 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOUL: Towards Sentiment and Opinion Understanding of Language
Oct 27, 2023Sentiment analysis is a well-established natural language processing task, with sentiment polarity classification being one of its most popular and representative tasks. However, despite the success of pre-trained language models in this area, they often fall short of capturing the broader complexities of sentiment analysis. To address this issue, we propose a new task called Sentiment and Opinion Understanding of Language (SOUL). SOUL aims to evaluate sentiment understanding through two subtasks: Review Comprehension (RC) and Justification Generation (JG). RC seeks to validate statements that focus on subjective information based on a review text, while JG requires models to provide explanations for their sentiment predictions. To enable comprehensive evaluation, we annotate a new dataset comprising 15,028 statements from 3,638 reviews. Experimental results indicate that SOUL is a challenging task for both small and large language models, with a performance gap of up to 27% when compared to human performance. Furthermore, evaluations conducted with both human experts and GPT-4 highlight the limitations of the small language model in generating reasoning-based justifications. These findings underscore the challenging nature of the SOUL task for existing models, emphasizing the need for further advancements in sentiment analysis to address its complexities. The new dataset and code are available at https://github.com/DAMO-NLP-SG/SOUL.
Multilingual Jailbreak Challenges in Large Language Models
Oct 10, 2023While large language models (LLMs) exhibit remarkable capabilities across a wide range of tasks, they pose potential safety concerns, such as the ``jailbreak'' problem, wherein malicious instructions can manipulate LLMs to exhibit undesirable behavior. Although several preventive measures have been developed to mitigate the potential risks associated with LLMs, they have primarily focused on English data. In this study, we reveal the presence of multilingual jailbreak challenges within LLMs and consider two potential risk scenarios: unintentional and intentional. The unintentional scenario involves users querying LLMs using non-English prompts and inadvertently bypassing the safety mechanisms, while the intentional scenario concerns malicious users combining malicious instructions with multilingual prompts to deliberately attack LLMs. The experimental results reveal that in the unintentional scenario, the rate of unsafe content increases as the availability of languages decreases. Specifically, low-resource languages exhibit three times the likelihood of encountering harmful content compared to high-resource languages, with both ChatGPT and GPT-4. In the intentional scenario, multilingual prompts can exacerbate the negative impact of malicious instructions, with astonishingly high rates of unsafe output: 80.92\% for ChatGPT and 40.71\% for GPT-4. To handle such a challenge in the multilingual context, we propose a novel \textsc{Self-Defense} framework that automatically generates multilingual training data for safety fine-tuning. Experimental results show that ChatGPT fine-tuned with such data can achieve a substantial reduction in unsafe content generation. Data is available at https://github.com/DAMO-NLP-SG/multilingual-safety-for-LLMs. Warning: This paper contains examples with potentially harmful content.
Sentiment Analysis in the Era of Large Language Models: A Reality Check
May 24, 2023



Sentiment analysis (SA) has been a long-standing research area in natural language processing. It can offer rich insights into human sentiments and opinions and has thus seen considerable interest from both academia and industry. With the advent of large language models (LLMs) such as ChatGPT, there is a great potential for their employment on SA problems. However, the extent to which existing LLMs can be leveraged for different sentiment analysis tasks remains unclear. This paper aims to provide a comprehensive investigation into the capabilities of LLMs in performing various sentiment analysis tasks, from conventional sentiment classification to aspect-based sentiment analysis and multifaceted analysis of subjective texts. We evaluate performance across 13 tasks on 26 datasets and compare the results against small language models (SLMs) trained on domain-specific datasets. Our study reveals that while LLMs demonstrate satisfactory performance in simpler tasks, they lag behind in more complex tasks requiring deeper understanding or structured sentiment information. However, LLMs significantly outperform SLMs in few-shot learning settings, suggesting their potential when annotation resources are limited. We also highlight the limitations of current evaluation practices in assessing LLMs' SA abilities and propose a novel benchmark, \textsc{SentiEval}, for a more comprehensive and realistic evaluation. Data and code during our investigations are available at \url{https://github.com/DAMO-NLP-SG/LLM-Sentiment}.
Bidirectional Generative Framework for Cross-domain Aspect-based Sentiment Analysis
May 16, 2023Cross-domain aspect-based sentiment analysis (ABSA) aims to perform various fine-grained sentiment analysis tasks on a target domain by transferring knowledge from a source domain. Since labeled data only exists in the source domain, a model is expected to bridge the domain gap for tackling cross-domain ABSA. Though domain adaptation methods have proven to be effective, most of them are based on a discriminative model, which needs to be specifically designed for different ABSA tasks. To offer a more general solution, we propose a unified bidirectional generative framework to tackle various cross-domain ABSA tasks. Specifically, our framework trains a generative model in both text-to-label and label-to-text directions. The former transforms each task into a unified format to learn domain-agnostic features, and the latter generates natural sentences from noisy labels for data augmentation, with which a more accurate model can be trained. To investigate the effectiveness and generality of our framework, we conduct extensive experiments on four cross-domain ABSA tasks and present new state-of-the-art results on all tasks. Our data and code are publicly available at \url{https://github.com/DAMO-NLP-SG/BGCA}.
Learning Generalizable Representations for Reinforcement Learning via Adaptive Meta-learner of Behavioral Similarities
Dec 26, 2022How to learn an effective reinforcement learning-based model for control tasks from high-level visual observations is a practical and challenging problem. A key to solving this problem is to learn low-dimensional state representations from observations, from which an effective policy can be learned. In order to boost the learning of state encoding, recent works are focused on capturing behavioral similarities between state representations or applying data augmentation on visual observations. In this paper, we propose a novel meta-learner-based framework for representation learning regarding behavioral similarities for reinforcement learning. Specifically, our framework encodes the high-dimensional observations into two decomposed embeddings regarding reward and dynamics in a Markov Decision Process (MDP). A pair of meta-learners are developed, one of which quantifies the reward similarity and the other quantifies dynamics similarity over the correspondingly decomposed embeddings. The meta-learners are self-learned to update the state embeddings by approximating two disjoint terms in on-policy bisimulation metric. To incorporate the reward and dynamics terms, we further develop a strategy to adaptively balance their impacts based on different tasks or environments. We empirically demonstrate that our proposed framework outperforms state-of-the-art baselines on several benchmarks, including conventional DM Control Suite, Distracting DM Control Suite and a self-driving task CARLA.
Fast Graph Generation via Spectral Diffusion
Nov 19, 2022Generating graph-structured data is a challenging problem, which requires learning the underlying distribution of graphs. Various models such as graph VAE, graph GANs, and graph diffusion models have been proposed to generate meaningful and reliable graphs, among which the diffusion models have achieved state-of-the-art performance. In this paper, we argue that running full-rank diffusion SDEs on the whole graph adjacency matrix space hinders diffusion models from learning graph topology generation, and hence significantly deteriorates the quality of generated graph data. To address this limitation, we propose an efficient yet effective Graph Spectral Diffusion Model (GSDM), which is driven by low-rank diffusion SDEs on the graph spectrum space. Our spectral diffusion model is further proven to enjoy a substantially stronger theoretical guarantee than standard diffusion models. Extensive experiments across various datasets demonstrate that, our proposed GSDM turns out to be the SOTA model, by exhibiting both significantly higher generation quality and much less computational consumption than the baselines.
Learning Gradient-based Mixup towards Flatter Minima for Domain Generalization
Sep 29, 2022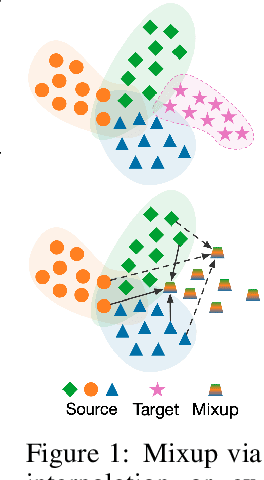
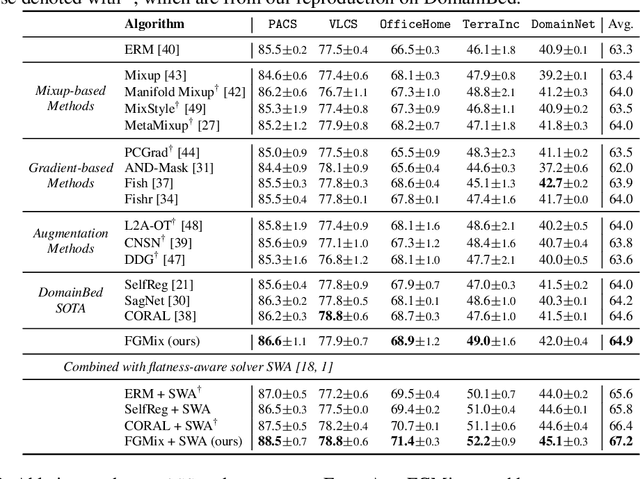
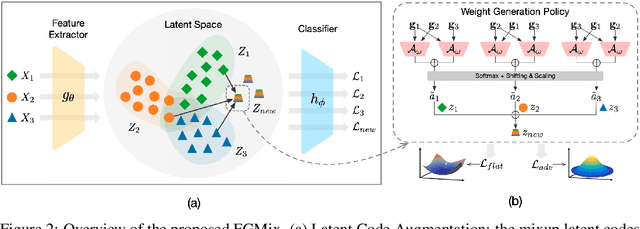
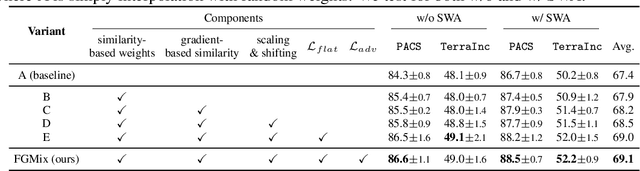
To address the distribution shifts between training and test data, domain generalization (DG) leverages multiple source domains to learn a model that generalizes well to unseen domains. However, existing DG methods generally suffer from overfitting to the source domains, partly due to the limited coverage of the expected region in feature space. Motivated by this, we propose to perform mixup with data interpolation and extrapolation to cover the potential unseen regions. To prevent the detrimental effects of unconstrained extrapolation, we carefully design a policy to generate the instance weights, named Flatness-aware Gradient-based Mixup (FGMix). The policy employs a gradient-based similarity to assign greater weights to instances that carry more invariant information, and learns the similarity function towards flatter minima for better generalization. On the DomainBed benchmark, we validate the efficacy of various designs of FGMix and demonstrate its superiority over other DG algorithms.
Domain Confused Contrastive Learning for Unsupervised Domain Adaptation
Jul 10, 2022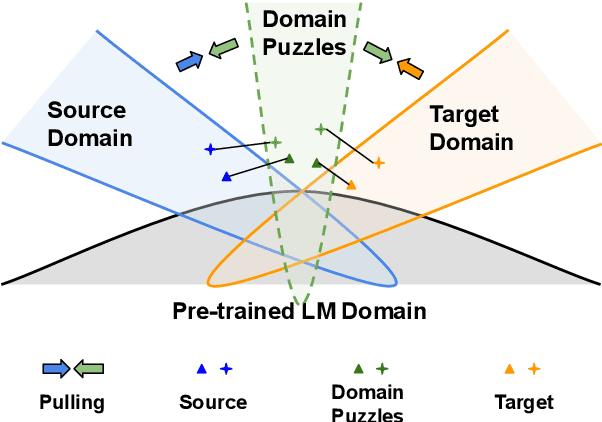

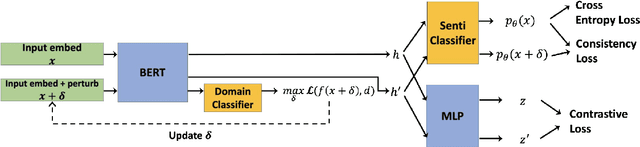
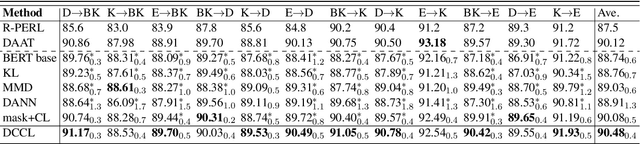
In this work, we study Unsupervised Domain Adaptation (UDA) in a challenging self-supervised approach. One of the difficulties is how to learn task discrimination in the absence of target labels. Unlike previous literature which directly aligns cross-domain distributions or leverages reverse gradient, we propose Domain Confused Contrastive Learning (DCCL) to bridge the source and the target domains via domain puzzles, and retain discriminative representations after adaptation. Technically, DCCL searches for a most domain-challenging direction and exquisitely crafts domain confused augmentations as positive pairs, then it contrastively encourages the model to pull representations towards the other domain, thus learning more stable and effective domain invariances. We also investigate whether contrastive learning necessarily helps with UDA when performing other data augmentations. Extensive experiments demonstrate that DCCL significantly outperforms baselines.
Semantic-Discriminative Mixup for Generalizable Sensor-based Cross-domain Activity Recognition
Jun 14, 2022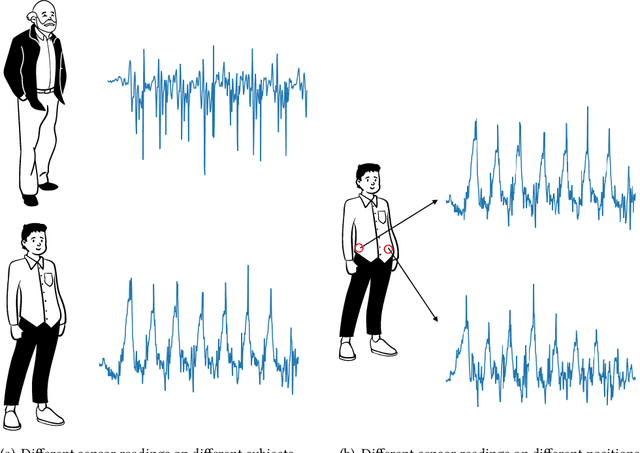
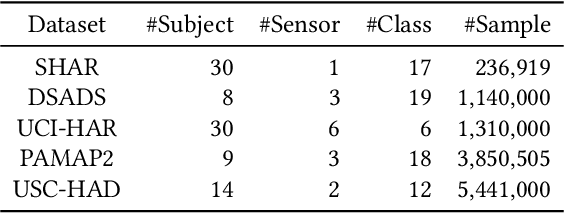
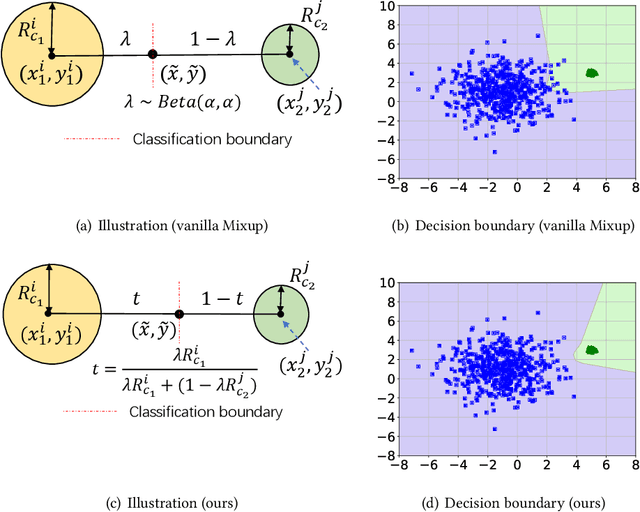
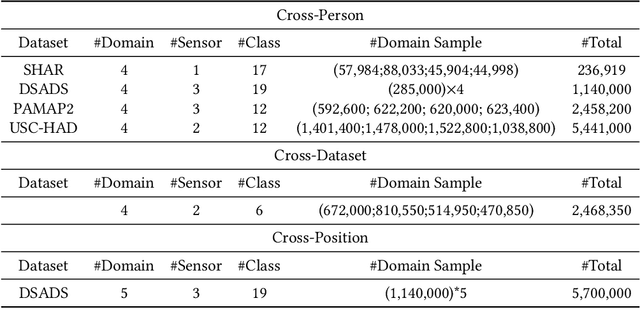
It is expensive and time-consuming to collect sufficient labeled data to build human activity recognition (HAR) models. Training on existing data often makes the model biased towards the distribution of the training data, thus the model might perform terribly on test data with different distributions. Although existing efforts on transfer learning and domain adaptation try to solve the above problem, they still need access to unlabeled data on the target domain, which may not be possible in real scenarios. Few works pay attention to training a model that can generalize well to unseen target domains for HAR. In this paper, we propose a novel method called Semantic-Discriminative Mixup (SDMix) for generalizable cross-domain HAR. Firstly, we introduce semantic-aware Mixup that considers the activity semantic ranges to overcome the semantic inconsistency brought by domain differences. Secondly, we introduce the large margin loss to enhance the discrimination of Mixup to prevent misclassification brought by noisy virtual labels. Comprehensive generalization experiments on five public datasets demonstrate that our SDMix substantially outperforms the state-of-the-art approaches with 6% average accuracy improvement on cross-person, cross-dataset, and cross-position HAR.
Learning an Adaptive Meta Model-Generator for Incrementally Updating Recommender Systems
Nov 08, 2021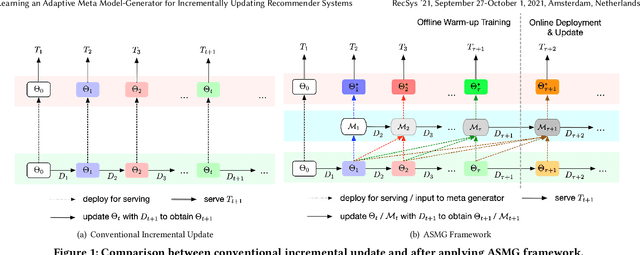
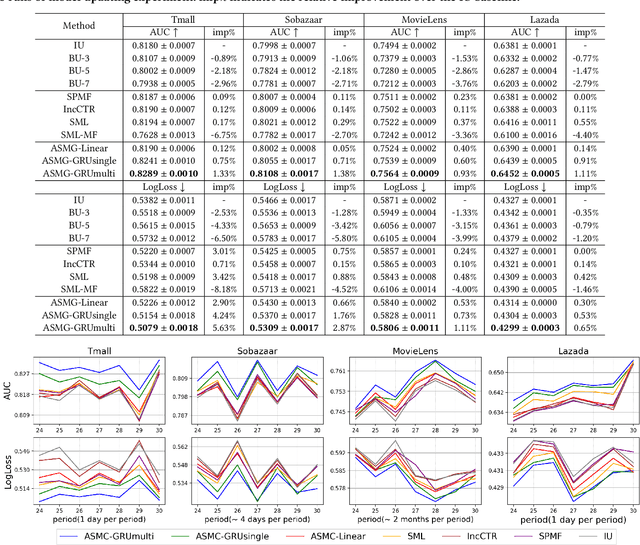
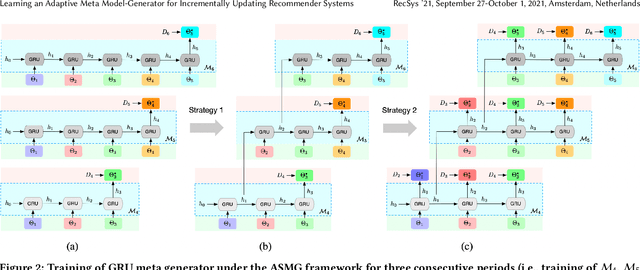
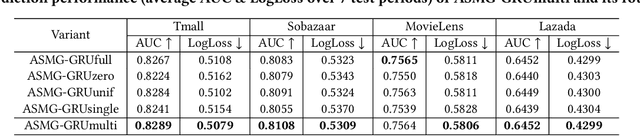
Recommender Systems (RSs) in real-world applications often deal with billions of user interactions daily. To capture the most recent trends effectively, it is common to update the model incrementally using only the newly arrived data. However, this may impede the model's ability to retain long-term information due to the potential overfitting and forgetting issues. To address this problem, we propose a novel Adaptive Sequential Model Generation (ASMG) framework, which generates a better serving model from a sequence of historical models via a meta generator. For the design of the meta generator, we propose to employ Gated Recurrent Units (GRUs) to leverage its ability to capture the long-term dependencies. We further introduce some novel strategies to apply together with the GRU meta generator, which not only improve its computational efficiency but also enable more accurate sequential modeling. By instantiating the model-agnostic framework on a general deep learning-based RS model, we demonstrate that our method achieves state-of-the-art performance on three public datasets and one industrial dataset.