 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Hybrid-Optimization Video Coding
Jul 12, 2022

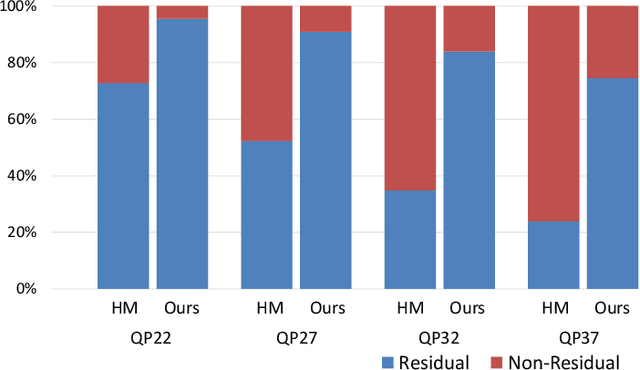
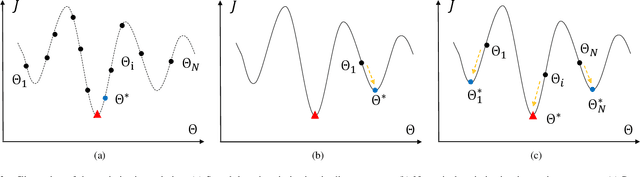
Video coding is a mathematical optimization problem of rate and distortion essentially. To solve this complex optimization problem, two popular video coding frameworks have been developed: block-based hybrid video coding and end-to-end learned video coding. If we rethink video coding from the perspective of optimization, we find that the existing two frameworks represent two directions of optimization solutions. Block-based hybrid coding represents the discrete optimization solution because those irrelevant coding modes are discrete in mathematics. It searches for the best one among multiple starting points (i.e. modes). However, the search is not efficient enough. On the other hand, end-to-end learned coding represents the continuous optimization solution because the gradient descent is based on a continuous function. It optimizes a group of model parameters efficiently by the numerical algorithm. However, limited by only one starting point, it is easy to fall into the local optimum. To better solve the optimization problem, we propose to regard video coding as a hybrid of the discrete and continuous optimization problem, and use both search and numerical algorithm to solve it. Our idea is to provide multiple discrete starting points in the global space and optimize the local optimum around each point by numerical algorithm efficiently. Finally, we search for the global optimum among those local optimums. Guided by the hybrid optimization idea, we design a hybrid optimization video coding framework, which is built on continuous deep networks entirely and also contains some discrete modes. We conduct a comprehensive set of experiments. Compared to the continuous optimization framework, our method outperforms pure learned video coding methods. Meanwhile, compared to the discrete optimization framework, our method achieves comparable performance to HEVC reference software HM16.10 in PSNR.
STIP: A SpatioTemporal Information-Preserving and Perception-Augmented Model for High-Resolution Video Prediction
Jun 09, 2022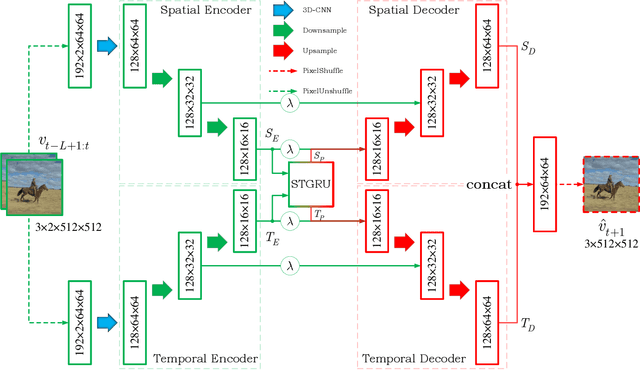
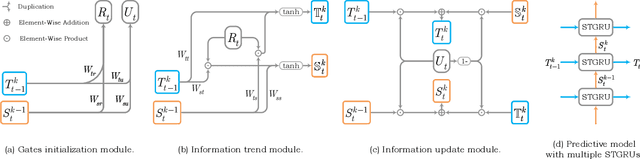
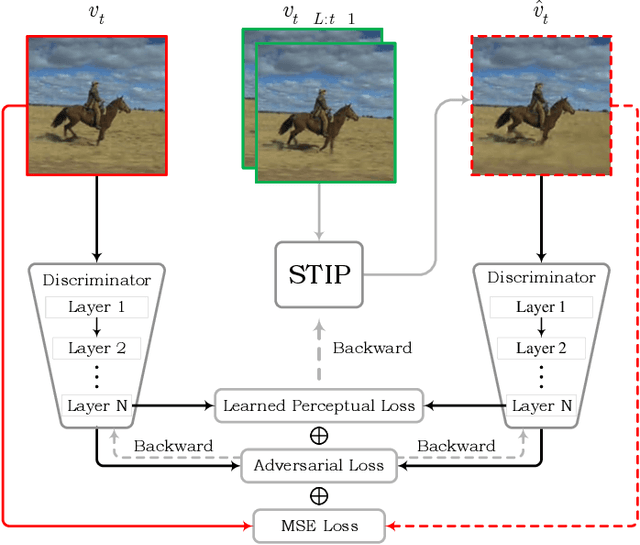

Although significant achievements have been achieved by recurrent neural network (RNN) based video prediction methods, their performance in datasets with high resolutions is still far from satisfactory because of the information loss problem and the perception-insensitive mean square error (MSE) based loss functions. In this paper, we propose a Spatiotemporal Information-Preserving and Perception-Augmented Model (STIP) to solve the above two problems. To solve the information loss problem, the proposed model aims to preserve the spatiotemporal information for videos during the feature extraction and the state transitions, respectively. Firstly, a Multi-Grained Spatiotemporal Auto-Encoder (MGST-AE) is designed based on the X-Net structure. The proposed MGST-AE can help the decoders recall multi-grained information from the encoders in both the temporal and spatial domains. In this way, more spatiotemporal information can be preserved during the feature extraction for high-resolution videos. Secondly, a Spatiotemporal Gated Recurrent Unit (STGRU) is designed based on the standard Gated Recurrent Unit (GRU) structure, which can efficiently preserve spatiotemporal information during the state transitions. The proposed STGRU can achieve more satisfactory performance with a much lower computation load compared with the popular Long Short-Term (LSTM) based predictive memories. Furthermore, to improve the traditional MSE loss functions, a Learned Perceptual Loss (LP-loss) is further designed based on the Generative Adversarial Networks (GANs), which can help obtain a satisfactory trade-off between the objective quality and the perceptual quality. Experimental results show that the proposed STIP can predict videos with more satisfactory visual quality compared with a variety of state-of-the-art methods. Source code has been available at \url{https://github.com/ZhengChang467/STIPHR}.
Hierarchical Similarity Learning for Aliasing Suppression Image Super-Resolution
Jun 07, 2022



As a highly ill-posed issue, single image super-resolution (SISR) has been widely investigated in recent years. The main task of SISR is to recover the information loss caused by the degradation procedure. According to the Nyquist sampling theory, the degradation leads to aliasing effect and makes it hard to restore the correct textures from low-resolution (LR) images. In practice, there are correlations and self-similarities among the adjacent patches in the natural images. This paper considers the self-similarity and proposes a hierarchical image super-resolution network (HSRNet) to suppress the influence of aliasing. We consider the SISR issue in the optimization perspective, and propose an iterative solution pattern based on the half-quadratic splitting (HQS) method. To explore the texture with local image prior, we design a hierarchical exploration block (HEB) and progressive increase the receptive field. Furthermore, multi-level spatial attention (MSA) is devised to obtain the relations of adjacent feature and enhance the high-frequency information, which acts as a crucial role for visual experience. Experimental result shows HSRNet achieves better quantitative and visual performance than other works, and remits the aliasing more effectively.
Textural-Structural Joint Learning for No-Reference Super-Resolution Image Quality Assessment
May 27, 2022
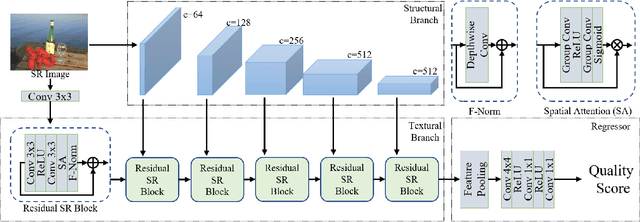
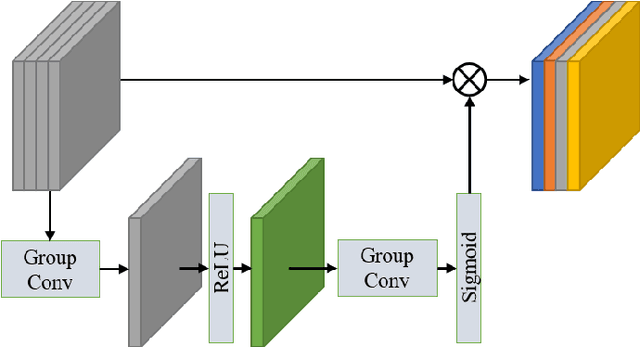

Image super-resolution (SR) has been widely investigated in recent years. However, it is challenging to fairly estimate the performances of various SR methods, as the lack of reliable and accurate criteria for perceptual quality. Existing SR image quality assessment (IQA) metrics usually concentrate on the specific kind of degradation without distinguishing the visual sensitive areas, which have no adaptive ability to describe the diverse SR degeneration situations. In this paper, we focus on the textural and structural degradation of image SR which acts as a critical role for visual perception, and design a dual stream network to jointly explore the textural and structural information for quality prediction, dubbed TSNet. By mimicking the human vision system (HVS) that pays more attention to the significant areas of the image, we develop the spatial attention mechanism to make the visual-sensitive areas more distinguishable, which improves the prediction accuracy. Feature normalization (F-Norm) is also developed to investigate the inherent spatial correlation of SR features and boost the network representation capacity. Experimental results show the proposed TSNet predicts the visual quality more accurate than the state-of-the-art IQA methods, and demonstrates better consistency with the human's perspective. The source code will be made available at http://github.com/yuqing-liu-dut/NRIQA_SR.
Learning Weighting Map for Bit-Depth Expansion within a Rational Range
Apr 26, 2022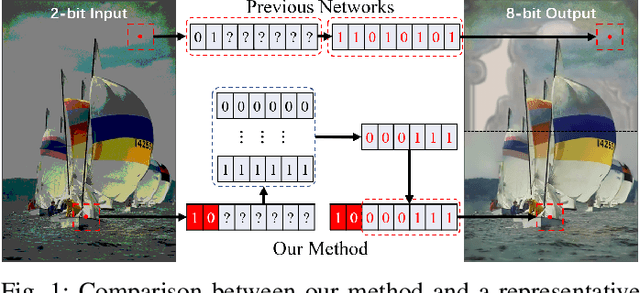


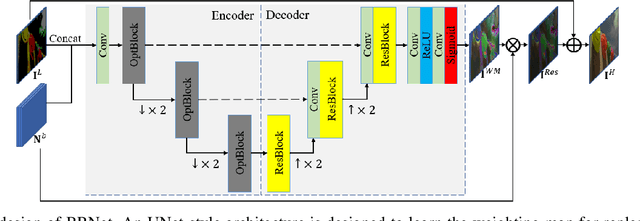
Bit-depth expansion (BDE) is one of the emerging technologies to display high bit-depth (HBD) image from low bit-depth (LBD) source. Existing BDE methods have no unified solution for various BDE situations, and directly learn a mapping for each pixel from LBD image to the desired value in HBD image, which may change the given high-order bits and lead to a huge deviation from the ground truth. In this paper, we design a bit restoration network (BRNet) to learn a weight for each pixel, which indicates the ratio of the replenished value within a rational range, invoking an accurate solution without modifying the given high-order bit information. To make the network adaptive for any bit-depth degradation, we investigate the issue in an optimization perspective and train the network under progressive training strategy for better performance. Moreover, we employ Wasserstein distance as a visual quality indicator to evaluate the difference of color distribution between restored image and the ground truth. Experimental results show our method can restore colorful images with fewer artifacts and false contours, and outperforms state-of-the-art methods with higher PSNR/SSIM results and lower Wasserstein distance. The source code will be made available at https://github.com/yuqing-liu-dut/bit-depth-expansion
STAU: A SpatioTemporal-Aware Unit for Video Prediction and Beyond
Apr 20, 2022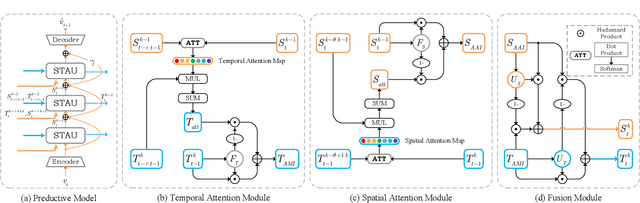


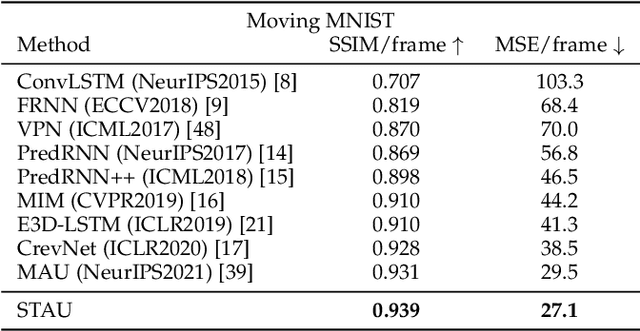
Video prediction aims to predict future frames by modeling the complex spatiotemporal dynamics in videos. However, most of the existing methods only model the temporal information and the spatial information for videos in an independent manner but haven't fully explored the correlations between both terms. In this paper, we propose a SpatioTemporal-Aware Unit (STAU) for video prediction and beyond by exploring the significant spatiotemporal correlations in videos. On the one hand, the motion-aware attention weights are learned from the spatial states to help aggregate the temporal states in the temporal domain. On the other hand, the appearance-aware attention weights are learned from the temporal states to help aggregate the spatial states in the spatial domain. In this way, the temporal information and the spatial information can be greatly aware of each other in both domains, during which, the spatiotemporal receptive field can also be greatly broadened for more reliable spatiotemporal modeling. Experiments are not only conducted on traditional video prediction tasks but also other tasks beyond video prediction, including the early action recognition and object detection tasks. Experimental results show that our STAU can outperform other methods on all tasks in terms of performance and computation efficiency.
STRPM: A Spatiotemporal Residual Predictive Model for High-Resolution Video Prediction
Mar 30, 2022
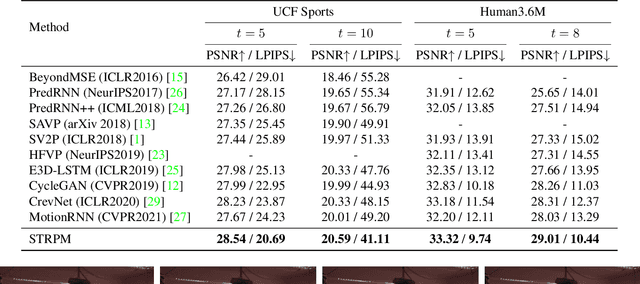
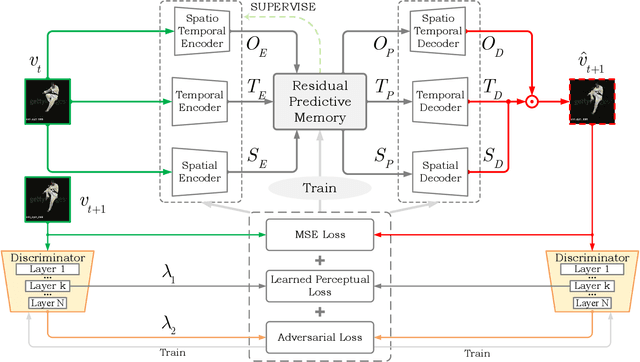
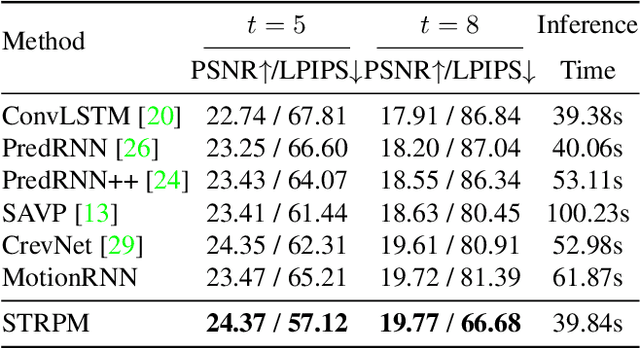
Although many video prediction methods have obtained good performance in low-resolution (64$\sim$128) videos, predictive models for high-resolution (512$\sim$4K) videos have not been fully explored yet, which are more meaningful due to the increasing demand for high-quality videos. Compared with low-resolution videos, high-resolution videos contain richer appearance (spatial) information and more complex motion (temporal) information. In this paper, we propose a Spatiotemporal Residual Predictive Model (STRPM) for high-resolution video prediction. On the one hand, we propose a Spatiotemporal Encoding-Decoding Scheme to preserve more spatiotemporal information for high-resolution videos. In this way, the appearance details for each frame can be greatly preserved. On the other hand, we design a Residual Predictive Memory (RPM) which focuses on modeling the spatiotemporal residual features (STRF) between previous and future frames instead of the whole frame, which can greatly help capture the complex motion information in high-resolution videos. In addition, the proposed RPM can supervise the spatial encoder and temporal encoder to extract different features in the spatial domain and the temporal domain, respectively. Moreover, the proposed model is trained using generative adversarial networks (GANs) with a learned perceptual loss (LP-loss) to improve the perceptual quality of the predictions. Experimental results show that STRPM can generate more satisfactory results compared with various existing methods.
P-STMO: Pre-Trained Spatial Temporal Many-to-One Model for 3D Human Pose Estimation
Mar 15, 2022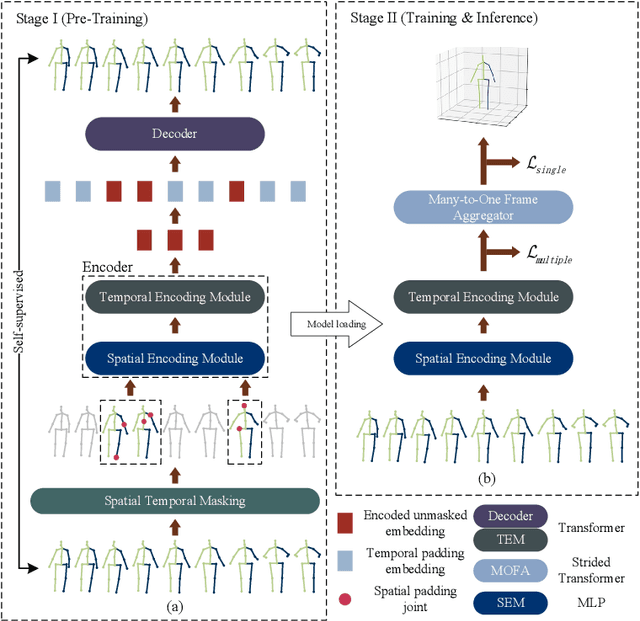
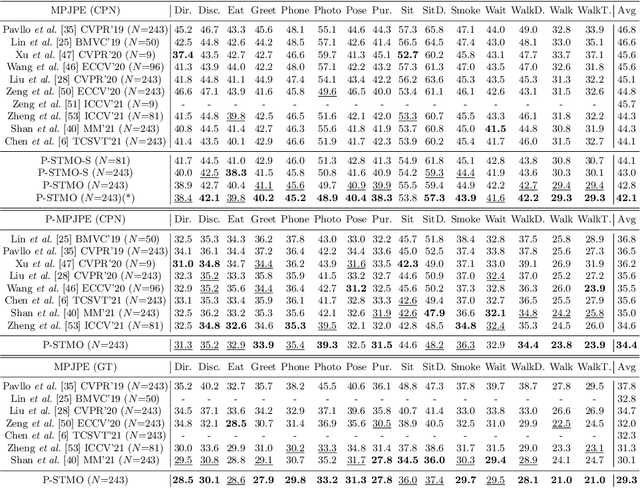

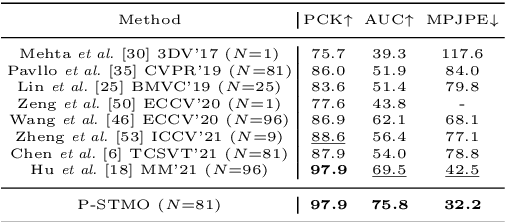
This paper introduces a novel Pre-trained Spatial Temporal Many-to-One (P-STMO) model for 2D-to-3D human pose estimation task. To reduce the difficulty of capturing spatial and temporal information, we divide this task into two stages: pre-training (Stage I) and fine-tuning (Stage II). In Stage I, a self-supervised pre-training sub-task, termed masked pose modeling, is proposed. The human joints in the input sequence are randomly masked in both spatial and temporal domains. A general form of denoising auto-encoder is exploited to recover the original 2D poses and the encoder is capable of capturing spatial and temporal dependencies in this way. In Stage II, the pre-trained encoder is loaded to STMO model and fine-tuned. The encoder is followed by a many-to-one frame aggregator to predict the 3D pose in the current frame. Especially, an MLP block is utilized as the spatial feature extractor in STMO, which yields better performance than other methods. In addition, a temporal downsampling strategy is proposed to diminish data redundancy. Extensive experiments on two benchmarks show that our method outperforms state-of-the-art methods with fewer parameters and less computational overhead. For example, our P-STMO model achieves 42.1mm MPJPE on Human3.6M dataset when using 2D poses from CPN as inputs. Meanwhile, it brings a 1.5-7.1 times speedup to state-of-the-art methods. Code is available at https://github.com/paTRICK-swk/P-STMO.
Cross-SRN: Structure-Preserving Super-Resolution Network with Cross Convolution
Jan 07, 2022



It is challenging to restore low-resolution (LR) images to super-resolution (SR) images with correct and clear details. Existing deep learning works almost neglect the inherent structural information of images, which acts as an important role for visual perception of SR results. In this paper, we design a hierarchical feature exploitation network to probe and preserve structural information in a multi-scale feature fusion manner. First, we propose a cross convolution upon traditional edge detectors to localize and represent edge features. Then, cross convolution blocks (CCBs) are designed with feature normalization and channel attention to consider the inherent correlations of features. Finally, we leverage multi-scale feature fusion group (MFFG) to embed the cross convolution blocks and develop the relations of structural features in different scales hierarchically, invoking a lightweight structure-preserving network named as Cross-SRN. Experimental results demonstrate the Cross-SRN achieves competitive or superior restoration performances against the state-of-the-art methods with accurate and clear structural details. Moreover, we set a criterion to select images with rich structural textures. The proposed Cross-SRN outperforms the state-of-the-art methods on the selected benchmark, which demonstrates that our network has a significant advantage in preserving edges.
COAST: COntrollable Arbitrary-Sampling NeTwork for Compressive Sensing
Jul 15, 2021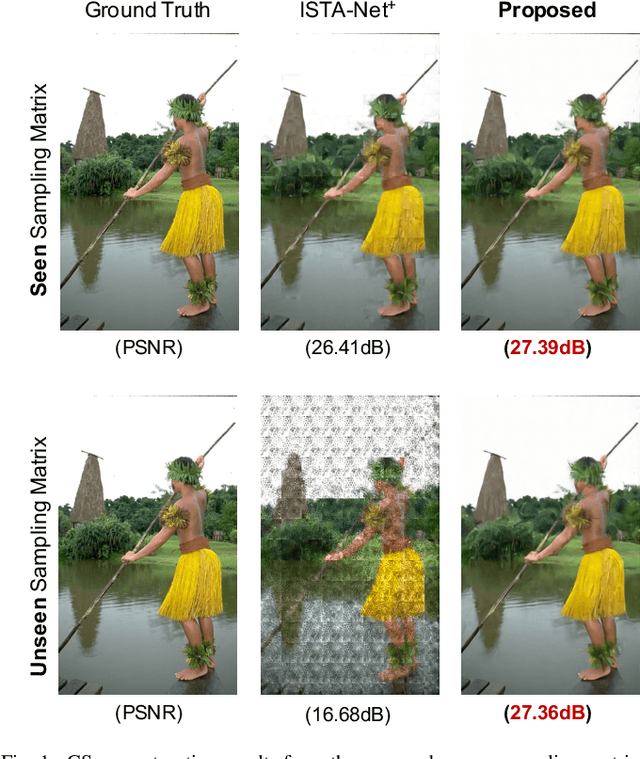



Recent deep network-based compressive sensing (CS) methods have achieved great success. However, most of them regard different sampling matrices as different independent tasks and need to train a specific model for each target sampling matrix. Such practices give rise to inefficiency in computing and suffer from poor generalization ability. In this paper, we propose a novel COntrollable Arbitrary-Sampling neTwork, dubbed COAST, to solve CS problems of arbitrary-sampling matrices (including unseen sampling matrices) with one single model. Under the optimization-inspired deep unfolding framework, our COAST exhibits good interpretability. In COAST, a random projection augmentation (RPA) strategy is proposed to promote the training diversity in the sampling space to enable arbitrary sampling, and a controllable proximal mapping module (CPMM) and a plug-and-play deblocking (PnP-D) strategy are further developed to dynamically modulate the network features and effectively eliminate the blocking artifacts, respectively. Extensive experiments on widely used benchmark datasets demonstrate that our proposed COAST is not only able to handle arbitrary sampling matrices with one single model but also to achieve state-of-the-art performance with fast speed. The source code is available on https://github.com/jianzhangcs/COAST.
* Published in IEEE Transactions on Image Processing, 2021