Shapley Bandits effectively mediates the Greedy Bandit Problem and achieves better user retention and motivation across the participants.
TorchFL: A Performant Library for Bootstrapping Federated Learning Experiments
Nov 01, 2022With the increased legislation around data privacy, federated learning (FL) has emerged as a promising technique that allows the clients (end-user) to collaboratively train deep learning (DL) models without transferring and storing the data in a centralized, third-party server. Despite the theoretical success, FL is yet to be adopted in real-world systems due to the hardware, computing, and various infrastructure constraints presented by the edge and mobile devices of the clients. As a result, simulated datasets, models, and experiments are heavily used by the FL research community to validate their theories and findings. We introduce TorchFL, a performant library for (i) bootstrapping the FL experiments, (ii) executing them using various hardware accelerators, (iii) profiling the performance, and (iv) logging the overall and agent-specific results on the go. Being built on a bottom-up design using PyTorch and Lightning, TorchFL provides ready-to-use abstractions for models, datasets, and FL algorithms, while allowing the developers to customize them as and when required.
The Disagreement Problem in Explainable Machine Learning: A Practitioner's Perspective
Feb 08, 2022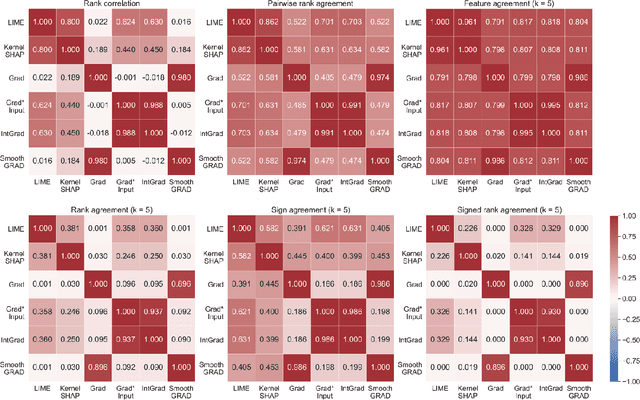

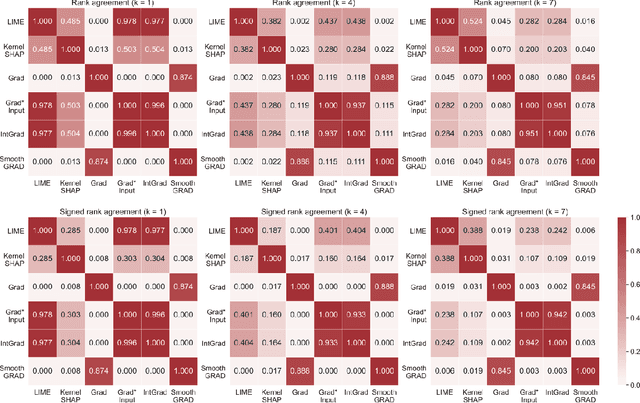
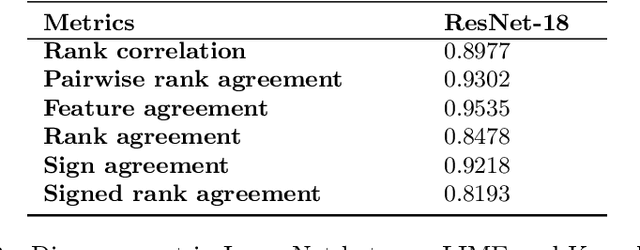
As various post hoc explanation methods are increasingly being leveraged to explain complex models in high-stakes settings, it becomes critical to develop a deeper understanding of if and when the explanations output by these methods disagree with each other, and how such disagreements are resolved in practice. However, there is little to no research that provides answers to these critical questions. In this work, we introduce and study the disagreement problem in explainable machine learning. More specifically, we formalize the notion of disagreement between explanations, analyze how often such disagreements occur in practice, and how do practitioners resolve these disagreements. To this end, we first conduct interviews with data scientists to understand what constitutes disagreement between explanations generated by different methods for the same model prediction, and introduce a novel quantitative framework to formalize this understanding. We then leverage this framework to carry out a rigorous empirical analysis with four real-world datasets, six state-of-the-art post hoc explanation methods, and eight different predictive models, to measure the extent of disagreement between the explanations generated by various popular explanation methods. In addition, we carry out an online user study with data scientists to understand how they resolve the aforementioned disagreements. Our results indicate that state-of-the-art explanation methods often disagree in terms of the explanations they output. Our findings also underscore the importance of developing principled evaluation metrics that enable practitioners to effectively compare explanations.
Towards the Unification and Robustness of Perturbation and Gradient Based Explanations
Feb 21, 2021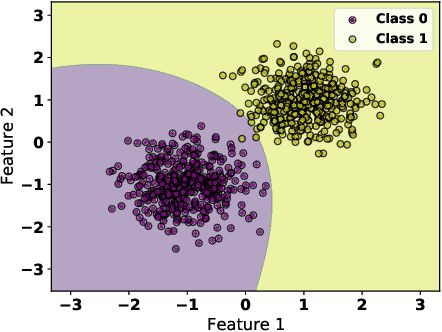
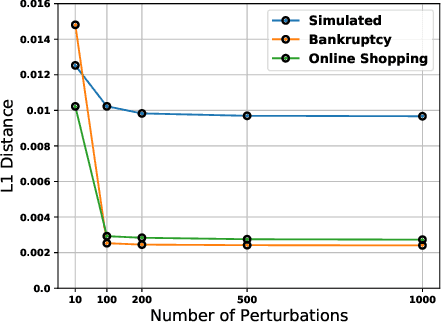
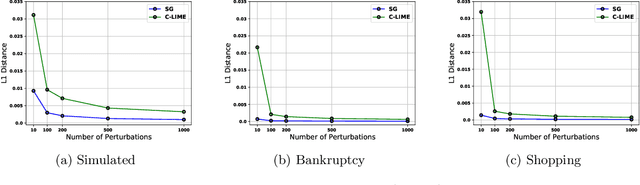
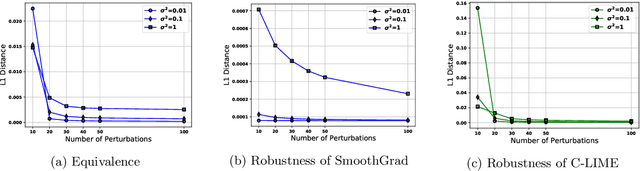
As machine learning black boxes are increasingly being deployed in critical domains such as healthcare and criminal justice, there has been a growing emphasis on developing techniques for explaining these black boxes in a post hoc manner. In this work, we analyze two popular post hoc interpretation techniques: SmoothGrad which is a gradient based method, and a variant of LIME which is a perturbation based method. More specifically, we derive explicit closed form expressions for the explanations output by these two methods and show that they both converge to the same explanation in expectation, i.e., when the number of perturbed samples used by these methods is large. We then leverage this connection to establish other desirable properties, such as robustness, for these techniques. We also derive finite sample complexity bounds for the number of perturbations required for these methods to converge to their expected explanation. Finally, we empirically validate our theory using extensive experimentation on both synthetic and real world datasets.
Active Screening for Recurrent Diseases: A Reinforcement Learning Approach
Jan 27, 2021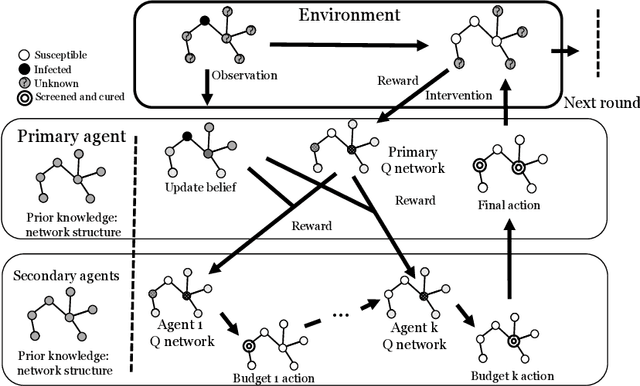
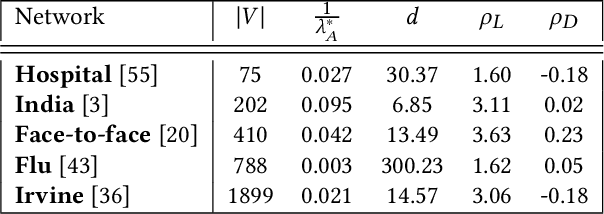
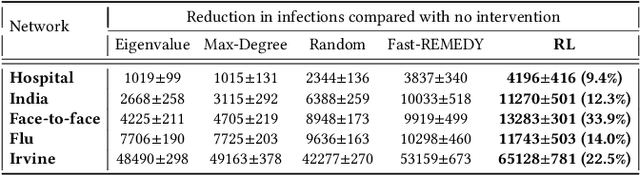
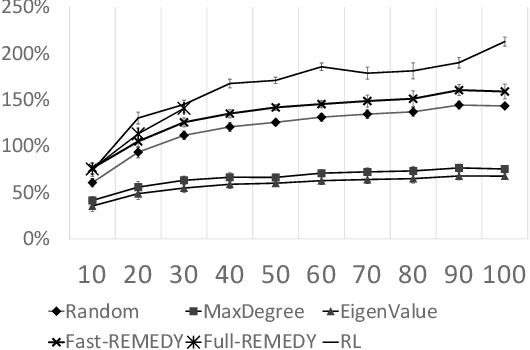
Active screening is a common approach in controlling the spread of recurring infectious diseases such as tuberculosis and influenza. In this approach, health workers periodically select a subset of population for screening. However, given the limited number of health workers, only a small subset of the population can be visited in any given time period. Given the recurrent nature of the disease and rapid spreading, the goal is to minimize the number of infections over a long time horizon. Active screening can be formalized as a sequential combinatorial optimization over the network of people and their connections. The main computational challenges in this formalization arise from i) the combinatorial nature of the problem, ii) the need of sequential planning and iii) the uncertainties in the infectiousness states of the population. Previous works on active screening fail to scale to large time horizon while fully considering the future effect of current interventions. In this paper, we propose a novel reinforcement learning (RL) approach based on Deep Q-Networks (DQN), with several innovative adaptations that are designed to address the above challenges. First, we use graph convolutional networks (GCNs) to represent the Q-function that exploit the node correlations of the underlying contact network. Second, to avoid solving a combinatorial optimization problem in each time period, we decompose the node set selection as a sub-sequence of decisions, and further design a two-level RL framework that solves the problem in a hierarchical way. Finally, to speed-up the slow convergence of RL which arises from reward sparseness, we incorporate ideas from curriculum learning into our hierarchical RL approach. We evaluate our RL algorithm on several real-world networks.
Fair Influence Maximization: A Welfare Optimization Approach
Jun 14, 2020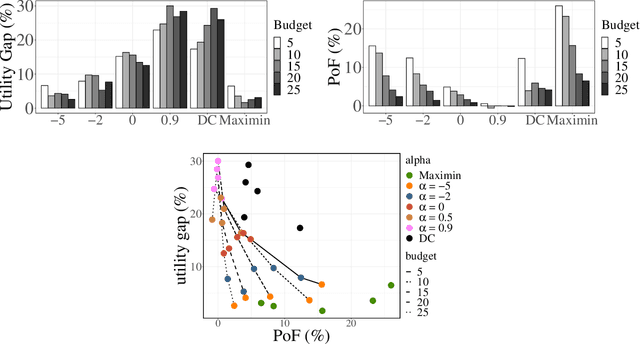
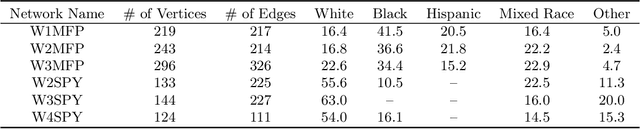

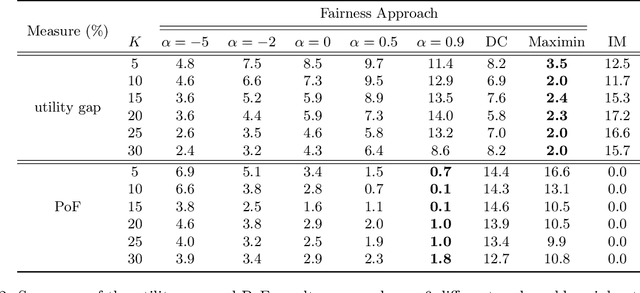
Several social interventions (e.g., suicide and HIV prevention) leverage social network information to maximize outreach. Algorithmic influence maximization techniques have been proposed to aid with the choice of influencers (or peer leaders) in such interventions. Traditional algorithms for influence maximization have not been designed with social interventions in mind. As a result, they may disproportionately exclude minority communities from the benefits of the intervention. This has motivated research on fair influence maximization. Existing techniques require committing to a single domain-specific fairness measure. This makes it hard for a decision maker to meaningfully compare these notions and their resulting trade-offs across different applications. We address these shortcomings by extending the principles of cardinal welfare to the influence maximization setting, which is underlain by complex connections between members of different communities. We generalize the theory regarding these principles and show under what circumstances these principles can be satisfied by a welfare function. We then propose a family of welfare functions that are governed by a single inequity aversion parameter which allows a decision maker to study task-dependent trade-offs between fairness and total influence and effectively trade off quantities like influence gap by varying this parameter. We use these welfare functions as a fairness notion to rule out undesirable allocations. We show that the resulting optimization problem is monotone and submodular and can be solved with optimality guarantees. Finally, we carry out a detailed experimental analysis on synthetic and real social networks and should that high welfare can be achieved without sacrificing the total influence significantly. Interestingly we can show there exists welfare functions that empirically satisfy all of the principles.
Equilibrium Characterization for Data Acquisition Games
May 23, 2019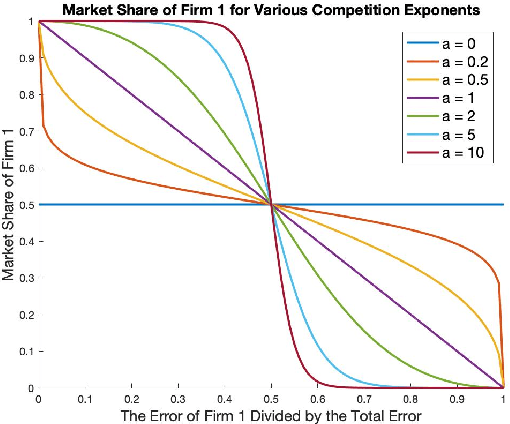
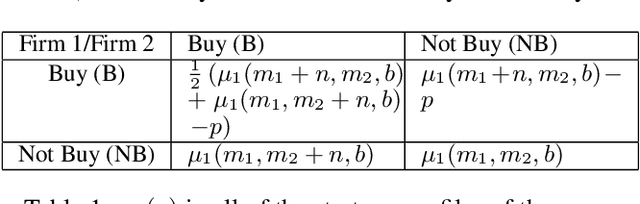
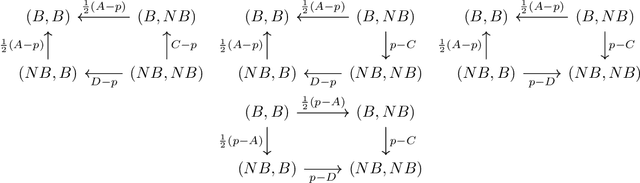
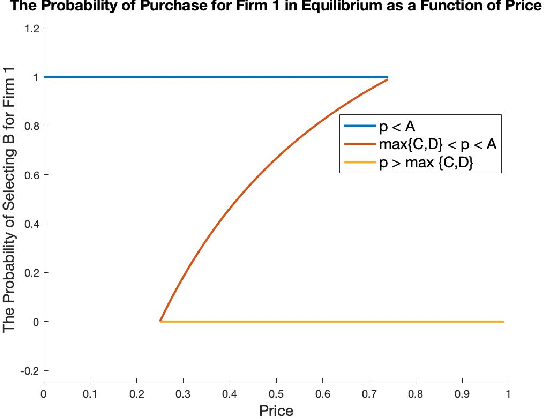
We study a game between two firms in which each provide a service based on machine learning. The firms are presented with the opportunity to purchase a new corpus of data, which will allow them to potentially improve the quality of their products. The firms can decide whether or not they want to buy the data, as well as which learning model to build with that data. We demonstrate a reduction from this potentially complicated action space to a one-shot, two-action game in which each firm only decides whether or not to buy the data. The game admits several regimes which depend on the relative strength of the two firms at the outset and the price at which the data is being offered. We analyze the game's Nash equilibria in all parameter regimes and demonstrate that, in expectation, the outcome of the game is that the initially stronger firm's market position weakens whereas the initially weaker firm's market position becomes stronger. Finally, we consider the perspective of the users of the service and demonstrate that the expected outcome at equilibrium is not the one which maximizes the welfare of the consumers.
Fair Algorithms for Learning in Allocation Problems
Aug 30, 2018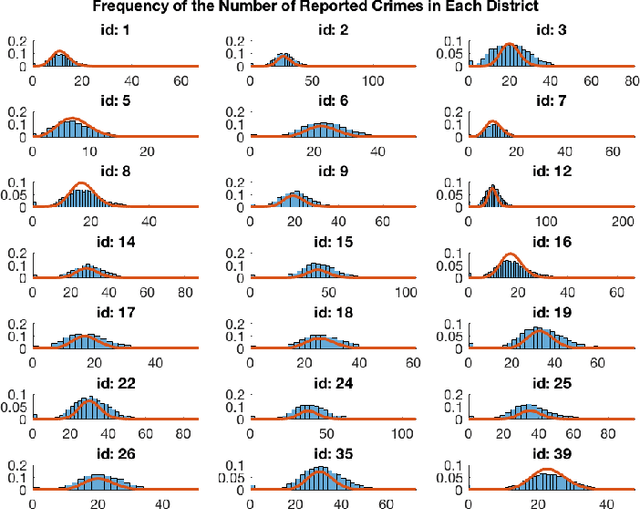
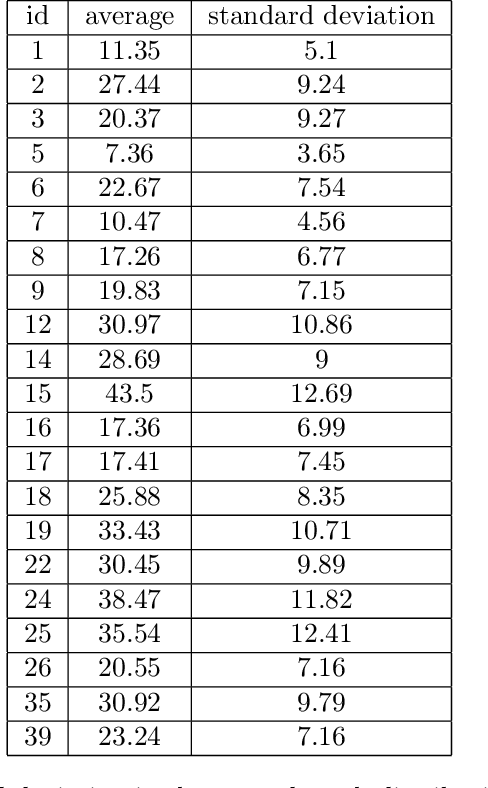
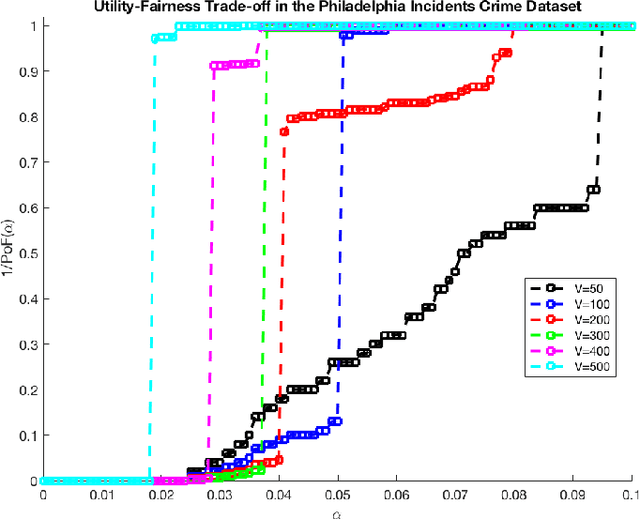
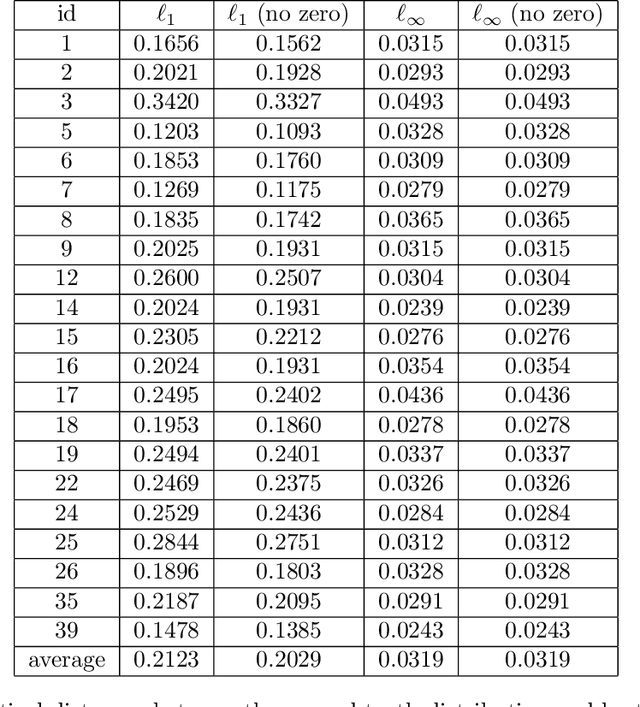
Settings such as lending and policing can be modeled by a centralized agent allocating a resource (loans or police officers) amongst several groups, in order to maximize some objective (loans given that are repaid or criminals that are apprehended). Often in such problems fairness is also a concern. A natural notion of fairness, based on general principles of equality of opportunity, asks that conditional on an individual being a candidate for the resource, the probability of actually receiving it is approximately independent of the individual's group. In lending this means that equally creditworthy individuals in different racial groups have roughly equal chances of receiving a loan. In policing it means that two individuals committing the same crime in different districts would have roughly equal chances of being arrested. We formalize this fairness notion for allocation problems and investigate its algorithmic consequences. Our main technical results include an efficient learning algorithm that converges to an optimal fair allocation even when the frequency of candidates (creditworthy individuals or criminals) in each group is unknown. The algorithm operates in a censored feedback model in which only the number of candidates who received the resource in a given allocation can be observed, rather than the true number of candidates. This models the fact that we do not learn the creditworthiness of individuals we do not give loans to nor learn about crimes committed if the police presence in a district is low. As an application of our framework, we consider the predictive policing problem. The learning algorithm is trained on arrest data gathered from its own deployments on previous days, resulting in a potential feedback loop that our algorithm provably overcomes. We empirically investigate the performance of our algorithm on the Philadelphia Crime Incidents dataset.