 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASE: Cadence-Aware Set Encoding for Large-Scale Next Basket Repurchase Recommendation
Apr 09, 2026Repurchase behavior is a primary signal in large-scale retail recommendation, particularly in categories with frequent replenishment: many items in a user's next basket were previously purchased and their timing follows stable, item-specific cadences. Yet most next basket repurchase recommendation models represent history as a sequence of discrete basket events indexed by visit order, which cannot explicitly model elapsed calendar time or update item rankings as days pass between purchases. We present CASE (Cadence-Aware Set Encoding for next basket repurchase recommendation), which decouples item-level cadence learning from cross-item interaction, enabling explicit calendar-time modeling while remaining production-scalable. CASE represents each item's purchase history as a calendar-time signal over a fixed horizon, applies shared multi-scale temporal convolutions to capture recurring rhythms, and uses induced set attention to model cross-item dependencies with sub-quadratic complexity, allowing efficient batch inference at scale. Across three public benchmarks and a proprietary dataset, CASE consistently improves Precision, Recall, and NDCG at multiple cutoffs compared to strong next basket prediction baselines. In a production-scale evaluation with tens of millions of users and a large item catalog, CASE achieves up to 8.6% relative Precision and 9.9% Recall lift at top-5, demonstrating that scalable cadence-aware modeling yields measurable gains in both benchmark and industrial settings.
Campaign-2-PT-RAG: LLM-Guided Semantic Product Type Attribution for Scalable Campaign Ranking
Feb 11, 2026E-commerce campaign ranking models require large-scale training labels indicating which users purchased due to campaign influence. However, generating these labels is challenging because campaigns use creative, thematic language that does not directly map to product purchases. Without clear product-level attribution, supervised learning for campaign optimization remains limited. We present \textbf{Campaign-2-PT-RAG}, a scalable label generation framework that constructs user--campaign purchase labels by inferring which product types (PTs) each campaign promotes. The framework first interprets campaign content using large language models (LLMs) to capture implicit intent, then retrieves candidate PTs through semantic search over the platform taxonomy. A structured LLM-based classifier evaluates each PT's relevance, producing a campaign-specific product coverage set. User purchases matching these PTs generate positive training labels for downstream ranking models. This approach reframes the ambiguous attribution problem into a tractable semantic alignment task, enabling scalable and consistent supervision for downstream tasks such as campaign ranking optimization in production e-commerce environments. Experiments on internal and synthetic datasets, validated against expert-annotated campaign--PT mappings, show that our LLM-assisted approach generates high-quality labels with 78--90% precision while maintaining over 99% recall.
Is More Context Always Better? Examining LLM Reasoning Capability for Time Interval Prediction
Jan 15, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning and prediction across different domains. Yet, their ability to infer temporal regularities from structured behavioral data remains underexplored. This paper presents a systematic study investigating whether LLMs can predict time intervals between recurring user actions, such as repeated purchases, and how different levels of contextual information shape their predictive behavior. Using a simple but representative repurchase scenario, we benchmark state-of-the-art LLMs in zero-shot settings against both statistical and machine-learning models. Two key findings emerge. First, while LLMs surpass lightweight statistical baselines, they consistently underperform dedicated machine-learning models, showing their limited ability to capture quantitative temporal structure. Second, although moderate context can improve LLM accuracy, adding further user-level detail degrades performance. These results challenge the assumption that "more context leads to better reasoning". Our study highlights fundamental limitations of today's LLMs in structured temporal inference and offers guidance for designing future context-aware hybrid models that integrate statistical precision with linguistic flexibility.
Spatial Reasoning in Foundation Models: Benchmarking Object-Centric Spatial Understanding
Sep 26, 2025
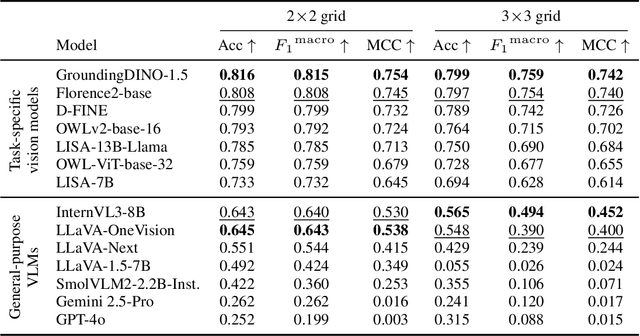

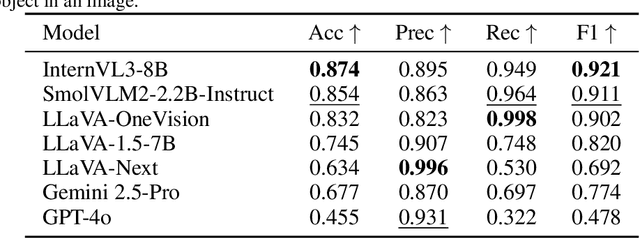
Spatial understanding is a critical capability for vision foundation models. While recent advances in large vision models or vision-language models (VLMs) have expanded recognition capabilities, most benchmarks emphasize localization accuracy rather than whether models capture how objects are arranged and related within a scene. This gap is consequential; effective scene understanding requires not only identifying objects, but reasoning about their relative positions, groupings, and depth. In this paper, we present a systematic benchmark for object-centric spatial reasoning in foundation models. Using a controlled synthetic dataset, we evaluate state-of-the-art vision models (e.g., GroundingDINO, Florence-2, OWLv2) and large VLMs (e.g., InternVL, LLaVA, GPT-4o) across three tasks: spatial localization, spatial reasoning, and downstream retrieval tasks. We find a stable trade-off: detectors such as GroundingDINO and OWLv2 deliver precise boxes with limited relational reasoning, while VLMs like SmolVLM and GPT-4o provide coarse layout cues and fluent captions but struggle with fine-grained spatial context. Our study highlights the gap between localization and true spatial understanding, and pointing toward the need for spatially-aware foundation models in the community.