 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-Fact: Fact Extraction and Verification of Real-World Claims on COVID-19 Pandemic
Jun 07, 2021

We introduce a FEVER-like dataset COVID-Fact of $4,086$ claims concerning the COVID-19 pandemic. The dataset contains claims, evidence for the claims, and contradictory claims refuted by the evidence. Unlike previous approaches, we automatically detect true claims and their source articles and then generate counter-claims using automatic methods rather than employing human annotators. Along with our constructed resource, we formally present the task of identifying relevant evidence for the claims and verifying whether the evidence refutes or supports a given claim. In addition to scientific claims, our data contains simplified general claims from media sources, making it better suited for detecting general misinformation regarding COVID-19. Our experiments indicate that COVID-Fact will provide a challenging testbed for the development of new systems and our approach will reduce the costs of building domain-specific datasets for detecting misinformation.
Figurative Language in Recognizing Textual Entailment
Jun 03, 2021


We introduce a collection of recognizing textual entailment (RTE) datasets focused on figurative language. We leverage five existing datasets annotated for a variety of figurative language -- simile, metaphor, and irony -- and frame them into over 12,500 RTE examples.We evaluate how well state-of-the-art models trained on popular RTE datasets capture different aspects of figurative language. Our results and analyses indicate that these models might not sufficiently capture figurative language, struggling to perform pragmatic inference and reasoning about world knowledge. Ultimately, our datasets provide a challenging testbed for evaluating RTE models.
Metaphor Generation with Conceptual Mappings
Jun 02, 2021

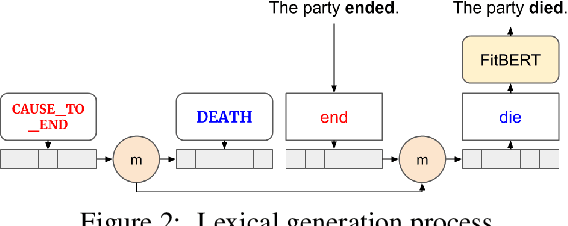
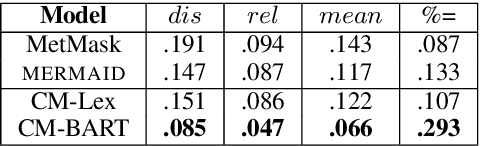
Generating metaphors is a difficult task as it requires understanding nuanced relationships between abstract concepts. In this paper, we aim to generate a metaphoric sentence given a literal expression by replacing relevant verbs. Guided by conceptual metaphor theory, we propose to control the generation process by encoding conceptual mappings between cognitive domains to generate meaningful metaphoric expressions. To achieve this, we develop two methods: 1) using FrameNet-based embeddings to learn mappings between domains and applying them at the lexical level (CM-Lex), and 2) deriving source/target pairs to train a controlled seq-to-seq generation model (CM-BART). We assess our methods through automatic and human evaluation for basic metaphoricity and conceptual metaphor presence. We show that the unsupervised CM-Lex model is competitive with recent deep learning metaphor generation systems, and CM-BART outperforms all other models both in automatic and human evaluations.
ENTRUST: Argument Reframing with Language Models and Entailment
Apr 11, 2021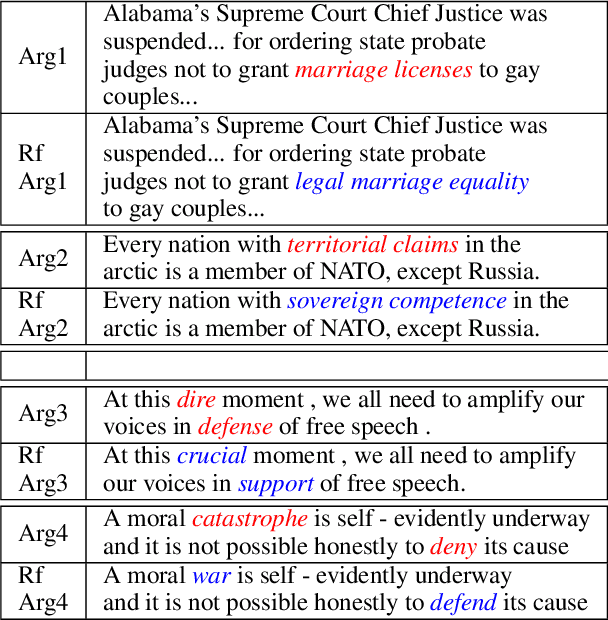
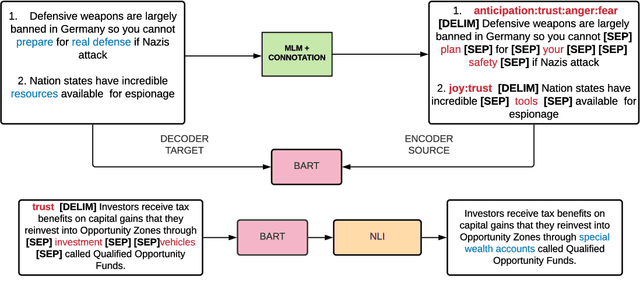


Framing involves the positive or negative presentation of an argument or issue depending on the audience and goal of the speaker (Entman 1983). Differences in lexical framing, the focus of our work, can have large effects on peoples' opinions and beliefs. To make progress towards reframing arguments for positive effects, we create a dataset and method for this task. We use a lexical resource for "connotations" to create a parallel corpus and propose a method for argument reframing that combines controllable text generation (positive connotation) with a post-decoding entailment component (same denotation). Our results show that our method is effective compared to strong baselines along the dimensions of fluency, meaning, and trustworthiness/reduction of fear.
MERMAID: Metaphor Generation with Symbolism and Discriminative Decoding
Apr 11, 2021
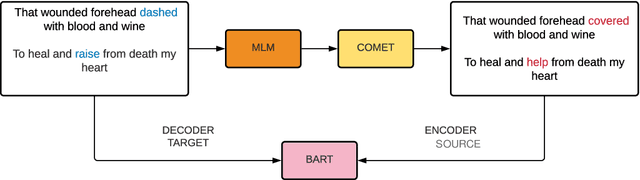
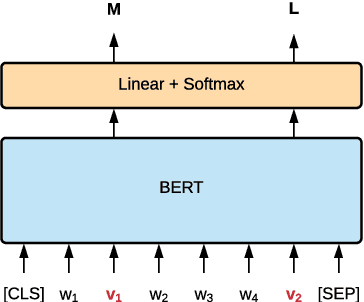

Generating metaphors is a challenging task as it requires a proper understanding of abstract concepts, making connections between unrelated concepts, and deviating from the literal meaning. In this paper, we aim to generate a metaphoric sentence given a literal expression by replacing relevant verbs. Based on a theoretically-grounded connection between metaphors and symbols, we propose a method to automatically construct a parallel corpus by transforming a large number of metaphorical sentences from the Gutenberg Poetry corpus (Jacobs, 2018) to their literal counterpart using recent advances in masked language modeling coupled with commonsense inference. For the generation task, we incorporate a metaphor discriminator to guide the decoding of a sequence to sequence model fine-tuned on our parallel data to generate high-quality metaphors. Human evaluation on an independent test set of literal statements shows that our best model generates metaphors better than three well-crafted baselines 66% of the time on average. A task-based evaluation shows that human-written poems enhanced with metaphors proposed by our model are preferred 68% of the time compared to poems without metaphors.
"Laughing at you or with you": The Role of Sarcasm in Shaping the Disagreement Space
Jan 26, 2021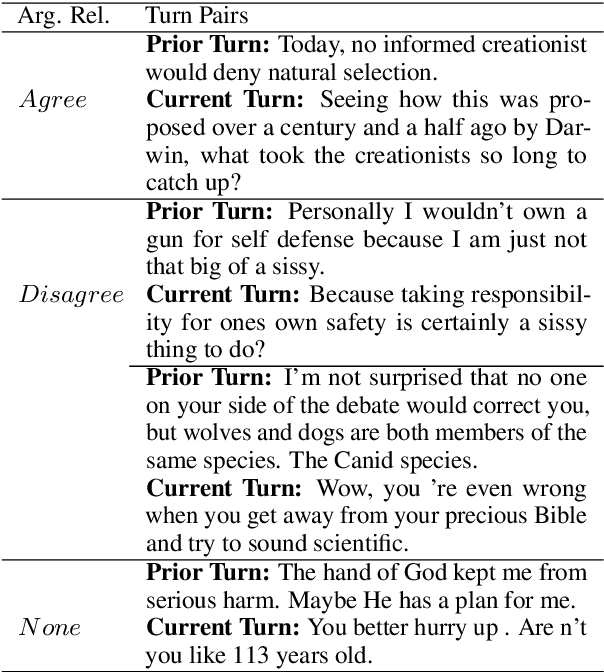
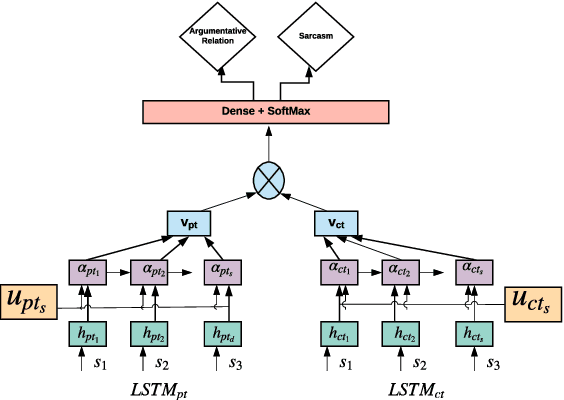
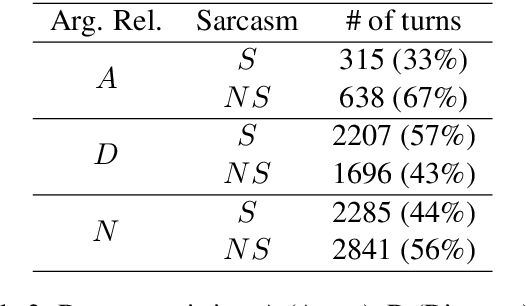
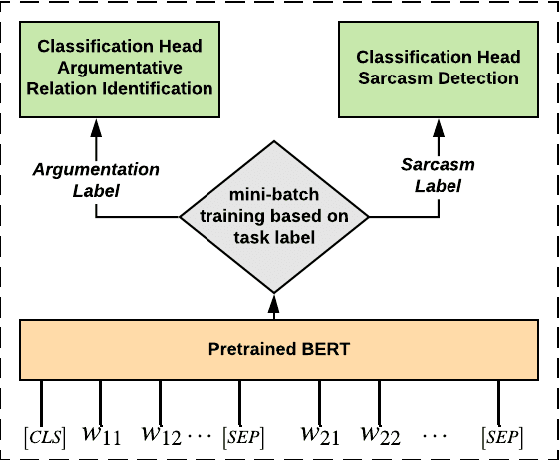
Detecting arguments in online interactions is useful to understand how conflicts arise and get resolved. Users often use figurative language, such as sarcasm, either as persuasive devices or to attack the opponent by an ad hominem argument. To further our understanding of the role of sarcasm in shaping the disagreement space, we present a thorough experimental setup using a corpus annotated with both argumentative moves (agree/disagree) and sarcasm. We exploit joint modeling in terms of (a) applying discrete features that are useful in detecting sarcasm to the task of argumentative relation classification (agree/disagree/none), and (b) multitask learning for argumentative relation classification and sarcasm detection using deep learning architectures (e.g., dual Long Short-Term Memory (LSTM) with hierarchical attention and Transformer-based architectures). We demonstrate that modeling sarcasm improves the argumentative relation classification task (agree/disagree/none) in all setups.
White Paper: Challenges and Considerations for the Creation of a Large Labelled Repository of Online Videos with Questionable Content
Jan 25, 2021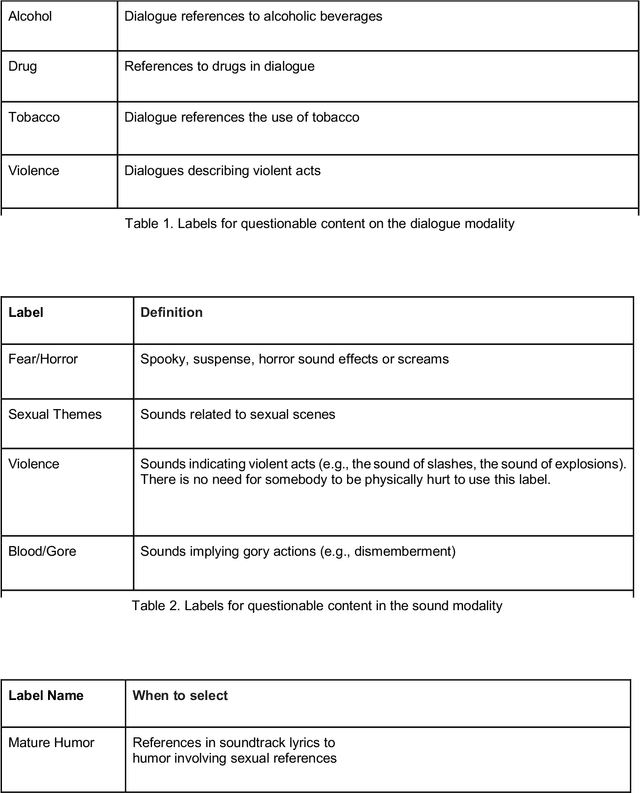
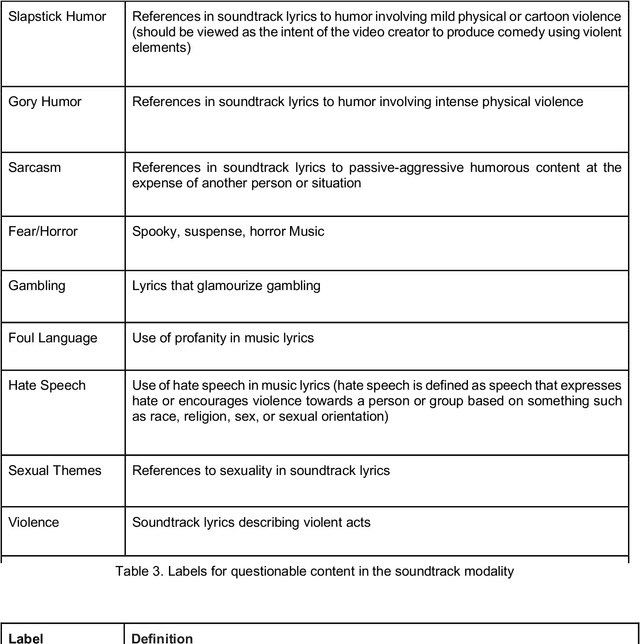

This white paper presents a summary of the discussions regarding critical considerations to develop an extensive repository of online videos annotated with labels indicating questionable content. The main discussion points include: 1) the type of appropriate labels that will result in a valuable repository for the larger AI community; 2) how to design the collection and annotation process, as well as the distribution of the corpus to maximize its potential impact; and, 3) what actions we can take to reduce risk of trauma to annotators.
To BERT or Not to BERT: Comparing Task-specific and Task-agnostic Semi-Supervised Approaches for Sequence Tagging
Oct 27, 2020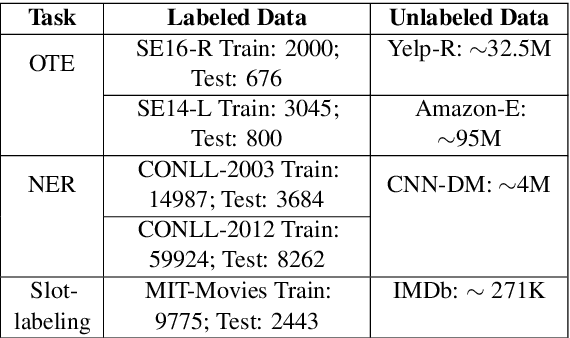
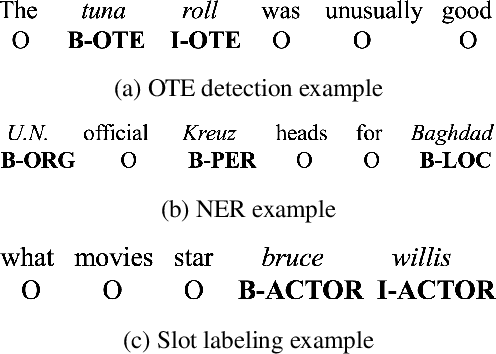
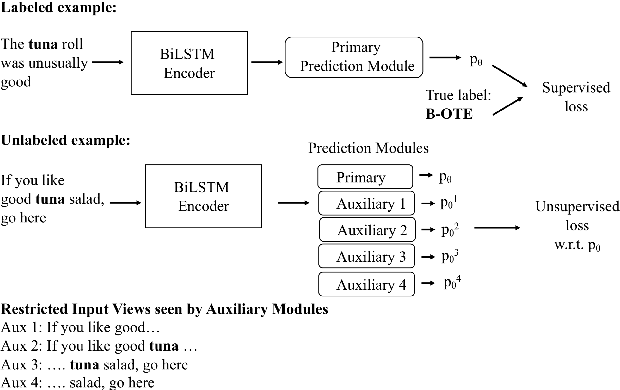
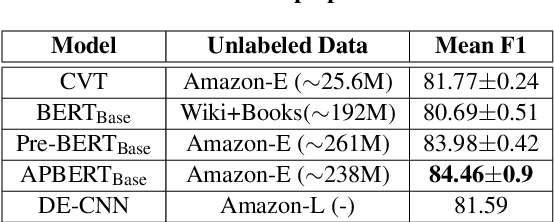
Leveraging large amounts of unlabeled data using Transformer-like architectures, like BERT, has gained popularity in recent times owing to their effectiveness in learning general representations that can then be further fine-tuned for downstream tasks to much success. However, training these models can be costly both from an economic and environmental standpoint. In this work, we investigate how to effectively use unlabeled data: by exploring the task-specific semi-supervised approach, Cross-View Training (CVT) and comparing it with task-agnostic BERT in multiple settings that include domain and task relevant English data. CVT uses a much lighter model architecture and we show that it achieves similar performance to BERT on a set of sequence tagging tasks, with lesser financial and environmental impact.
Generating similes effortlessly like a Pro: A Style Transfer Approach for Simile Generation
Oct 03, 2020



Literary tropes, from poetry to stories, are at the crux of human imagination and communication. Figurative language such as a simile go beyond plain expressions to give readers new insights and inspirations. In this paper, we tackle the problem of simile generation. Generating a simile requires proper understanding for effective mapping of properties between two concepts. To this end, we first propose a method to automatically construct a parallel corpus by transforming a large number of similes collected from Reddit to their literal counterpart using structured common sense knowledge. We then propose to fine-tune a pretrained sequence to sequence model, BART~\cite{lewis2019bart}, on the literal-simile pairs to gain generalizability, so that we can generate novel similes given a literal sentence. Experiments show that our approach generates $88\%$ novel similes that do not share properties with the training data. Human evaluation on an independent set of literal statements shows that our model generates similes better than two literary experts \textit{37\%}\footnote{We average 32.6\% and 41.3\% for 2 humans.} of the times, and three baseline systems including a recent metaphor generation model \textit{71\%}\footnote{We average 82\% ,63\% and 68\% for three baselines.} of the times when compared pairwise.\footnote{The simile in the title is generated by our best model. Input: Generating similes effortlessly, output: Generating similes \textit{like a Pro}.} We also show how replacing literal sentences with similes from our best model in machine generated stories improves evocativeness and leads to better acceptance by human judges.
A Report on the 2020 Sarcasm Detection Shared Task
Jun 04, 2020

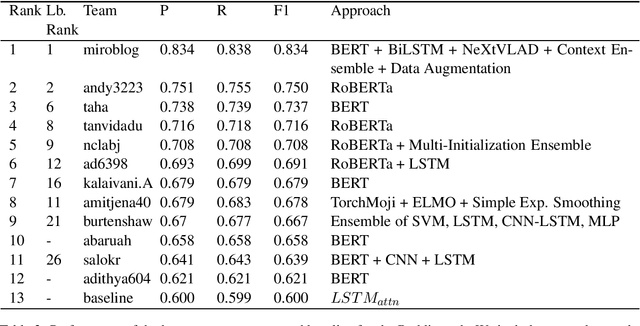
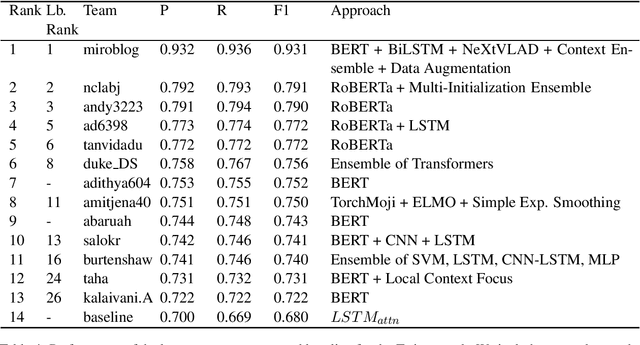
Detecting sarcasm and verbal irony is critical for understanding people's actual sentiments and beliefs. Thus, the field of sarcasm analysis has become a popular research problem in natural language processing. As the community working on computational approaches for sarcasm detection is growing, it is imperative to conduct benchmarking studies to analyze the current state-of-the-art, facilitating progress in this area. We report on the shared task on sarcasm detection we conducted as a part of the 2nd Workshop on Figurative Language Processing (FigLang 2020) at ACL 2020.