 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Maxima in the Likelihood of Gaussian Mixture Models: Structural Results and Algorithmic Consequences
Sep 04, 2016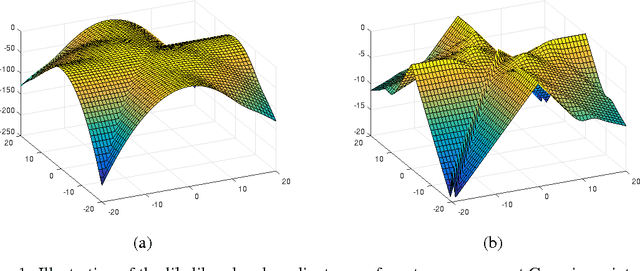
We provide two fundamental results on the population (infinite-sample) likelihood function of Gaussian mixture models with $M \geq 3$ components. Our first main result shows that the population likelihood function has bad local maxima even in the special case of equally-weighted mixtures of well-separated and spherical Gaussians. We prove that the log-likelihood value of these bad local maxima can be arbitrarily worse than that of any global optimum, thereby resolving an open question of Srebro (2007). Our second main result shows that the EM algorithm (or a first-order variant of it) with random initialization will converge to bad critical points with probability at least $1-e^{-\Omega(M)}$. We further establish that a first-order variant of EM will not converge to strict saddle points almost surely, indicating that the poor performance of the first-order method can be attributed to the existence of bad local maxima rather than bad saddle points. Overall, our results highlight the necessity of careful initialization when using the EM algorithm in practice, even when applied in highly favorable settings.
A Permutation-based Model for Crowd Labeling: Optimal Estimation and Robustness
Jun 30, 2016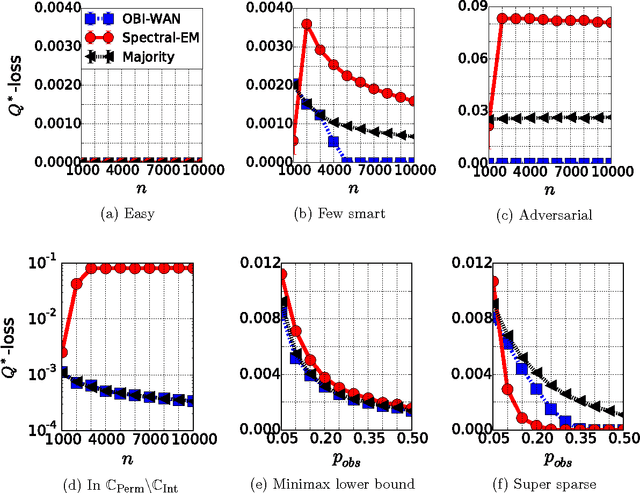
The aggregation and denoising of crowd labeled data is a task that has gained increased significance with the advent of crowdsourcing platforms and massive datasets. In this paper, we propose a permutation-based model for crowd labeled data that is a significant generalization of the common Dawid-Skene model, and introduce a new error metric by which to compare different estimators. Working in a high-dimensional non-asymptotic framework that allows both the number of workers and tasks to scale, we derive optimal rates of convergence for the permutation-based model. We show that the permutation-based model offers significant robustness in estimation due to its richness, while surprisingly incurring only a small additional statistical penalty as compared to the Dawid-Skene model. Finally, we propose a computationally-efficient method, called the OBI-WAN estimator, that is uniformly optimal over a class intermediate between the permutation-based and the Dawid-Skene models, and is uniformly consistent over the entire permutation-based model class. In contrast, the guarantees for estimators available in prior literature are sub-optimal over the original Dawid-Skene model.
Arbitrage-Free Combinatorial Market Making via Integer Programming
Jun 10, 2016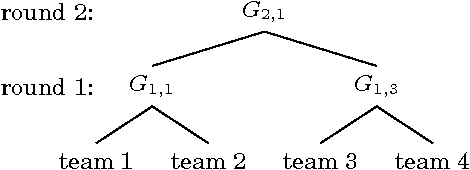
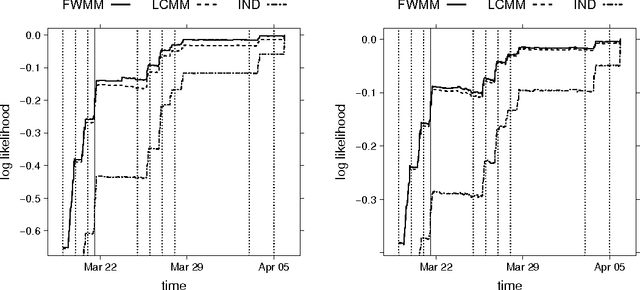
We present a new combinatorial market maker that operates arbitrage-free combinatorial prediction markets specified by integer programs. Although the problem of arbitrage-free pricing, while maintaining a bound on the subsidy provided by the market maker, is #P-hard in the worst case, we posit that the typical case might be amenable to modern integer programming (IP) solvers. At the crux of our method is the Frank-Wolfe (conditional gradient) algorithm which is used to implement a Bregman projection aligned with the market maker's cost function, using an IP solver as an oracle. We demonstrate the tractability and improved accuracy of our approach on real-world prediction market data from combinatorial bets placed on the 2010 NCAA Men's Division I Basketball Tournament, where the outcome space is of size 2^63. To our knowledge, this is the first implementation and empirical evaluation of an arbitrage-free combinatorial prediction market on this scale.
Feeling the Bern: Adaptive Estimators for Bernoulli Probabilities of Pairwise Comparisons
Mar 22, 2016
We study methods for aggregating pairwise comparison data in order to estimate outcome probabilities for future comparisons among a collection of n items. Working within a flexible framework that imposes only a form of strong stochastic transitivity (SST), we introduce an adaptivity index defined by the indifference sets of the pairwise comparison probabilities. In addition to measuring the usual worst-case risk of an estimator, this adaptivity index also captures the extent to which the estimator adapts to instance-specific difficulty relative to an oracle estimator. We prove three main results that involve this adaptivity index and different algorithms. First, we propose a three-step estimator termed Count-Randomize-Least squares (CRL), and show that it has adaptivity index upper bounded as $\sqrt{n}$ up to logarithmic factors. We then show that that conditional on the hardness of planted clique, no computationally efficient estimator can achieve an adaptivity index smaller than $\sqrt{n}$. Second, we show that a regularized least squares estimator can achieve a poly-logarithmic adaptivity index, thereby demonstrating a $\sqrt{n}$-gap between optimal and computationally achievable adaptivity. Finally, we prove that the standard least squares estimator, which is known to be optimally adaptive in several closely related problems, fails to adapt in the context of estimating pairwise probabilities.
Statistical and Computational Guarantees for the Baum-Welch Algorithm
Dec 27, 2015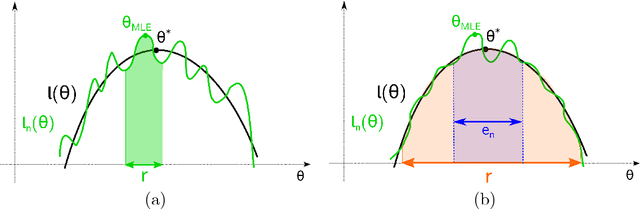
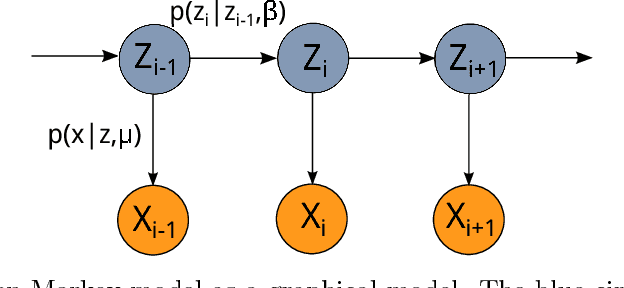
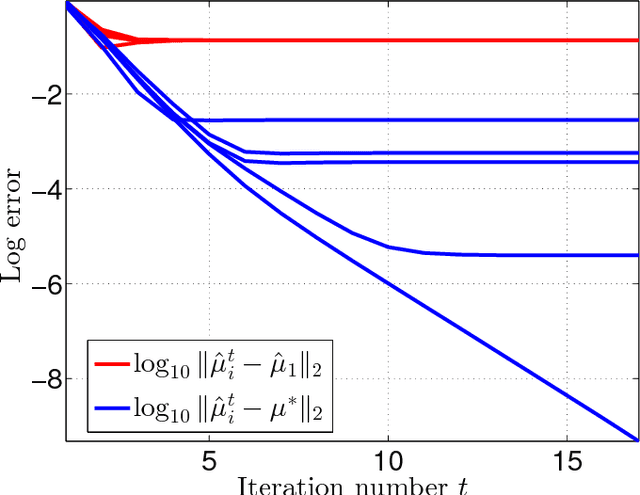
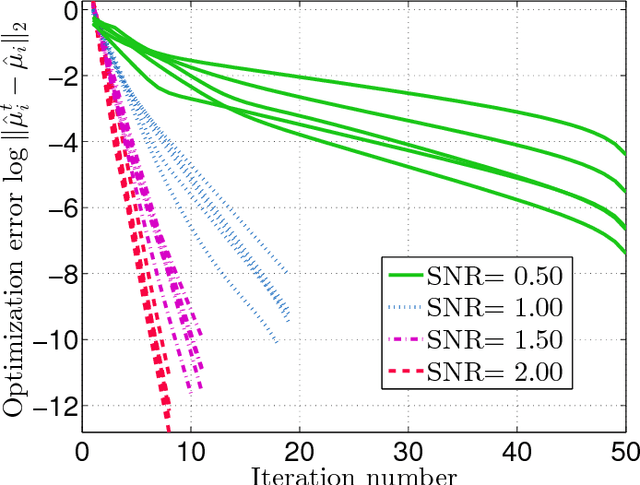
The Hidden Markov Model (HMM) is one of the mainstays of statistical modeling of discrete time series, with applications including speech recognition, computational biology, computer vision and econometrics. Estimating an HMM from its observation process is often addressed via the Baum-Welch algorithm, which is known to be susceptible to local optima. In this paper, we first give a general characterization of the basin of attraction associated with any global optimum of the population likelihood. By exploiting this characterization, we provide non-asymptotic finite sample guarantees on the Baum-Welch updates, guaranteeing geometric convergence to a small ball of radius on the order of the minimax rate around a global optimum. As a concrete example, we prove a linear rate of convergence for a hidden Markov mixture of two isotropic Gaussians given a suitable mean separation and an initialization within a ball of large radius around (one of) the true parameters. To our knowledge, these are the first rigorous local convergence guarantees to global optima for the Baum-Welch algorithm in a setting where the likelihood function is nonconvex. We complement our theoretical results with thorough numerical simulations studying the convergence of the Baum-Welch algorithm and illustrating the accuracy of our predictions.
Estimation from Pairwise Comparisons: Sharp Minimax Bounds with Topology Dependence
May 06, 2015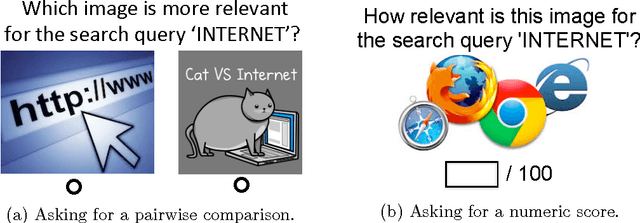
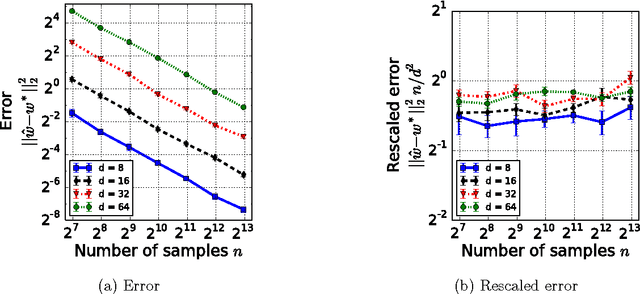

Data in the form of pairwise comparisons arises in many domains, including preference elicitation, sporting competitions, and peer grading among others. We consider parametric ordinal models for such pairwise comparison data involving a latent vector $w^* \in \mathbb{R}^d$ that represents the "qualities" of the $d$ items being compared; this class of models includes the two most widely used parametric models--the Bradley-Terry-Luce (BTL) and the Thurstone models. Working within a standard minimax framework, we provide tight upper and lower bounds on the optimal error in estimating the quality score vector $w^*$ under this class of models. The bounds depend on the topology of the comparison graph induced by the subset of pairs being compared via its Laplacian spectrum. Thus, in settings where the subset of pairs may be chosen, our results provide principled guidelines for making this choice. Finally, we compare these error rates to those under cardinal measurement models and show that the error rates in the ordinal and cardinal settings have identical scalings apart from constant pre-factors.
Confidence sets for persistence diagrams
Nov 20, 2014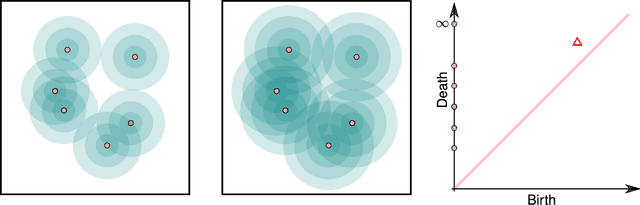
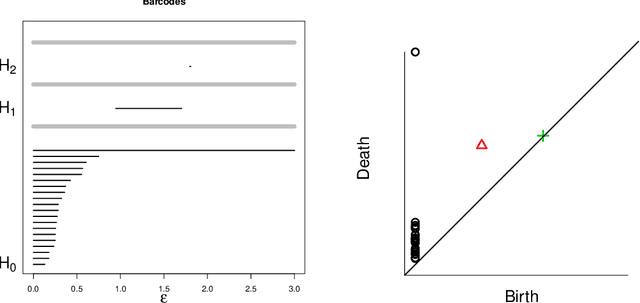
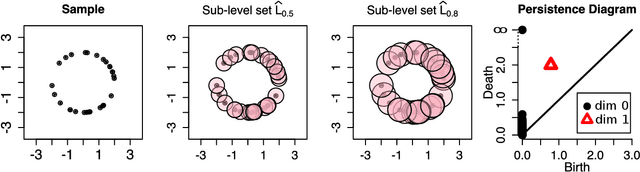
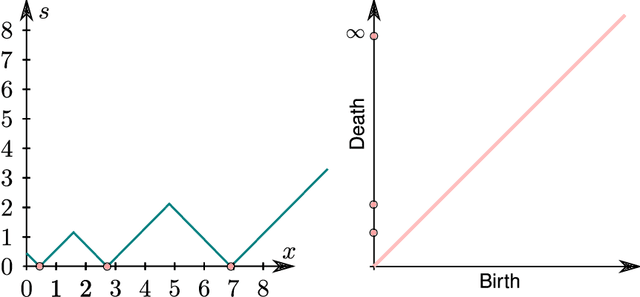
Persistent homology is a method for probing topological properties of point clouds and functions. The method involves tracking the birth and death of topological features (2000) as one varies a tuning parameter. Features with short lifetimes are informally considered to be "topological noise," and those with a long lifetime are considered to be "topological signal." In this paper, we bring some statistical ideas to persistent homology. In particular, we derive confidence sets that allow us to separate topological signal from topological noise.
* Published in at http://dx.doi.org/10.1214/14-AOS1252 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Statistical guarantees for the EM algorithm: From population to sample-based analysis
Aug 09, 2014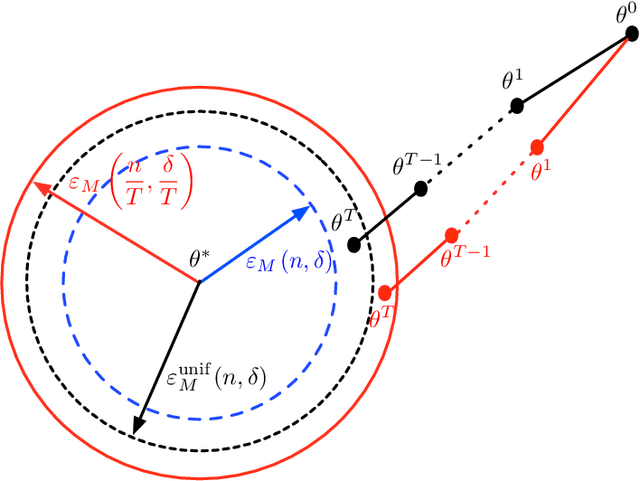
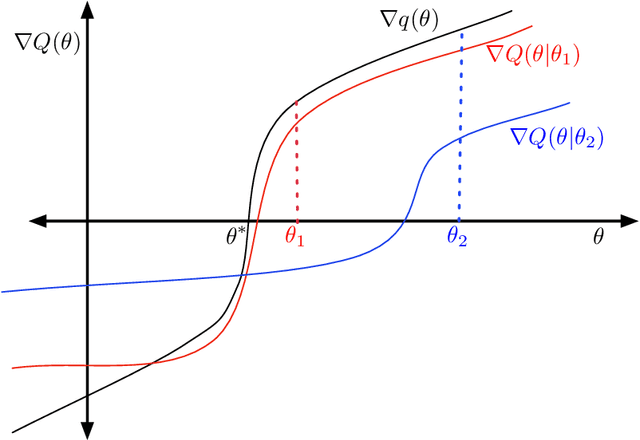
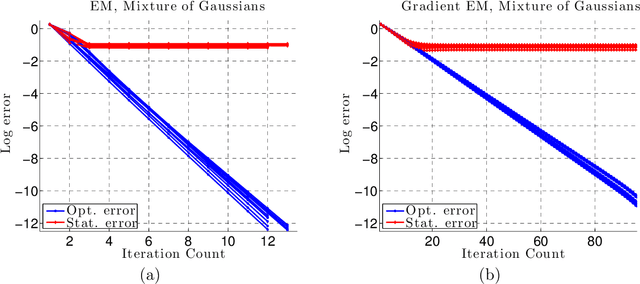
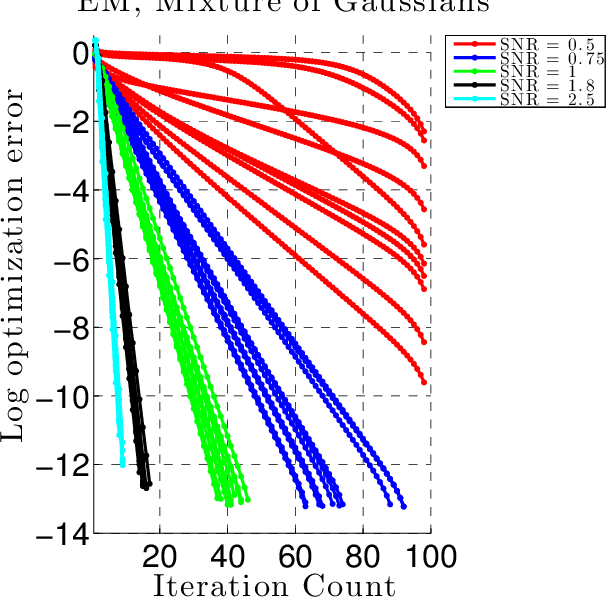
We develop a general framework for proving rigorous guarantees on the performance of the EM algorithm and a variant known as gradient EM. Our analysis is divided into two parts: a treatment of these algorithms at the population level (in the limit of infinite data), followed by results that apply to updates based on a finite set of samples. First, we characterize the domain of attraction of any global maximizer of the population likelihood. This characterization is based on a novel view of the EM updates as a perturbed form of likelihood ascent, or in parallel, of the gradient EM updates as a perturbed form of standard gradient ascent. Leveraging this characterization, we then provide non-asymptotic guarantees on the EM and gradient EM algorithms when applied to a finite set of samples. We develop consequences of our general theory for three canonical examples of incomplete-data problems: mixture of Gaussians, mixture of regressions, and linear regression with covariates missing completely at random. In each case, our theory guarantees that with a suitable initialization, a relatively small number of EM (or gradient EM) steps will yield (with high probability) an estimate that is within statistical error of the MLE. We provide simulations to confirm this theoretically predicted behavior.
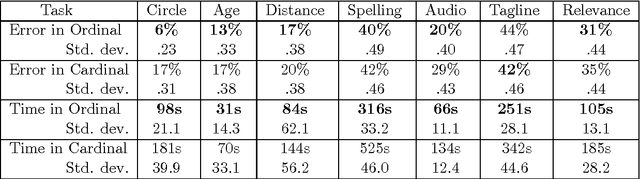
When is it Better to Compare than to Score?
Jun 25, 2014

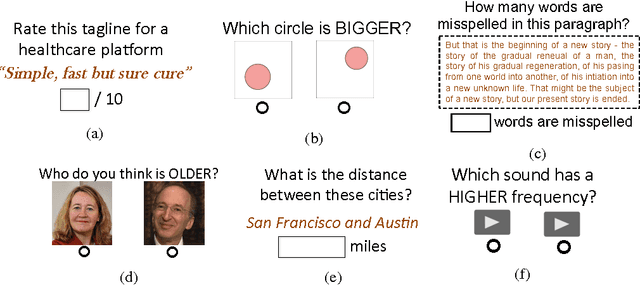
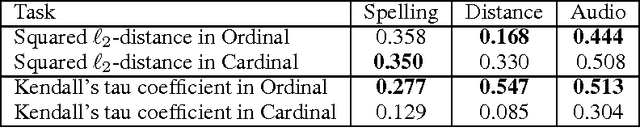
When eliciting judgements from humans for an unknown quantity, one often has the choice of making direct-scoring (cardinal) or comparative (ordinal) measurements. In this paper we study the relative merits of either choice, providing empirical and theoretical guidelines for the selection of a measurement scheme. We provide empirical evidence based on experiments on Amazon Mechanical Turk that in a variety of tasks, (pairwise-comparative) ordinal measurements have lower per sample noise and are typically faster to elicit than cardinal ones. Ordinal measurements however typically provide less information. We then consider the popular Thurstone and Bradley-Terry-Luce (BTL) models for ordinal measurements and characterize the minimax error rates for estimating the unknown quantity. We compare these minimax error rates to those under cardinal measurement models and quantify for what noise levels ordinal measurements are better. Finally, we revisit the data collected from our experiments and show that fitting these models confirms this prediction: for tasks where the noise in ordinal measurements is sufficiently low, the ordinal approach results in smaller errors in the estimation.
Tight Lower Bounds for Homology Inference
Jul 29, 2013The homology groups of a manifold are important topological invariants that provide an algebraic summary of the manifold. These groups contain rich topological information, for instance, about the connected components, holes, tunnels and sometimes the dimension of the manifold. In earlier work, we have considered the statistical problem of estimating the homology of a manifold from noiseless samples and from noisy samples under several different noise models. We derived upper and lower bounds on the minimax risk for this problem. In this note we revisit the noiseless case. In previous work we used Le Cam's lemma to establish a lower bound that differed from the upper bound of Niyogi, Smale and Weinberger by a polynomial factor in the condition number. In this note we use a different construction based on the direct analysis of the likelihood ratio test to show that the upper bound of Niyogi, Smale and Weinberger is in fact tight, thus establishing rate optimal asymptotic minimax bounds for the problem. The techniques we use here extend in a straightforward way to the noisy settings considered in our earlier work.