 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Reasoning in Foundation Models: Benchmarking Object-Centric Spatial Understanding
Sep 26, 2025
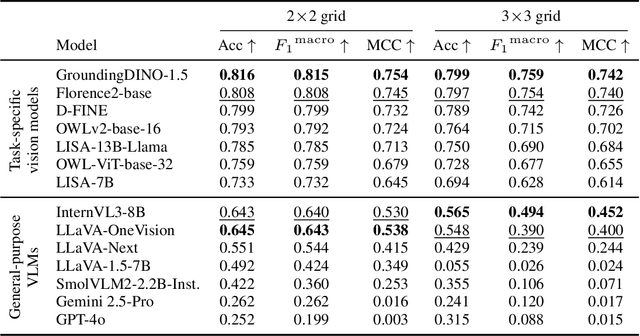

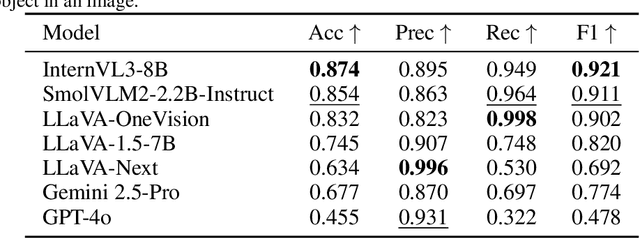
Spatial understanding is a critical capability for vision foundation models. While recent advances in large vision models or vision-language models (VLMs) have expanded recognition capabilities, most benchmarks emphasize localization accuracy rather than whether models capture how objects are arranged and related within a scene. This gap is consequential; effective scene understanding requires not only identifying objects, but reasoning about their relative positions, groupings, and depth. In this paper, we present a systematic benchmark for object-centric spatial reasoning in foundation models. Using a controlled synthetic dataset, we evaluate state-of-the-art vision models (e.g., GroundingDINO, Florence-2, OWLv2) and large VLMs (e.g., InternVL, LLaVA, GPT-4o) across three tasks: spatial localization, spatial reasoning, and downstream retrieval tasks. We find a stable trade-off: detectors such as GroundingDINO and OWLv2 deliver precise boxes with limited relational reasoning, while VLMs like SmolVLM and GPT-4o provide coarse layout cues and fluent captions but struggle with fine-grained spatial context. Our study highlights the gap between localization and true spatial understanding, and pointing toward the need for spatially-aware foundation models in the community.
Embedding based retrieval for long tail search queries in ecommerce
May 03, 2025



In this abstract we present a series of optimizations we performed on the two-tower model architecture [14], training and evaluation datasets to implement semantic product search at Best Buy. Search queries on bestbuy.com follow the pareto distribution whereby a minority of them account for most searches. This leaves us with a long tail of search queries that have low frequency of issuance. The queries in the long tail suffer from very spare interaction signals. Our current work focuses on building a model to serve the long tail queries. We present a series of optimizations we have done to this model to maximize conversion for the purpose of retrieval from the catalog. The first optimization we present is using a large language model to improve the sparsity of conversion signals. The second optimization is pretraining an off-the-shelf transformer-based model on the Best Buy catalog data. The third optimization we present is on the finetuning front. We use query-to-query pairs in addition to query-to-product pairs and combining the above strategies for finetuning the model. We also demonstrate how merging the weights of these finetuned models improves the evaluation metrics. Finally, we provide a recipe for curating an evaluation dataset for continuous monitoring of model performance with human-in-the-loop evaluation. We found that adding this recall mechanism to our current term match-based recall improved conversion by 3% in an online A/B test.
* Published at RecSys '24: Proceedings of the 18th ACM Conference on Recommender Systems