 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCampaign-2-PT-RAG: LLM-Guided Semantic Product Type Attribution for Scalable Campaign Ranking
Feb 11, 2026E-commerce campaign ranking models require large-scale training labels indicating which users purchased due to campaign influence. However, generating these labels is challenging because campaigns use creative, thematic language that does not directly map to product purchases. Without clear product-level attribution, supervised learning for campaign optimization remains limited. We present \textbf{Campaign-2-PT-RAG}, a scalable label generation framework that constructs user--campaign purchase labels by inferring which product types (PTs) each campaign promotes. The framework first interprets campaign content using large language models (LLMs) to capture implicit intent, then retrieves candidate PTs through semantic search over the platform taxonomy. A structured LLM-based classifier evaluates each PT's relevance, producing a campaign-specific product coverage set. User purchases matching these PTs generate positive training labels for downstream ranking models. This approach reframes the ambiguous attribution problem into a tractable semantic alignment task, enabling scalable and consistent supervision for downstream tasks such as campaign ranking optimization in production e-commerce environments. Experiments on internal and synthetic datasets, validated against expert-annotated campaign--PT mappings, show that our LLM-assisted approach generates high-quality labels with 78--90% precision while maintaining over 99% recall.
Is More Context Always Better? Examining LLM Reasoning Capability for Time Interval Prediction
Jan 15, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning and prediction across different domains. Yet, their ability to infer temporal regularities from structured behavioral data remains underexplored. This paper presents a systematic study investigating whether LLMs can predict time intervals between recurring user actions, such as repeated purchases, and how different levels of contextual information shape their predictive behavior. Using a simple but representative repurchase scenario, we benchmark state-of-the-art LLMs in zero-shot settings against both statistical and machine-learning models. Two key findings emerge. First, while LLMs surpass lightweight statistical baselines, they consistently underperform dedicated machine-learning models, showing their limited ability to capture quantitative temporal structure. Second, although moderate context can improve LLM accuracy, adding further user-level detail degrades performance. These results challenge the assumption that "more context leads to better reasoning". Our study highlights fundamental limitations of today's LLMs in structured temporal inference and offers guidance for designing future context-aware hybrid models that integrate statistical precision with linguistic flexibility.
Composable NLP Workflows for BERT-based Ranking and QA System
Apr 13, 2025



There has been a lot of progress towards building NLP models that scale to multiple tasks. However, real-world systems contain multiple components and it is tedious to handle cross-task interaction with varying levels of text granularity. In this work, we built an end-to-end Ranking and Question-Answering (QA) system using Forte, a toolkit that makes composable NLP pipelines. We utilized state-of-the-art deep learning models such as BERT, RoBERTa in our pipeline, evaluated the performance on MS-MARCO and Covid-19 datasets using metrics such as BLUE, MRR, F1 and compared the results of ranking and QA systems with their corresponding benchmark results. The modular nature of our pipeline and low latency of reranker makes it easy to build complex NLP applications easily.
Unsupervised paradigm for information extraction from transcripts using BERT
Oct 09, 2021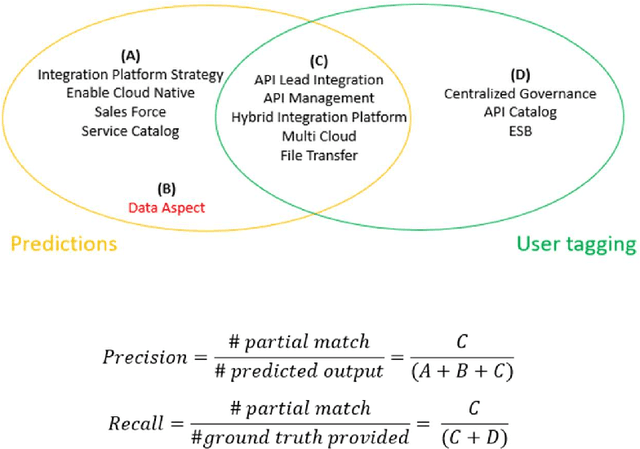
Audio call transcripts are one of the valuable sources of information for multiple downstream use cases such as understanding the voice of the customer and analyzing agent performance. However, these transcripts are noisy in nature and in an industry setting, getting tagged ground truth data is a challenge. In this paper, we present a solution implemented in the industry using BERT Language Models as part of our pipeline to extract key topics and multiple open intents discussed in the call. Another problem statement we looked at was the automatic tagging of transcripts into predefined categories, which traditionally is solved using supervised approach. To overcome the lack of tagged data, all our proposed approaches use unsupervised methods to solve the outlined problems. We evaluate the results by quantitatively comparing the automatically extracted topics, intents and tagged categories with human tagged ground truth and by qualitatively measuring the valuable concepts and intents that are not present in the ground truth. We achieved near human accuracy in extraction of these topics and intents using our novel approach